
一般に、本番環境では、Apigee Edge for Private Cloud デプロイメント内でモニタリングのメカニズムを有効にする必要があります。これらのモニタリング技術により、ネットワーク管理者(またはオペレーター)にエラーまたは障害が警告されます。生成されたすべてのエラーは、Apigee Edge でアラートとして報告されます。アラートの詳細については、モニタリングのベスト プラクティスをご覧ください。
Apigee コンポーネントは、主に次の 2 つのカテゴリに分類されます。
- Apigee 固有の Java サーバー サービス: Management Server、Message Processor、Qpid Server、Postgres Server がこれに該当します。
- サードパーティ サービス: Nginx Router、Apache Cassandra、Apache ZooKeeper、SymasLDAP、PostgreSQL データベース、Qpid がこれに該当します。
次の表に、Apigee Edge のオンプレミス デプロイメントでモニタリングできるパラメータの一覧を示します。
| コンポーネント | システム チェック | プロセスレベルの統計 | API レベルのチェック | メッセージ フロー チェック | コンポーネント固有 | |
|---|---|---|---|---|---|---|
|
Apigee 固有の Java サービス |
管理サーバー |
|||||
|
Message Processor |
||||||
|
Qpid Server |
||||||
|
Postgres Server |
||||||
|
サードパーティ サービス |
Apache Cassandra |
|||||
|
Apache ZooKeeper |
||||||
|
SymasLDAP |
||||||
|
PostgreSQL データベース |
||||||
|
Qpid |
||||||
|
Nginx Router |
||||||
一般に、Apigee Edge をインストールした後、以下のモニタリング タスクを実施して Apigee Edge for Private Cloud のパフォーマンスを追跡できます。
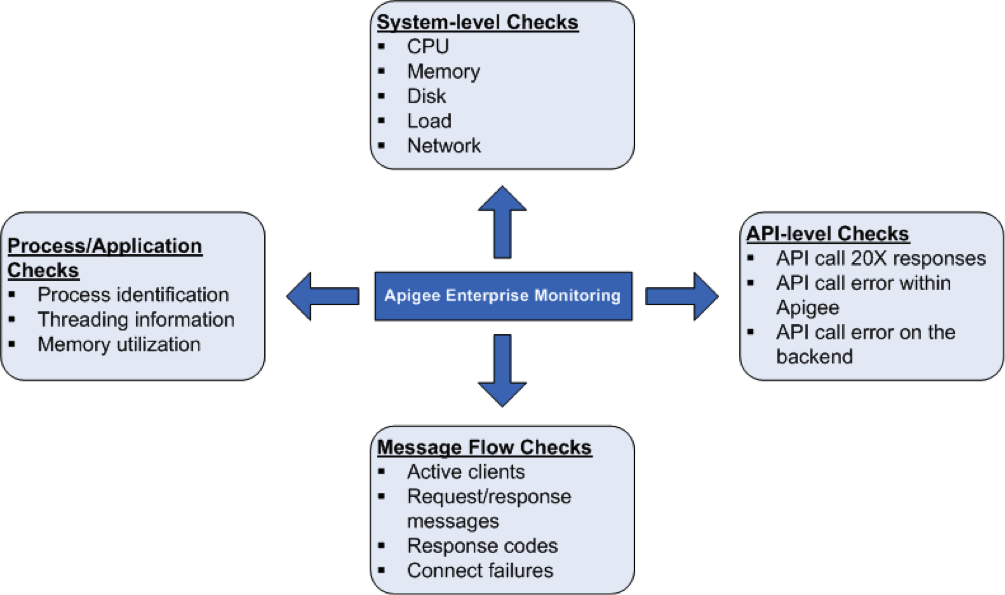
システムヘルス チェック
全体的な CPU 使用率、メモリ使用率、接続性などのシステムヘルス パラメータを測定することは非常に重要です。以下のパラメータをモニタリングすることで、システムヘルスの基礎がわかります。
- CPU 使用率: CPU 使用率に関する基本的な統計情報(ユーザー/システム/入出力待ち/アイドル)を示します。たとえば、システムによって使用されている CPU の総量など。
- 空きメモリ/使用メモリ: システムメモリの使用状況をバイト単位で示します。たとえば、システムによって使用されている物理メモリの量など。
- ディスク使用状況: 現在のディスク使用状況に基づいてファイル システムの情報を示します。たとえば、システムによって使用されているハードディスクの量など。
- 負荷平均: 実行待ちのプロセスの数を示します。
- ネットワーク統計情報: 送受信されたネットワーク パケットまたはバイト数と、特定のコンポーネントに関する伝送エラー。
プロセス/アプリケーション チェック
プロセスレベルでは、実行中のすべてのプロセスに関する重要な情報を表示できます。これには、プロセスまたはアプリケーションが使用するメモリと CPU の使用率の統計情報などが含まれます。Qpid、Postgres Postmaster、Java などのプロセスでは、以下をモニタリングできます。
- プロセス識別: 特定の Apigee プロセスを識別します。たとえば、Apigee サーバーの Java プロセスが存在するかどうかをモニタリングできます。
- スレッド統計情報: プロセスが使用する基盤となるスレッド パターンを表示します。たとえば、すべてのプロセスのピークスレッド数、スレッド数をモニタリングできます。
- メモリ使用率: すべての Apigee プロセスのメモリ使用状況を表示します。たとえば、プロセスによって使用されているヒープメモリやヒープ以外のメモリの使用状況などのパラメータをモニタリングできます。
API レベルのチェック
API レベルでは、Apigee によってプロキシされている使用頻度の高い API 呼び出しに対してサーバーが稼働しているかどうかをモニタリングできます。たとえば、次の curl コマンドを使用して、Management Server、Router、Message Processor に対する API チェックを行うことができます。
curl http://host:port/v1/servers/self/up
ここで、host は Apigee Edge コンポーネントの IP アドレスです。port 番号は Edge コンポーネントによって異なります。次に例を示します。
Management Server: 8080
- Router: 8081
- Message Processor: 8082
- その他
各コンポーネントでこのコマンドを実行する方法については、以下の個別のセクションをご覧ください。
この呼び出しでは、「true」と「false」が返されます。エラーが Apigee ソフトウェア環境内に存在するかバックエンドに存在するかをすばやく判断するために、(Apigee ソフトウェアとやり取りする)バックエンドで直接 API 呼び出しを発行することで、最良の結果を得ることができます。
メッセージ フロー チェック
メッセージ フロー パターン/統計について、Router と Message Processor からデータを収集できます。これにより、以下をモニタリングできます。
- アクティブなクライアントの数
- レスポンスの数(10X、20X、30X、40X、50X)
- 接続の失敗
これは、API メッセージ フローのダッシュボードを提供するのに役立ちます。詳細については、モニタリング方法をご覧ください。
Message Processor の Router ヘルスチェック
Router では、どの Message Processor が期待どおりに動作しているかを判断するヘルスチェックのメカニズムが実装されます。ある Message Processor のダウンまたは処理速度の低下が検出された場合、Router はその Message Processor を自動的にローテーションから外すことができます。その場合は、「Mark Down」というメッセージが Router のログファイル(/opt/apigee/var/log/edge-router/logs/system.log)に書き込まれます。
Router ログファイルでこれらのメッセージをモニタリングできます。たとえば、Router で Message Processor がローテーションから外されると、次の形式のメッセージがログに書き込まれます。
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = MP_IP at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /MP_IP:PORT Mark Down
ここで、MP_IP:PORT は Message Processor の IP アドレスとポート番号です。
後で Router でヘルスチェックが実施されて、Message Processor が正常に機能していると判断されると、Message Processor が自動的にローテーションに戻されます。また、次の形式の「Mark Up」のメッセージがログに書き込まれます。
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = IP at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from IP:PORT Mark Up