
Private Cloud용 Edge v4.18.05
일반적으로 프로덕션 환경에서는 프로젝트 내에서 모니터링 메커니즘을 사용 설정해야 합니다. 프라이빗 클라우드 배포용 Apigee Edge입니다. 이러한 모니터링 기술은 관리자 (또는 운영자)를 식별하는 데 사용됩니다. 생성된 모든 오류는 알림을 받을 수 있습니다 알림에 대한 자세한 내용은 다음을 참조하세요. 모니터링 권장사항.
쉽게 Apigee 구성요소는 크게 두 가지 카테고리로 분류됩니다.
- Apigee 관련 Java 서버 서비스: 관리 등이 포함됩니다. 서버, 메시지 프로세서, Qpid 서버 및 Postgres 서버입니다.
- 서드 파티 서비스: Nginx 라우터, Apache Cassandra, Apache 주키퍼, OpenLDAP, PostgreSQL 데이터베이스, Qpid.
다음 표에서는 Apigee Edge의 온프레미스 배포에서 다음과 같은 매개변수를 모니터링할 수 있습니다.
| 구성요소 | 시스템 점검 | 프로세스 수준 통계 | API 수준 확인 | 메시지 흐름 확인 | 구성요소별 | |
|---|---|---|---|---|---|---|
|
Apigee 관련 Java 서비스 |
관리 서버 |
|||||
|
메시지 프로세서 |
||||||
|
Qpid 서버 |
||||||
|
Postgres 서버 |
||||||
|
서드 파티 서비스 |
Apache Cassandra |
|||||
|
Apache ZooKeeper |
||||||
|
OpenLDAP |
||||||
|
PostgreSQL 데이터베이스 |
||||||
|
Qpid |
||||||
|
Nginx 라우터 |
||||||
일반적으로 Apigee Edge가 설치된 후에는 다음과 같은 모니터링을 수행할 수 있습니다. 태스크를 사용하여 프라이빗 클라우드용 Apigee Edge 설치 성능을 추적할 수 있습니다.
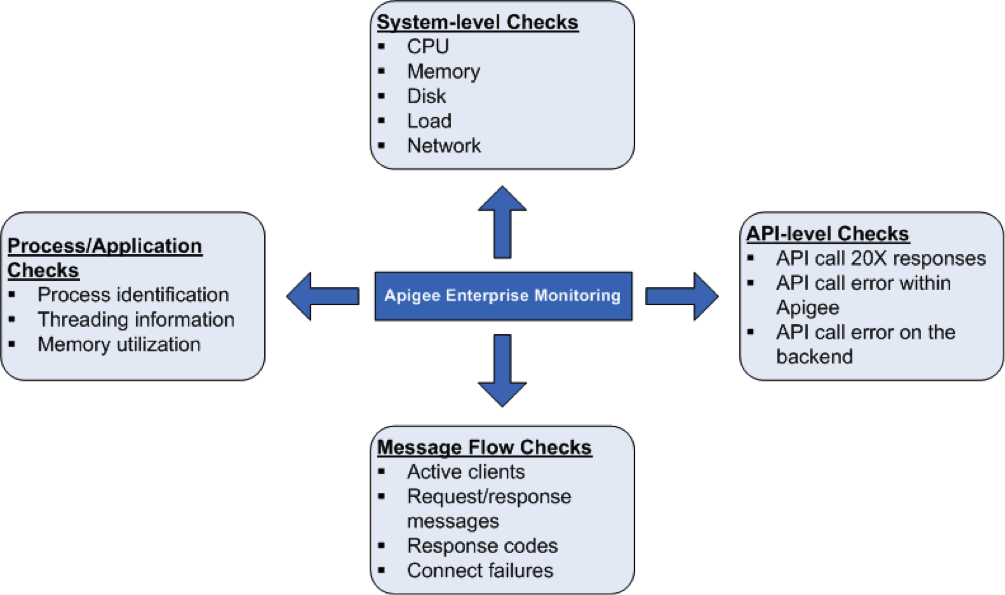
시스템 상태 점검
CPU 사용률, 메모리 및 CPU 사용률과 같은 시스템 상태 매개변수를 포트 연결을 더 높게 설정할 수 있습니다 다음 매개변수를 모니터링하여 시스템 상태의 기본사항을 알아봅니다.
- CPU 사용률: 기본 통계 (사용자/시스템/IO)를 지정합니다. 대기/유휴 상태)를 확인할 수 있습니다. 예를 들어 시스템에서 사용하는 총 CPU가 있습니다.
- 여유/사용된 메모리: 시스템 메모리 사용률을 바이트로 지정합니다. 시스템에서 사용하는 실제 메모리를 예로 들 수 있습니다.
- 디스크 공간 사용량: 파일 시스템 정보를 현재 디스크 사용량을 나타냅니다 예: 시스템에서 사용하는 하드 디스크 공간
- 부하 평균: 실행 대기 중인 프로세스 수를 지정합니다.
- 네트워크 통계: 네트워크 패킷 또는 전송된 바이트 오류 메시지도 함께 표시됩니다.
프로세스/신청서 확인
프로세스 수준에서는 실행 중인 모든 프로세스에 대한 중요한 정보를 있습니다 예를 들어, 여기에는 프로세스 또는 응용 프로그램이 실행되는 메모리 및 CPU 사용 통계가 포함됩니다. 활용할 수 있습니다 qpidd, postgres postmaster, java 등과 같은 프로세스의 경우 있습니다.
- 프로세스 식별: 특정 Apigee 프로세스를 식별합니다. 예를 들어 Apigee 서버 자바 프로세스의 존재를 모니터링할 수 있습니다.
- 스레드 통계: 프로세스가 사용하는 기본 스레딩 패턴을 봅니다. 사용합니다 예를 들어 모든 프로세스의 최대 스레드 수인 스레드 수를 모니터링할 수 있습니다.
- 메모리 사용률: 모든 Apigee 프로세스의 메모리 사용량을 봅니다. 예를 들어, 힙 메모리 사용량, 힙이 아닌 메모리 사용량과 같은 매개변수를 모니터링할 수 있습니다. 처리되도록 합니다.
API 수준 검사
API 수준에서 서버가 자주 사용되는 API에 대해 실행 중인지 여부를 모니터링할 수 있습니다. Apigee에서 프록시한 호출 수를 보여줍니다 예를 들어 관리 서버, 라우터, 및 메시지 프로세서에 연결할 수 있습니다.
curl http://host:port/v1/servers/self/up
여기서 host는 Apigee Edge 구성요소의 IP 주소입니다. port 각 Edge 구성요소에 따라 다릅니다. 예를 들면 다음과 같습니다.
관리 서버: 8080
- 라우터: 8081
- 메시지 프로세서: 8082
- 등
각각에 대해 이 명령어를 실행하는 방법에 대한 자세한 내용은 아래의 개별 섹션을 참조하세요. 성분
이 호출은 'false'입니다. 최상의 결과를 얻으려면 API 호출도 할 수 있습니다. 직접 백엔드 (Apigee 소프트웨어와 상호 작용)에서 직접 호출하여 오류가 Apigee 소프트웨어 환경 내에 있는지 또는 백엔드에 있는지 여부
메시지 흐름 확인
라우터 및 메시지 프로세서로부터 메시지 흐름에 대한 데이터를 수집할 수 있습니다. 데이터를 수집하는 것입니다. 이를 통해 다음을 모니터링할 수 있습니다.
- 활성 클라이언트 수
- 응답 수 (10X, 20X, 30X, 40X, 50X)
- 연결 실패
이를 통해 API 메시지 흐름을 위한 대시보드를 제공할 수 있습니다. 자세한 내용은 다음을 참고하세요. 모니터링 방법.
메시지 프로세서의 라우터 상태 점검
를 탭합니다.
라우터는 상태 점검 메커니즘을 구현하여 어떤 메시지 프로세서를 사용할지 결정합니다.
제대로 작동하는지 확인합니다 메시지 프로세서가 다운되거나 느린 것으로 감지되면, 라우터는
자동으로 메시지 프로세서를 순환에서 제거합니다. 이 경우 라우터는
"마크 다운" 에 있는 라우터 로그 파일에 메시지를
/opt/apigee/var/log/edge-router/logs/system.log
라우터 로그 파일에서 이러한 메시지를 모니터링할 수 있습니다. 예를 들어 라우터가 메시지 프로세서가 순환되지 않고 다음과 같은 형식으로 로그에 메시지를 씁니다.
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = MP_IP at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /MP_IP:PORT Mark Down
여기서 MP_IP:PORT는 메시지 프로세서의 IP 주소와 포트 번호입니다.
나중에 라우터가 상태 점검을 수행하고 메시지 프로세서가 라우터는 자동으로 메시지 프로세서를 교대로 다시 돌립니다. 이 라우터는 또한 'Mark Up' 양식의 로그에 다음 메시지를 추가합니다.
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = IP at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from IP:PORT Mark Up