
ZooKeeper アンサンブルは、サービスが失われても、データが失われることなく機能し続けるように設計されています。 制限します。この復元力を効果的に活用して、VM 上でのメンテナンスを システムのダウンタイムのない ZooKeeper ノード。
ZooKeeper と Edge について
Edge では、ZooKeeper ノードにアプリケーションの場所と構成に関する構成データ 構成の変更をさまざまなコンポーネントに通知します。すべて 本番環境システムでサポートされている Edge トポロジでは、少なくとも 3 つの ZooKeeper を使用する 説明します。
ZK_HOSTS プロパティと ZK_CLIENT_HOSTS プロパティを
ZooKeeper ノードを指定する Edge 構成ファイル。例:
ZK_HOSTS="$IP1 $IP2 $IP3" ZK_CLIENT_HOSTS="$IP1 $IP2 $IP3"
ここで
ZK_HOSTSには、ZooKeeper ノードの IP アドレスを指定します。IP アドレス すべての ZooKeeper ノードで同じ順序で列挙する必要があります。マルチ データセンター環境では、すべてのデータセンターのすべての ZooKeeper ノードを一覧表示します。
ZK_CLIENT_HOSTSには、このリソースで使用する ZooKeeper ノードの IP アドレスを指定します。 データセンターのみ。IP アドレスは、同じリージョン内のすべての ZooKeeper ノードで同じ順序でリストされる必要があります。 データセンターです。単一データセンター環境では、これらのノードは ZK_HOSTS で指定したノードと同じになります。新しい 複数のデータセンターがある場合、各データセンターの Edge 構成ファイルには、 そのデータセンターの ZooKeeper ノード。
デフォルトでは、すべての ZooKeeper ノードがボーターノードとして指定されます。つまり、ノードは
全員が ZooKeeper リーダーの選出に参加します。コメントには、
:observer 修飾子に ZK_HOSTS を付けて、
ノードがボーターではなく、オブザーバー ノードである。オブザーバー ノードは
リーダーの選出
通常は、複数の Edge データを作成するときに :observer 修飾子を指定します。
または、1 つのデータセンターに多数の ZooKeeper ノードがある場合にも使用できます。たとえば、
2 つのデータセンターがある 12 ホストの Edge インストール。データセンター 2 のノード 9 にある ZooKeeper は
オブザーバー:
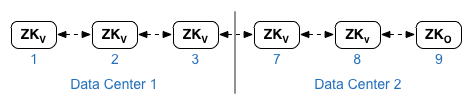
次に、データセンター 1 の構成ファイルで次の設定を使用します。
ZK_HOSTS="$IP1 $IP2 $IP3 $IP7 $IP8 $IP9:observer" ZK_CLIENT_HOSTS="$IP1 $IP2 $IP3"
データセンター 2 の場合:
ZK_HOSTS="$IP1 $IP2 $IP3 $IP7 $IP8 $IP9:observer" ZK_CLIENT_HOSTS="$IP7 $IP8 $IP9"
以降のセクションでは、リーダー、ボーター、 また、ボーターノードとオブザーバー ノードの追加に関する考慮事項についても説明します。
リーダー、フォロワー、 ボーター、オブザーバー
マルチノード ZooKeeper インストールでは、ノードの 1 つがリーダーとして指定されます。 他のすべての ZooKeeper ノードはフォロワーとして指定されます。読み取りはあらゆる場所から ZooKeeper ノードでは、すべての書き込みリクエストがリーダーに転送されます。たとえば、新しいメッセージ プロセッサが Edge に追加されます。この情報は ZooKeeper リーダーに書き込まれます。すべてのフォロワー データを複製します
Edge のインストール時に、各 ZooKeeper ノードをボーターまたはオブザーバーとして指定します。「 リーダーが選出されます。選挙戦で勝利を収めるために 機能している ZooKeeper ボーターノードのクォーラムが利用可能でなければならないという点です。 クォーラムとは、すべてのデータセンターにおける投票者の ZooKeeper ノードの半数以上が 説明します。
使用可能なボーターノードのクォーラムがない場合は、リーダーを選出できません。このシナリオでは Zookeeper はリクエストを処理できません。つまり、エッジ管理サービスに対してリクエストを クォーラムが復元されるまで、Management API リクエストを処理するか、Edge UI にログインします。
たとえば、単一のデータセンター インストールでは次のようになります。
- 3 つの ZooKeeper ノードをインストールしている
- すべての ZooKeeper ノードがボーターである
- クォーラムとは、2 つの機能するボーターノードのことです。
- 使用可能なボーターノードが 1 つしかない場合、ZooKeeper アンサンブルは機能しません。
2 つのデータセンターがあるインストールの場合:
- データセンターごとに 3 つの ZooKeeper ノードをインストールしました。合計 6 つのノードがあります。
- データセンター 1 には 3 つのボーターノードがある
- データセンター 2 には、2 つのボーターノードと 1 つのオブザーバー ノードがある
- クォーラムは両方のデータセンターにわたる 5 人の投票者に基づくため、 3 つの機能しているボーターノード
- 使用可能なボーターノードが 2 つ以下の場合、ZooKeeper アンサンブルは 関数
ノードをボーターまたはボーターとして追加する際の考慮事項 オブザーバー
システム要件によっては、Edge への ZooKeeper ノードの追加が必要になる場合があります。 インストールできます。ZooKeeper ノードの追加ドキュメント で Edge に ZooKeeper ノードを追加する方法について説明します。ZooKeeper ノードを追加する場合、 追加するノードの種類(ボーターまたはオブザーバー)を考慮してください。
1 つ以上のボーターノードがダウンした場合に備え、十分な数のボーターノードを用意する必要があります。 ZooKeeper アンサンブルは引き続き機能するため、ボーターノードのクォーラムが維持される できます。ボーターノードを追加することでクォーラムのサイズが大きくなるため、 投票者ノードのダウンを許容できます
ただし、ボーターノードを追加すると、書き込みパフォーマンスが低下する可能性があります。 オペレーションでは、クォーラムでリーダーについて合意する必要があります。リーダーの決定にかかる時間 ボーターノードの数に基づいており、ボーターノードを追加すると増加します。 そのため、すべてのノードをボーターにすることはおすすめしません。
ボーターノードを追加するのではなく、オブザーバー ノードを追加できます。オブザーバー ノードの追加 リーダー選択のオーバーヘッドを増やさずに、システム全体の読み取りパフォーマンスを オブザーバー ノードは投票せず、クォーラム サイズに影響しません。そのため、オブザーバー ノードが アンサンブルがリーダーを選出できるかどうかに影響はありません。ただし、オブザーバーが 制限されているため、ZooKeeper アンサンブルの読み取りパフォーマンスが低下する データ リクエストに対応できるノードが少なくなります。
Apigee では、単一のデータセンター内のボーターを 5 人以下にすることをおすすめします。 オブザーバーノードの数によって決まります2 つのデータセンターでは、 9 人(1 つのデータセンターに 5 人、もう一つのデータセンターに 4 人)を上回っています。あとはいくつでも オブザーバー ノードを指定します。
Zookeeper ノードを削除する
Zookeeper ノードの削除が必要になる理由はさまざまです。たとえば、あるノードが 間違った環境に追加された可能性があります。
このセクションでは、Zookeeper ノードがダウンしていて、かつノードが停止しているときに削除する方法について説明します。 到達できません。
Zookeeper ノードを削除するには:
- サイレント構成ファイルを編集して、作成した Zookeeper ノードの IP アドレスを削除します。 選択します。
- Zookeeper の
setupコマンドを再実行して、残りの ZooKeeper を再構成します。 ノード:/opt/apigee/apigee-service/bin/apigee-service apigee-zookeeper setup -f updated_config_file
- すべての Zookeeper ノードを再起動します。
/opt/apigee/apigee-service/bin/apigee-service apigee-zookeeper restart
- Management Server ノードを再構成します。
/opt/apigee/apigee-service/bin/apigee-service edge-management-server setup -f updated_config_file
/opt/apigee/apigee-service/bin/apigee-service edge-management-server restart - すべての Router を再構成します。
/opt/apigee/apigee-service/bin/apigee-service edge-router setup -f updated_config_file
/opt/apigee/apigee-service/bin/apigee-service edge-router restart - すべての Message Processor を再構成します。
/opt/apigee/apigee-service/bin/apigee-service edge-message-processor setup -f updated_config_file
/opt/apigee/apigee-service/bin/apigee-service edge-message-processor restart - すべての Qpid ノードを再構成します。
/opt/apigee/apigee-service/bin/apigee-service edge-qpid-server setup -f updated_config_file
/opt/apigee/apigee-service/bin/apigee-service edge-qpid-server restart - すべての Postgres ノードを再構成します。
/opt/apigee/apigee-service/bin/apigee-service edge-postgres-server setup -f updated_config_file
/opt/apigee/apigee-service/bin/apigee-service edge-postgres-server restart
メンテナンスに関する考慮事項
次の条件に該当する場合、完全に機能するアンサンブルでダウンタイムなしで ZooKeeper メンテナンスを実行できます。 一度に 1 つのノードで実行したからですダウンしている ZooKeeper ノードが 1 つだけであることを 投票者ノードのクォーラムを常時確保して、 います。
メンテナンス全体 複数のデータセンターを
複数のデータセンターを使用する場合、ZooKeeper アンサンブルは データセンターを区別します。ZooKeeper アセンブリは、すべての ZooKeeper ノードを表示します。 複数のデータセンターを 1 つのアンサンブルとして 統合できます
特定のデータセンター内のボーターノードの場所は、ZooKeeper を実行する際に考慮されない クォーラム計算を行います。クォーラムが満たされている限り、データセンター全体で個々のノードがダウンしても アンサンブル全体で維持されるため、ZooKeeper は引き続き機能します。
メンテナンスへの影響
メンテナンスのために ZooKeeper ノードを停止しなければならない場合があります。 オブザーバー ノードを指定できます。たとえば、ノード上の Edge のバージョンのアップグレード、 ZooKeeper をホストしているマシンで障害が発生するか、そのノードが他のいくつかの ネットワーク エラーなどの理由です。
停止するノードがオブザーバー ノードの場合、 ノードが復旧するまで ZooKeeper アンサンブルのパフォーマンスを維持します。ノードがボーターの場合 アクセス元のノードが失われ、ZooKeeper アンサンブルの実行可能性に影響する リーダー選出プロセスに参加します。投票者ノードが離脱する理由が 使用可能なボーターノードのクォーラムを維持することが重要です。
メンテナンス手順
メンテナンス手順は、ZooKeeper でサービスが アンサンブルは機能的ですこれは、オブザーバー ノードが機能していて、十分な数のノードがあることを前提としています。 クォーラムを維持するために、メンテナンス中に使用可能なボーターノードの数が必要です。
これらの条件が満たされると、任意のサイズの ZooKeeper アンサンブルで データ損失やパフォーマンスへの重大な影響なしに、この これは、アンサンブルのどのノードでも、1 つのノード上にある限り、自由にメンテナンスを実施できることを意味します。 適用できます。
メンテナンスを実施する際は、以下の手順でインフラストラクチャのタイプを ZooKeeper ノード(リーダー、ボーター、オブザーバー):
- ZooKeeper ノードにインストールされていない場合は、
ncをインストールします。sudo yum install nc
- ノードで次の
ncコマンドを実行します。ここで、2181 は ZooKeeper ポートです。echo stat | nc localhost 2181
次のような出力が表示されます。
Zookeeper version: 3.4.5-1392090, built on 09/30/2012 17:52 GMT Clients: /a.b.c.d:xxxx[0](queued=0,recved=1,sent=0) Latency min/avg/max: 0/0/0 Received: 1 Sent: 0 Connections: 1 Outstanding: 0 Zxid: 0xc00000044 Mode: follower Node count: 653
ノードの出力の
Mode行にobserverが表示されます。leaderまたはfollower(リーダーではない投票者) ノード構成に応じて異なります。 - ZooKeeper ノードごとに手順 1 と 2 を繰り返します。
概要
ZooKeeper アンサンブルのメンテナンスを行う最善の方法は、1 つのノードで 1 つのノードを実行することです。 あります。注意事項:
- ZooKeeper が確実に実行されるよう、メンテナンス中もボーターノードのクォーラムを維持する必要があります。 アンサンブルが機能します
- オブザーバー ノードを停止しても、クォーラムやリーダーの選出機能には影響しません。
- クォーラムは、すべてのデータセンターのすべての ZooKeeper ノード間で計算されます。
- 前のサーバーが稼働状態になったら、次のサーバーのメンテナンスに進みます。
ncコマンドを使用して ZooKeeper ノードを検査します。