
Edge for Private Cloud גרסה 4.17.09
באופן כללי בסביבת ייצור, יש צורך להפעיל מנגנוני מעקב במסגרת Apigee Edge לפריסה של ענן פרטי. שיטות המעקב האלה מזהירות את הרשת אדמינים (או אופרטורים) של שגיאה או כשל. כל שגיאה שנוצרת מדווחת התראה ב-Apigee Edge. מידע נוסף על התראות זמין במאמר שיטות מומלצות למעקב.
כדי להקל על המשתמשים, רכיבי Apigee מסווגים בעיקר לשתי קטגוריות:
- שירותי שרת Java ספציפיים ל-Apigee – כולל ניהול שרת, מעבד הודעות, שרת Qpid ושרת Postgres.
- שירותי צד שלישי – כולל נתב Nginx, Apache Cassandra, ApachezoKeeper, OpenLDAP, מסד נתונים של PostgreSQL ו-Qpid.
בפריסה מקומית של Apigee Edge, הטבלה הבאה מציגה בקצרה אחרי אילו פרמטרים אפשר לעקוב?
|
רכיב |
בדיקות מערכת |
נתונים סטטיסטיים ברמת התהליך |
בדיקות ברמת ה-API |
בדיקות זרימה של ההודעות |
ספציפי לרכיב |
|
|---|---|---|---|---|---|---|
|
שירותי Java ספציפיים ל-Apigee |
שרת ניהול |
? |
? |
? |
||
|
מעבד בקשות |
? |
? |
? |
? |
||
|
שרת Qpid |
? |
? |
? |
|||
|
שרת Postgres |
? |
? |
? |
|||
|
שירותים של צד שלישי |
אפאצ'י קסנדרה |
? |
? |
|||
|
שומר בגן החיות אפאצ'י |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
מסד נתונים של PostgreSQL |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
נתב Nginx |
? |
? |
? |
|||
באופן כללי, לאחר התקנת Apigee Edge, אפשר לבצע את המעקב הבא משימות למעקב אחרי הביצועים של Apigee Edge להתקנת ענן פרטי.
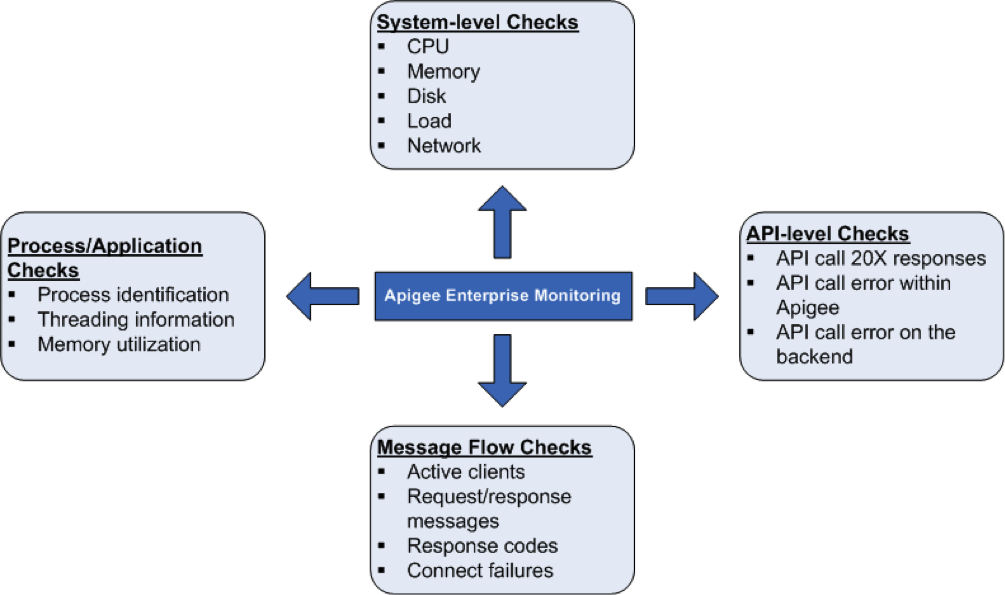
בדיקות תקינות של המערכת
חשוב מאוד למדוד את הפרמטרים של תקינות המערכת, כמו ניצול המעבד (CPU), הזיכרון ניצול וקישוריות ליציאה ברמה גבוהה יותר. אפשר לעקוב אחר הפרמטרים הבאים כדי לקבל את היסודות של תקינות המערכת.
- ניצול המעבד (CPU) – מציין את הנתונים הסטטיסטיים הבסיסיים (משתמש/מערכת/IO המתנה/לא פעילות) לגבי השימוש במעבד. לדוגמה, סך המעבד (CPU) שמשמש את המערכת.
- זיכרון פנוי/משומש – מציין את השימוש בזיכרון המערכת כבייטים. לדוגמה, הזיכרון הפיזי שמשמש את המערכת.
- שימוש בשטח הדיסק – מציין את פרטי מערכת הקבצים על סמך את השימוש הנוכחי בכונן. לדוגמה, נפח האחסון בכונן הקשיח שהמערכת משתמשת בו.
- ממוצע הטעינה – מציין את מספר התהליכים שממתינים עד לרוץ.
- נתוני רשת – חבילות רשת ו/או בייטים שמועברים שהתקבלו, יחד עם שגיאות שידור לגבי רכיב שצוין.
תהליכים/בדיקות אפליקציה
ברמת התהליך, אפשר להציג מידע חשוב על כל התהליכים ריצה. לדוגמה, הנתונים האלה כוללים נתוני שימוש בזיכרון ובמעבד (CPU) שמעבדים או נמצאים באפליקציה משתמשת. בתהליכים כמו qpidd, Postgres postmaster, Java וכו', אפשר לעקוב אחרי הבאים:
- זיהוי תהליכים: זיהוי תהליך ספציפי ב-Apigee. לדוגמה, ניתן לבדוק אם קיים תהליך ג'אווה של שרת Apigee.
- נתונים סטטיסטיים של שרשורים: הצגת דפוסי השרשורים הבסיסיים שמעבדים לשימושים אחרים. לדוגמה, תוכלו לעקוב אחרי שיא השרשורים ומספר השרשורים בכל התהליכים.
- ניצול הזיכרון: הצגת השימוש בזיכרון בכל תהליכי Apigee. לדוגמה, אתם יכולים לעקוב אחרי פרמטרים כמו שימוש בזיכרון ערימה (heap זיכרון) או שימוש בזיכרון שאינו ערימה (heap) שבו נעשה שימוש. בתהליך מסוים.
בדיקות ברמת ה-API
ברמת ה-API אפשר לעקוב אחרי הפעילות של השרת או ה-API שמשתמשים בהם לעיתים קרובות קריאות שנשלחות דרך שרת proxy של Apigee. לדוגמה, אפשר לבצע בדיקת API בשרת הניהול, בנתב, ומעבד הודעות על ידי הפעלה של פקודת ה-cURL הבאה:
curl http://<host>:<port>/v1/servers/self/up
כאשר <host> הוא כתובת ה-IP של רכיב Apigee Edge. התג <port> המספר הוא ספציפי לכל רכיב של Edge. לדוגמה:
שרת ניהול: 8080
- נתב: 8081
- מעבד הודעות: 8082
- וכו'
בהמשך תוכלו למצוא מידע על הרצת הפקודה הזו בכל אחד מהסעיפים הבאים: רכיב
הקריאה מחזירה את הערך "true" ו-"false". לקבלת התוצאות הטובות ביותר, אפשר גם לשלוח קריאות ל-API ישירות בקצה העורפי (שאיתו תוכנת Apigee מקיימת אינטראקציה) כדי לקבוע במהירות האם קיימת שגיאה בסביבת התוכנה של Apigee או בקצה העורפי.
הערה: כדי לעקוב אחרי שרתי ה-proxy ל-API, אפשר גם להשתמש ב-API Health של Apigee. יצרן ה-API Health קריאות מתוזמנות לשרתי proxy ל-API ומודיע לכם מתי הן נכשלות ואיך. כשהשיחות מצליחות, בעזרת API Health תוכלו לראות את זמני התגובה ואפילו להודיע לכם כשזמן האחזור ארוך. API מערכת הבריאות יכולה לבצע קריאות ממקומות שונים ברחבי העולם כדי להשוות בין התנהגות ה-API באזורים שונים.
בדיקות של זרימת הודעות
אפשר לאסוף נתונים מנתבים וממעבדי הודעות לגבי זרימת הודעות דפוס/נתונים סטטיסטיים. כך אתם יכולים לעקוב אחרי הנתונים הבאים:
- מספר הלקוחות הפעילים
- מספר התגובות (10X, 20X, 30X, 40X ו-50X)
- כשלים בחיבור
כך תוכלו לספק מרכזי בקרה לזרימת ההודעות ב-API. מידע נוסף זמין במאמרים הבאים:
- איך עוקבים אחרי מעבד ההודעות
- גרסת הבטא של מרכז הבקרה של Apigee Monitoring סקירה כללית של הנתב
בדיקת תקינות הנתב של מעבד ההודעות
הנתב מיישם מנגנון בדיקת תקינות כדי לקבוע אילו ממעבדי ההודעות פועלות כמצופה. אם יזוהה שמעבד הודעות מושבת או איטי, הנתב יוכל מוציא באופן אוטומטי את מעבד ההודעות מהרוטציה. במקרה כזה, הנתב כותב "Mark Down" הודעות לקובץ היומן של הנתב בכתובת /opt/apigee/var/log/edge-router/logs/system.log.
ניתן לעקוב אחר קובץ היומן של הנתב בשביל ההודעות האלה. לדוגמה, אם הנתב לוקח מעבד ההודעות מחוץ לרוטציה, הוא כותב הודעה ליומן בצורה:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
כאשר /<MP_IP>:<PORT> הוא כתובת ה-IP ומספר היציאה של מעבד ההודעות.
אם בשלב מאוחר יותר הנתב יבצע בדיקת תקינות ויקבע שמעבד ההודעות פועל כראוי, הנתב מחזיר באופן אוטומטי את מעבד ההודעות לסיבוב. הנתב גם כותב "Mark Up" הודעה ליומן בטופס:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up