
W konfiguracji produkcyjnej należy zwykle włączyć mechanizmy monitorowania w ramach wdrożenia Apigee Edge dla chmury prywatnej. Te techniki monitorowania ostrzegają administratorów (lub operatorów) sieci o błędzie lub awarii. Każdy wygenerowany błąd jest zgłaszany jako alert w Apigee Edge. Więcej informacji o alertach znajdziesz w artykule Sprawdzone metody monitorowania.
Komponenty Apigee są podzielone głównie na 2 kategorie:
- Usługi serwera Java specyficzne dla Apigee: obejmują serwer zarządzania, procesor wiadomości, serwer Qpid i serwer Postgres.
- Usługi innych firm: obejmują router Nginx, Apache Cassandra, Apache ZooKeeper, SymasLDAP, bazę danych PostgreSQL i Qpid.
W przypadku wdrożenia lokalnego Apigee Edge w tabeli poniżej znajdziesz szybki przegląd parametrów, które możesz monitorować:
| Komponent | Sprawdzanie systemu | Statystyki na poziomie procesu | Sprawdzanie poziomu interfejsu API | Sprawdzanie przepływu wiadomości | Specyficzne dla komponentu | |
|---|---|---|---|---|---|---|
|
Usługi Java specyficzne dla Apigee |
Serwer zarządzania |
|||||
|
procesor komunikatów |
||||||
|
Serwer Qpid |
||||||
|
Serwer Postgres |
||||||
|
Usługi innych firm |
Apache Cassandra |
|||||
|
Apache ZooKeeper |
||||||
|
SymasLDAP |
||||||
|
Baza danych PostgreSQL |
||||||
|
Qpid |
||||||
|
Router Nginx |
||||||
Po zainstalowaniu Apigee Edge możesz wykonywać te czynności związane z monitorowaniem, aby śledzić wydajność instalacji Apigee Edge for Private Cloud.
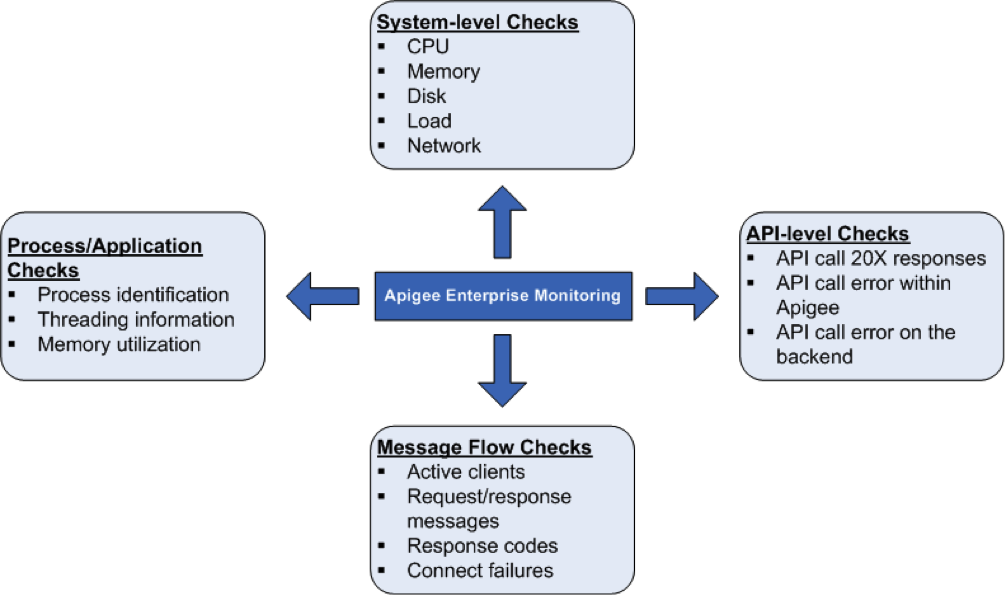
Kontrole stanu systemu
Bardzo ważne jest mierzenie parametrów stanu systemu, takich jak wykorzystanie procesora, pamięci i łączność portów na wyższym poziomie. Aby poznać podstawowe informacje o stanie systemu, możesz monitorować te parametry:
- Wykorzystanie procesora: określa podstawowe statystyki (użytkownik/system/oczekiwanie na wejście/wyjście/bezczynność) dotyczące wykorzystania procesora. Na przykład łączne wykorzystanie procesora przez system.
- Wolna/używana pamięć: określa wykorzystanie pamięci systemowej w bajtach. Na przykład pamięć fizyczna używana przez system.
- Użycie miejsca na dysku: określa informacje o systemie plików na podstawie bieżącego użycia dysku. Na przykład miejsce na dysku twardym zajęte przez system.
- Średnie obciążenie: określa liczbę procesów oczekujących na uruchomienie.
- Statystyki sieci: pakiety sieciowe lub bajty wysłane i odebrane wraz z błędami transmisji dotyczącymi określonego komponentu.
Procesy i weryfikacje aplikacji
Na poziomie procesu możesz wyświetlić ważne informacje o wszystkich uruchomionych procesach. Obejmują one na przykład statystyki wykorzystania pamięci i procesora przez proces lub aplikację. W przypadku procesów takich jak Qpid, Postgres Postmaster czy Java możesz monitorować te elementy:
- Identyfikacja procesu: identyfikowanie konkretnego procesu Apigee. Możesz na przykład monitorować istnienie procesu Java serwera Apigee.
- Statystyki wątków: wyświetl wzorce wątków, których używa proces. Możesz na przykład monitorować maksymalną liczbę wątków i liczbę wątków we wszystkich procesach.
- Wykorzystanie pamięci: wyświetl wykorzystanie pamięci przez wszystkie procesy Apigee. Możesz na przykład monitorować parametry takie jak użycie pamięci sterty i pamięci niesterty przez proces.
Sprawdzanie na poziomie interfejsu API
Na poziomie interfejsu API możesz monitorować, czy serwer jest włączony i działa w przypadku często używanych wywołań interfejsu API przekazywanych przez Apigee. Możesz na przykład przeprowadzić sprawdzanie interfejsu API na serwerze zarządzającym, routerze i procesorze wiadomości, wywołując to polecenie curl:
curl http://host:port/v1/servers/self/up
gdzie host to adres IP komponentu Apigee Edge. Numer port jest przypisany do każdego komponentu Edge. Na przykład:
Serwer zarządzania: 8080
- Router: 8081
- Procesor komunikatów: 8082
- itd.
Informacje o uruchamianiu tego polecenia w przypadku poszczególnych komponentów znajdziesz w sekcjach poniżej.
To wywołanie zwraca wartości „true” i „false”. Aby uzyskać najlepsze wyniki, możesz też wysyłać wywołania interfejsu API bezpośrednio na backendzie (z którym wchodzi w interakcję oprogramowanie Apigee), aby szybko określić, czy błąd występuje w środowisku oprogramowania Apigee, czy na backendzie.
Sprawdzanie przepływu wiadomości
Możesz zbierać dane z routerów i procesorów wiadomości dotyczące wzorców/statystyk przepływu wiadomości. Dzięki temu możesz monitorować:
- Liczba aktywnych klientów
- Liczba odpowiedzi (10X, 20X, 30X, 40X i 50X)
- Błędy połączenia
Ułatwia to tworzenie paneli do monitorowania przepływu wiadomości API. Więcej informacji znajdziesz w artykule Jak monitorować.
Kontrola stanu routera procesora wiadomości
Router implementuje mechanizm kontroli stanu, aby określić, które procesory wiadomości działają zgodnie z oczekiwaniami. Jeśli procesor wiadomości zostanie wykryty jako niedostępny lub powolny, router może automatycznie wyłączyć go z rotacji. W takim przypadku router zapisuje w pliku dziennika routera w lokalizacji /opt/apigee/var/log/edge-router/logs/system.log wiadomości „Mark Down”.
Możesz monitorować plik dziennika routera pod kątem tych komunikatów. Jeśli na przykład Router wyłączy z rotacji Procesor wiadomości, zapisze w dzienniku wiadomość w formacie:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = MP_IP at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /MP_IP:PORT Mark Down
gdzie MP_IP:PORT to adres IP i numer portu procesora wiadomości.
Jeśli później router przeprowadzi kontrolę stanu i stwierdzi, że procesor wiadomości działa prawidłowo, automatycznie przywróci go do puli. Router zapisuje też w dzienniku wiadomość „Mark Up” w formacie:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = IP at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from IP:PORT Mark Up