
一般に、本番環境の設定では、1 つのプロジェクト内でモニタリング メカニズムを有効にする必要があります。 Apigee Edge for Private Cloud のデプロイ。これらの監視手法によって、ネットワーク 管理者(またはオペレーター)が、エラーや障害の責任を負います。生成されたすべてのエラーは、 Apigee Edge でアラートを確認できます。アラートの詳細については、モニタリングのベスト プラクティスをご覧ください。
Apigee のコンポーネントは、主に次の 2 つのカテゴリに分類されます。
- Apigee 固有の Java サーバー サービス: これには、管理が含まれます。 Server、Message Processor、Qpid Server、Postgres Server です。
- サードパーティのサービス: Nginx Router、Apache Cassandra、 Apache ZooKeeper、OpenLDAP、PostgreSQL データベース、Qpid です。
次の表に、Apigee Edge のオンプレミス デプロイにおける モニタリングできるパラメータは次のとおりです。
| コンポーネント | システム チェック | プロセスレベルの統計 | API レベルのチェック | メッセージ フロー チェック | コンポーネント固有 | |
|---|---|---|---|---|---|---|
|
Apigee 固有の Java サービス |
管理サーバー |
|||||
|
Message Processor |
||||||
|
Qpid サーバー |
||||||
|
Postgres サーバー |
||||||
|
サードパーティのサービス |
Apache Cassandra |
|||||
|
Apache ZooKeeper |
||||||
|
OpenLDAP |
||||||
|
PostgreSQL データベース |
||||||
|
Qpid |
||||||
|
Nginx ルーター |
||||||
一般に、Apigee Edge をインストールした後、次のモニタリングを実行できます。 Apigee Edge for Private Cloud インストールのパフォーマンスを追跡できます。
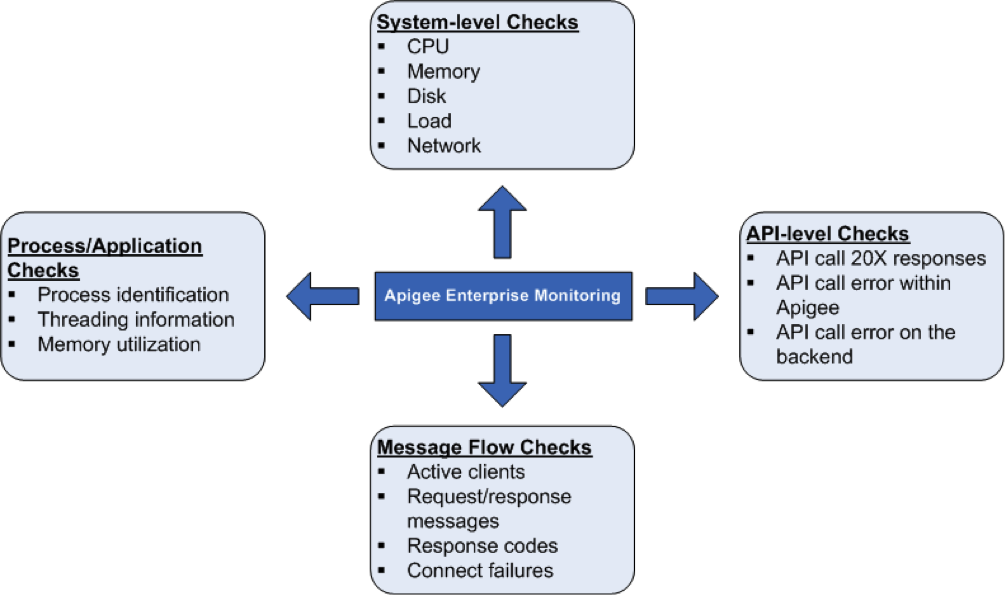
システムのヘルスチェック
CPU 使用率、メモリ、メモリなど、システムの健全性パラメータを測定することが ポート接続の上位レベルでモニタリングできます。次のパラメータをモニタリングして、 システムの健全性の基本を把握します。
- CPU 使用率: 基本的な統計情報(ユーザー / システム / I/O)を示します。 待機/アイドル状態など)。たとえば、システムで使用されている合計 CPU などです。
- 空きメモリ/使用メモリ: システムメモリの使用率をバイト単位で指定します。 たとえば、システムで使用される物理メモリなどです。
- ディスク使用量: 次に基づいてファイル システム情報を指定します。 現在のディスク使用量を表します。たとえば、システムで使用されているハードディスク領域などです。
- Load Average: 実行を待機しているプロセスの数を示します。
- ネットワーク統計情報: 送信されたネットワーク パケット/バイト数 特定のコンポーネントに関する送信エラーが表示されます。
プロセス/アプリケーションのチェック
プロセスレベルでは、実行中のすべてのプロセスに関する できます。たとえば、プロセスやアプリケーションによって実行されたメモリや CPU の 説明します。Qpid、Postgres Postmaster、Java などのプロセスについては、 次のとおりです。
- プロセスの識別: 特定の Apigee プロセスを識別します。たとえば Apigee サーバーの Java プロセスの存在をモニタリングできます。
- スレッドの統計情報: プロセスが基盤となるスレッド パターンを表示します。 あります。たとえば、すべてのプロセスのピーク スレッド数やスレッド数をモニタリングできます。
- メモリ使用量: すべての Apigee プロセスのメモリ使用量を表示します。 たとえば、ヒープメモリの使用量、ヒープ以外のメモリ使用量などのパラメータをモニタリングできます。 できます。
API レベルのチェック
API レベルでは、よく使用される API のサーバーが稼働中かどうかをモニタリングできます。
Apigee によってプロキシされる呼び出し。たとえば、管理サーバー、ルーター、
次の curl コマンドを呼び出して、Message Processor と Message Processor も統合します。
curl http://host:port/v1/servers/self/up
ここで、host は Apigee Edge コンポーネントの IP アドレスです。port 各 Edge コンポーネントに固有の番号です。例:
管理サーバー: 8080
- ルーター: 8081
- Message Processor: 8082
- その他
それぞれに対してこのコマンドを実行する方法については、以下の個々のセクションをご覧ください。 コンポーネント
この呼び出しは「true」を返します。「false」に設定します。最良の結果を得るには、API 呼び出しを発行して (Apigee ソフトウェアとやり取りする)バックエンドに直接付与することで、 エラーが Apigee ソフトウェア環境内に存在するかバックエンドに存在するかを示します。
メッセージ フローのチェック
Router と Message Processor からメッセージ フローに関するデータを収集できる パターン/統計。これにより、以下をモニタリングできます。
- アクティブなクライアントの数
- レスポンス数(10X、20X、30X、40X、50X)
- 接続エラー
これにより、API メッセージ フロー用のダッシュボードを提供できます。詳細については、次をご覧ください。 モニタリング方法。
Message Processor のルーター ヘルスチェック
Router はヘルスチェック メカニズムを実装して、どの Message Processor を
確認しますMessage Processor でダウンまたは低速が検出された場合、Router は
Message Processor が自動的にローテーションから除外されます。その場合、Router はパケットを書き込み、
「マークダウン」次の場所にある Router ログファイルに記録されます。
/opt/apigee/var/log/edge-router/logs/system.log。
Router のログファイルでこれらのメッセージをモニタリングできます。たとえば、ルーターが Message Processor はローテーションから外れると、次の形式でメッセージがログに書き込まれます。
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = MP_IP at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /MP_IP:PORT Mark Down
ここで、MP_IP:PORT は Message Processor の IP アドレスとポート番号です。
その後、Router がヘルスチェックを実行し、Message Processor が 正常に機能すると、Router は Message Processor を自動的にローテーションに戻します。「 Router は "Mark Up" も次の形式でログにメッセージを追加します。
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = IP at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from IP:PORT Mark Up