
Private Cloud v. 4.17.09 版本
一般而言,在正式環境中,您需要在 適用於私有雲部署作業的 Apigee Edge。這些監控技術會警告網路 錯誤或失敗的管理員 (或作業人員)。產生的每個錯誤都會回報為 Apigee Edge 中的快訊如要進一步瞭解快訊,請參閱監控最佳做法。
為了方便起見,Apigee 元件主要分為兩類:
- Apigee 專用的 Java Server 服務 - 包含管理平台 伺服器、訊息處理器、Qpid 伺服器和 Postgres 伺服器。
- 第三方服務 - 包括 Nginx 路由器、Apache Cassandra Apache ZooKeeper、OpenLDAP、PostgreSQL 資料庫和 Qpid。
在 Apigee Edge 的地端部署部署作業中,下表簡要介紹了 您可以使用下列參數監控參數:
|
元件 |
系統檢查 |
程序層級統計資料 |
API 級別檢查 |
郵件流程檢查 |
元件專屬說明 |
|
|---|---|---|---|---|---|---|
|
Apigee 專用的 Java 服務 |
管理伺服器 |
? |
? |
? |
||
|
訊息處理器 |
? |
? |
? |
? |
||
|
Qpid 伺服器 |
? |
? |
? |
|||
|
Postgres 伺服器 |
? |
? |
? |
|||
|
第三方服務 |
Apache Cassandra |
? |
? |
|||
|
Apache ZooKeeper |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
PostgreSQL 資料庫 |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
Nginx 路由器 |
? |
? |
? |
|||
一般來說,安裝 Apigee Edge 後,您可以執行下列監控作業 工作,用於追蹤適用於 Private Cloud 的 Apigee Edge 安裝效能。
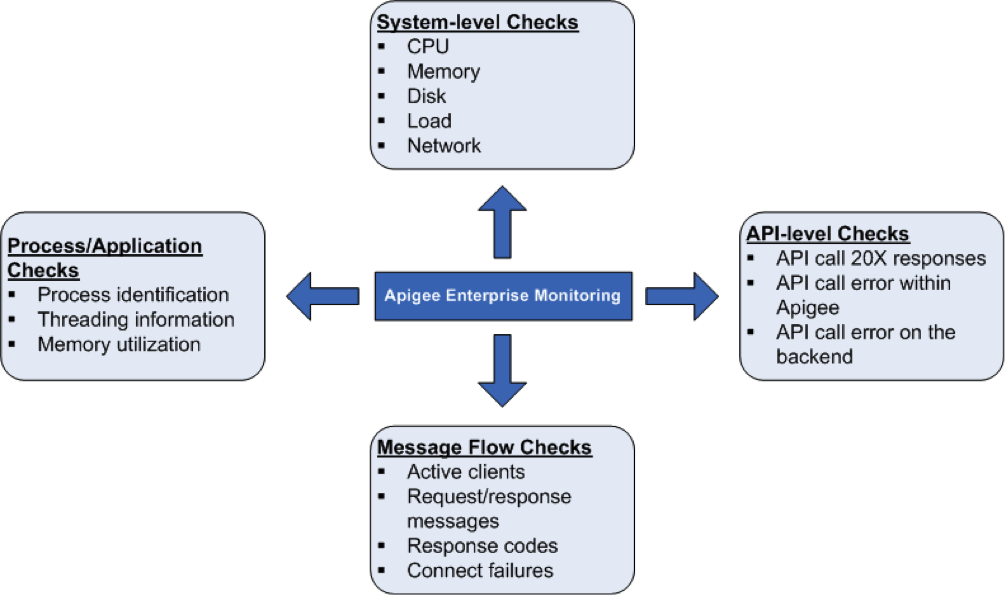
系統健康狀態檢查
衡量 CPU 使用率、記憶體等系統健康狀態參數相當重要 工作負載和通訊埠連線能力您可以監控下列參數, 瞭解系統健康狀態的基本概念
- 「CPU Utilization」:指定基本統計資料 (使用者/系統/IO) 等待/閒置) 關於 CPU 使用率。例如系統使用的 CPU 總數。
- Free/Used Memory – 以位元組形式指定系統記憶體使用率。 例如系統使用的實體記憶體。
- 磁碟空間用量 - 根據下列項目指定檔案系統資訊: 目前的磁碟用量。例如系統使用的硬碟空間。
- 「Load 平均」 – 指定等待程序的 此程序的第一步 是將程式碼簽入執行所有單元測試的存放區中
- 網路統計資料 - 傳輸的網路封包和/或位元組。 以及有關特定元件的傳輸錯誤。
程序/申請檢查
在程序層級,您可以查看有關 備用資源舉例來說,這些資料包括程序或應用程式的記憶體和 CPU 使用統計資料 相關用途以 qpidd、postgres postmaster、java 等等程序來說,您可以監控 包括:
- 程序識別:識別特定 Apigee 程序。例如: 監控功能是否存在 Apigee 伺服器 Java 程序
- 執行緒統計資料:查看處理程序的基礎執行緒模式 使用方式。舉例來說,您可以監控所有程序的尖峰執行緒數量,以及執行緒數量。
- 記憶體使用率:查看所有 Apigee 程序的記憶體用量。 例如,您可以監控堆積記憶體用量、非堆積記憶體用量等參數 透過程序處理
API 層級檢查
您可以在 API 層級監控伺服器是否已啟動且正在執行常用的 API 則由 Apigee 使用 Proxy 處理舉例來說,您可以在管理伺服器、路由器、 叫用以下 cURL 命令來啟動訊息處理器:
curl http://<host>:<port>/v1/servers/self/up
其中 <host> 是 IP Apigee Edge 元件的位址<port>是每個 Edge 元件都有的 例如:
管理伺服器:8080
- 路由器:8081
- 訊息處理器:8082
- 其他
想瞭解如何針對各個 Pod 執行這項指令,請參閱下方的個別章節 化合物
這個呼叫會傳回「true」和「false」為獲得最佳效果,您也可以發出 API 呼叫 直接載入後端 (需與 Apigee 軟體互動) 以快速判斷 錯誤。
注意:如要監控 API Proxy,您也可以使用 Apigee 的 API 健康狀態。API 健康狀態 並會在呼叫失敗時通知您。如果呼叫成功 API Health 會顯示回應時間,甚至會在回應延遲時間過長時通知您。API (應用程式介面) 健康狀態功能可以從世界各地的不同位置呼叫,比較不同 API 行為 區域。
訊息流程檢查
您可以向路由器和訊息處理器收集訊息流程相關資料 模式/統計資料您可以運用這個平台來監控以下項目:
- 有效客戶數量
- 回應數量 (10X、20X、30X、40X 和 50 倍)
- 連線失敗
這有助於提供 API 訊息流程的資訊主頁。若需更多資訊,請參閱:
訊息處理器的路由器健康狀態檢查
路由器會實作健康狀態檢查機制,以判斷哪個訊息處理器 確保運作符合預期如果偵測訊息處理器的速度變慢或速度緩慢,路由器可以 自動將「訊息處理器」的旋轉設定取消旋轉如果發生這種情況,路由器會寫入 「向下標記」傳送至路由器記錄檔的訊息,網址為 /opt/apigee/var/log/edge-router/logs/system.log。
你可以監控這些訊息的路由器記錄檔。舉例來說,如果路由器會使用 訊息處理器未輪替時,會以下列格式將訊息寫入記錄中:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
其中 /<MP_IP>:<PORT> 是 IP 位址和通訊埠編號 即訊息處理者
之後路由器執行健康狀態檢查,並判定訊息處理器 正常運作,路由器會自動將「訊息處理器」移迴旋轉角度。 路由器也會寫入訊息傳送至記錄:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up