
به طور کلی در یک راهاندازی تولید، نیاز به فعال کردن مکانیسمهای نظارت در یک Apigee Edge برای استقرار Private Cloud وجود دارد. این تکنیک های نظارت به مدیران شبکه (یا اپراتورها) در مورد خطا یا شکست هشدار می دهد. هر خطای ایجاد شده به عنوان یک هشدار در Apigee Edge گزارش می شود. برای کسب اطلاعات بیشتر در مورد هشدارها، به بهترین روشهای نظارت مراجعه کنید.
برای سهولت، اجزای Apigee عمدتا به دو دسته طبقه بندی می شوند:
- خدمات سرور جاوا مخصوص Apigee: این خدمات عبارتند از مدیریت سرور، پردازشگر پیام، سرور Qpid و سرور Postgres.
- خدمات شخص ثالث: این خدمات عبارتند از Nginx Router، Apache Cassandra، Apache ZooKeeper، OpenLDAP، پایگاه داده PostgreSQL و Qpid.
در یک استقرار در محل Apigee Edge، جدول زیر نگاهی گذرا به پارامترهایی که میتوانید نظارت کنید ارائه میکند:
| جزء | چک های سیستم | آمار در سطح فرآیند | بررسی های سطح API | بررسی جریان پیام | کامپوننت خاص | |
|---|---|---|---|---|---|---|
خدمات جاوا مخصوص Apigee | سرور مدیریت | |||||
پردازشگر پیام | ||||||
سرور Qpid | ||||||
سرور Postgres | ||||||
خدمات شخص ثالث | آپاچی کاساندرا | |||||
Apache ZooKeeper | ||||||
OpenLDAP | ||||||
پایگاه داده PostgreSQL | ||||||
Qpid | ||||||
روتر Nginx | ||||||
به طور کلی، پس از نصب Apigee Edge، میتوانید وظایف نظارتی زیر را برای ردیابی عملکرد Apigee Edge برای نصب ابر خصوصی انجام دهید.
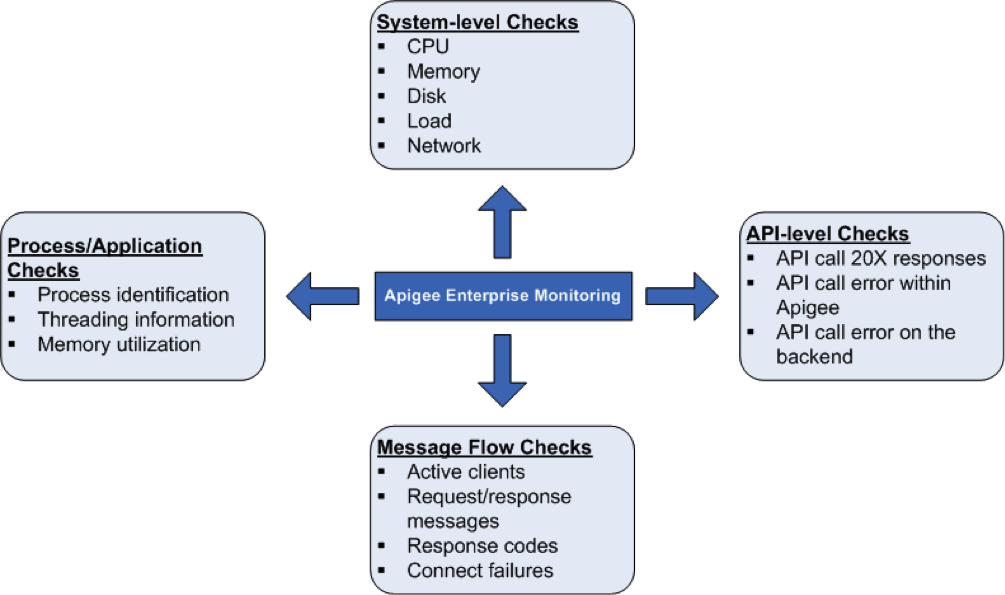
بررسی سلامت سیستم
اندازه گیری پارامترهای سلامت سیستم مانند استفاده از CPU، استفاده از حافظه و اتصال پورت در سطح بالاتر بسیار مهم است. برای دریافت اصول اولیه سلامت سیستم می توانید پارامترهای زیر را کنترل کنید.
- CPU Utilization: آمار اولیه (User/System/IO Wait/Idle) در مورد استفاده از CPU را مشخص می کند. به عنوان مثال، کل CPU استفاده شده توسط سیستم.
- حافظه آزاد/استفاده شده: میزان استفاده از حافظه سیستم را به صورت بایت مشخص می کند. به عنوان مثال، حافظه فیزیکی مورد استفاده توسط سیستم.
- Disk Space Usage: اطلاعات سیستم فایل را بر اساس میزان مصرف فعلی دیسک مشخص می کند. به عنوان مثال فضای هارد دیسک مورد استفاده سیستم.
- Load Average: تعداد فرآیندهایی که منتظر اجرا هستند را مشخص می کند.
- آمار شبکه: بستهها و/یا بایتهای شبکه ارسال و دریافت میشوند، همراه با خطاهای انتقال در مورد یک جزء مشخص.
فرآیندها/بررسی برنامه ها
در سطح فرآیند، می توانید اطلاعات مهم در مورد تمام فرآیندهایی که در حال اجرا هستند را مشاهده کنید. به عنوان مثال، اینها شامل آمار مصرف حافظه و CPU است که یک فرآیند یا برنامه از آن استفاده می کند. برای فرآیندهایی مانند qpidd، postgres postmaster، java و غیره، می توانید موارد زیر را نظارت کنید:
- شناسایی فرآیند : یک فرآیند Apigee خاص را شناسایی کنید. به عنوان مثال، شما می توانید برای وجود فرآیند جاوا سرور Apigee نظارت کنید.
- آمار رشته : الگوهای رشتهبندی زیرینی را که یک فرآیند استفاده میکند، مشاهده کنید. به عنوان مثال، شما می توانید پیک تعداد رشته ها، تعداد رشته ها را برای همه فرآیندها نظارت کنید.
- استفاده از حافظه : میزان استفاده از حافظه را برای تمام فرآیندهای Apigee مشاهده کنید. به عنوان مثال، می توانید پارامترهایی مانند استفاده از حافظه پشته، استفاده از حافظه غیرهپ که توسط یک فرآیند استفاده می شود را نظارت کنید.
بررسی های سطح API
در سطح API، میتوانید نظارت کنید که آیا یک سرور برای تماسهای API پرکاربرد که توسط Apigee پراکسی میشوند، آماده و اجرا میشود. به عنوان مثال، میتوانید API را روی سرور مدیریت، روتر و پردازشگر پیام با فراخوانی دستور curl زیر انجام دهید:
curl http://host:port/v1/servers/self/up
جایی که host آدرس IP جزء Apigee Edge است. شماره port مخصوص هر جزء Edge است. به عنوان مثال:
سرور مدیریت: 8080
- روتر: 8081
- پردازشگر پیام: 8082
- و غیره
برای اطلاعات در مورد اجرای این دستور برای هر مؤلفه به بخش های جداگانه زیر مراجعه کنید
این فراخوان "درست" و "نادرست" را برمی گرداند. برای بهترین نتایج، میتوانید تماسهای API را مستقیماً در بکاند (که نرمافزار Apigee با آن تعامل دارد) صادر کنید تا به سرعت تشخیص دهید که آیا خطا در محیط نرمافزار Apigee یا در باطن وجود دارد یا خیر.
بررسی جریان پیام
شما می توانید داده هایی را از مسیریاب ها و پردازشگرهای پیام در مورد الگوی/آمار جریان پیام جمع آوری کنید. این به شما امکان می دهد موارد زیر را نظارت کنید:
- تعداد مشتریان فعال
- تعداد پاسخ ها (10X، 20X، 30X، 40X و 50X)
- اتصال خرابی ها
این به شما کمک می کند تا داشبوردهایی را برای جریان پیام API تهیه کنید. برای اطلاعات بیشتر، نحوه نظارت را ببینید.
بررسی سلامت روتر پردازشگر پیام
روتر یک مکانیسم بررسی سلامت را برای تعیین اینکه کدام یک از پردازشگرهای پیام همانطور که انتظار می رود کار می کنند پیاده سازی می کند. اگر پردازشگر پیام ضعیف یا کند تشخیص داده شود، روتر می تواند به طور خودکار پردازشگر پیام را از چرخش خارج کند. اگر این اتفاق بیفتد، روتر پیامهای "Mark Down" را در فایل گزارش روتر در /opt/apigee/var/log/edge-router/logs/system.log مینویسد.
شما می توانید فایل گزارش روتر را برای این پیام ها نظارت کنید. به عنوان مثال، اگر روتر یک پردازشگر پیام را از چرخش خارج کند، پیامی را در گزارش به شکل زیر می نویسد:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = MP_IP at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /MP_IP:PORT Mark Down
جایی که MP_IP:PORT آدرس IP و شماره پورت پردازشگر پیام است.
اگر بعداً روتر یک بررسی سلامتی انجام دهد و تشخیص دهد که پردازشگر پیام به درستی کار می کند، روتر به طور خودکار پردازشگر پیام را دوباره به چرخش در می آورد. روتر همچنین یک پیام "Mark Up" به گزارش به شکل زیر می نویسد:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = IP at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from IP:PORT Mark Up