
Edge for Private Cloud versione 4.17.05
In genere, in una configurazione di produzione è necessario attivare i meccanismi di monitoraggio all'interno di un deployment di Apigee Edge for Private Cloud. Queste tecniche di monitoraggio avvisano gli amministratori (o gli operatori) della rete di un errore o di un malfunzionamento. Ogni errore generato viene segnalato come avviso in Apigee Edge. Per ulteriori informazioni sugli avvisi, consulta le best practice per il monitoraggio.
Per praticità, i componenti Apigee sono classificati principalmente in due categorie:
- Servizi Java Server specifici di Apigee: tra cui Management Server, Message Processor, Qpid Server e Postgres Server.
- Servizi di terze parti: tra cui Nginx Router, Apache Cassandra, Apache ZooKeeper, OpenLDAP, database PostgreSQL e Qpid.
In un deployment on-premise di Apigee Edge, la tabella seguente fornisce un rapido riepilogo dei parametri che puoi monitorare:
|
Componente |
Controlli di sistema |
Statistiche a livello di processo |
Controlli a livello di API |
Controlli del flusso dei messaggi |
Specifico per componente |
|
|---|---|---|---|---|---|---|
|
Servizi Java specifici di Apigee |
Server di gestione |
? |
? |
? |
||
|
processore di messaggi |
? |
? |
? |
? |
||
|
Qpid Server |
? |
? |
? |
|||
|
Server Postgres |
? |
? |
? |
|||
|
Servizi di terze parti |
Apache Cassandra |
? |
? |
|||
|
Apache ZooKeeper |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
Database PostgreSQL |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
Router Nginx |
? |
? |
? |
|||
In generale, dopo aver installato Apigee Edge, puoi eseguire le seguenti attività di monitoraggio per monitorare il rendimento di un'installazione di Apigee Edge for Private Cloud.
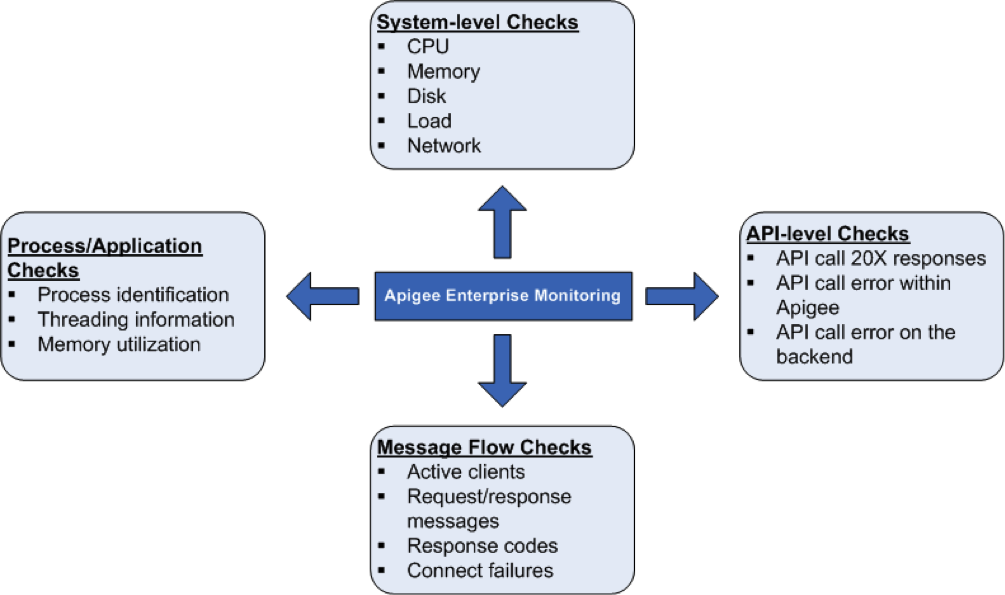
Controlli di integrità del sistema
È molto importante misurare i parametri di integrità del sistema, come l'utilizzo della CPU, l'utilizzo della memoria e la connettività delle porte, a un livello superiore. Puoi monitorare i seguenti parametri per avere informazioni di base sullo stato del sistema.
- Utilizzo CPU: specifica le statistiche di base (utente/sistema/IO in attesa/inattivo) sull'utilizzo della CPU. Ad esempio, la CPU totale utilizzata dal sistema.
- Memoria libera/utilizzata: specifica l'utilizzo della memoria di sistema in byte. Ad esempio, la memoria fisica utilizzata dal sistema.
- Utilizzo spazio su disco: specifica le informazioni sul file system in base all'utilizzo corrente del disco. Ad esempio, lo spazio sul disco rigido utilizzato dal sistema.
- Carico medio: specifica il numero di processi in attesa di essere eseguiti.
- Statistiche di rete: pacchetti e/o byte di rete trasmessi e ricevuti, nonché gli errori di trasmissione relativi a un componente specificato.
Controlli di processi/applicazioni
A livello di processo, puoi visualizzare informazioni importanti su tutti i processi in esecuzione. Ad esempio, sono incluse le statistiche sull'utilizzo della memoria e della CPU utilizzate da un processo o da un'applicazione. Per processi come qpidd, postgres postmaster, java e così via, puoi monitorare quanto segue:
- Identificazione del processo: identifica un determinato processo Apigee. Ad esempio, puoi monitorare l'esistenza di un processo Java del server Apigee.
- Statistiche thread: visualizza i pattern di threading sottostanti utilizzati da un processo. Ad esempio, puoi monitorare il numero di thread di picco e il numero di thread per tutti i processi.
- Utilizzo della memoria: visualizza l'utilizzo della memoria per tutti i processi Apigee. Ad esempio, puoi monitorare parametri come l'utilizzo della memoria heap e l'utilizzo della memoria non heap impiegato da un processo.
Controlli a livello di API
A livello di API, puoi monitorare se il server è attivo e funzionante per le chiamate API di uso frequente con proxy di Apigee. Ad esempio, puoi eseguire il controllo dell'API sul server di gestione, sul router e sul gestore dei messaggi richiamando il seguente comando cURL:
curl http://<host>:<port>/v1/servers/self/up
dove <host> è l'indirizzo IP del componente Apigee Edge. Il numero <port> è specifico per ogni componente Edge. Ad esempio:
Server di gestione: 8080
- Router: 8081
- Message Processor: 8082
- e così via
Consulta le singole sezioni di seguito per informazioni sull'esecuzione di questo comando per ciascun componente.
Questa chiamata restituisce "true" e "false". Per risultati ottimali, puoi anche eseguire chiamate API direttamente sul backend (con cui interagisce il software Apigee) per determinare rapidamente se esiste un errore nell'ambiente software Apigee o nel backend.
Nota: per monitorare i proxy API, puoi anche utilizzare lo stato dell'API di Apigee. Lo stato dell'API effettua chiamate programmate ai proxy API e ti avvisa quando non vanno a buon fine e in che modo. Quando le chiamate vanno a buon fine, lo stato dell'API mostra i tempi di risposta e può persino inviarti una notifica quando la latenza di risposta è elevata. API Health può effettuare chiamate da diverse località in tutto il mondo per confrontare il comportamento delle API tra le regioni.
Controlli del flusso dei messaggi
Puoi raccogliere dati da router e processori di messaggi relativi a pattern/statistiche sul flusso di messaggi. In questo modo puoi monitorare quanto segue:
- Numero di client attivi
- Numero di risposte (10X, 20X, 30X, 40X e 50X)
- Errori di connessione
In questo modo puoi fornire dashboard per il flusso di messaggi dell'API. Per saperne di più, consulta:
- Istruzioni per il monitoraggio del processore di messaggi
- Panoramica della dashboard di monitoraggio Apigee beta per il router
Controllo di integrità del router del processore di messaggi
Il router implementa un meccanismo di controllo di integrità per determinare quali elaboratori di messaggi funzionano come previsto. Se un elaboratore di messaggi viene rilevato come inattivo o lento, il router può ritirarlo automaticamente dalla rotazione. In questo caso, il router scrive un messaggio "Mark Down" nel file di log del router in /opt/apigee/var/log/edge-router/logs/system.log.
Puoi monitorare il file del log del router per rilevare questi messaggi. Ad esempio, se il router rimuove un elaboratore di messaggi dalla rotazione, scrive il messaggio nel log nel seguente formato:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
dove /<MP_IP>:<PORT> è l'indirizzo IP e il numero di porta del processore di messaggi.
Se in un secondo momento il router esegue un controllo di integrità e determina che il Message Processor funziona correttamente, lo inserisce automaticamente di nuovo nella rotazione. Il router scrive anche un messaggio "Mark Up" nel log nel seguente formato:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up