
Private Cloud용 Edge v. 4.17.05
일반적으로 프로덕션 설정에서는 프라이빗 클라우드용 Apigee Edge 배포 내에서 모니터링 메커니즘을 사용 설정해야 합니다. 이러한 모니터링 기법은 네트워크 관리자 (또는 운영자)에게 오류 또는 실패를 경고합니다. 생성된 모든 오류는 Apigee Edge에서 알림으로 보고됩니다. 알림에 관한 자세한 내용은 모니터링 권장사항을 참고하세요.
편의상 Apigee 구성요소는 주로 다음 두 가지 카테고리로 분류됩니다.
- Apigee별 Java 서버 서비스: 여기에는 관리 서버, 메시지 프로세서, Qpid 서버, Postgres 서버가 포함됩니다.
- 서드 파티 서비스: 여기에는 Nginx 라우터, Apache Cassandra, Apache ZooKeeper, OpenLDAP, PostgreSQL 데이터베이스, Qpid가 포함됩니다.
Apigee Edge 온프레미스 배포에서 다음 표는 모니터링할 수 있는 매개변수를 한눈에 보여줍니다.
|
구성요소 |
시스템 확인 |
프로세스 수준 통계 |
API 수준 검사 |
메시지 흐름 확인 |
구성요소별 |
|
|---|---|---|---|---|---|---|
|
Apigee 관련 Java 서비스 |
관리 서버 |
? |
? |
? |
||
|
메시지 프로세서 |
? |
? |
? |
? |
||
|
Qpid 서버 |
? |
? |
? |
|||
|
Postgres 서버 |
? |
? |
? |
|||
|
서드 파티 서비스 |
Apache Cassandra |
? |
? |
|||
|
Apache ZooKeeper |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
PostgreSQL 데이터베이스 |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
Nginx 라우터 |
? |
? |
? |
|||
일반적으로 Apigee Edge를 설치한 후 다음 모니터링 작업을 실행하여 프라이빗 클라우드용 Apigee Edge 설치의 성능을 추적할 수 있습니다.
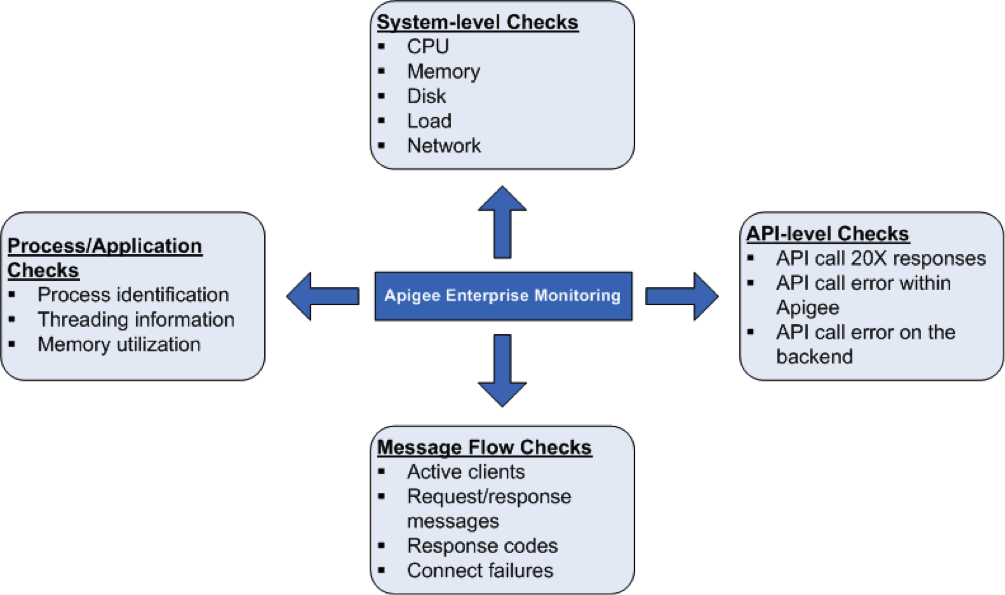
시스템 상태 점검
CPU 사용률, 메모리 사용률, 포트 연결과 같은 시스템 상태 매개변수를 상위 수준에서 측정하는 것이 매우 중요합니다. 다음 매개변수를 모니터링하여 시스템 상태의 기본사항을 확인할 수 있습니다.
- CPU 사용률: CPU 사용률에 관한 기본 통계 (사용자/시스템/IO 대기/유휴)를 지정합니다. 예를 들어 시스템에서 사용한 총 CPU입니다.
- 사용 가능한 메모리/사용된 메모리: 시스템 메모리 사용률을 바이트 단위로 지정합니다. 예를 들어 시스템에서 사용하는 실제 메모리입니다.
- 디스크 공간 사용량: 현재 디스크 사용량을 기반으로 파일 시스템 정보를 지정합니다. 예를 들어 시스템에서 사용하는 하드 디스크 공간이 여기에 해당합니다.
- 부하 평균: 실행을 기다리는 프로세스 수를 지정합니다.
- 네트워크 통계: 전송 및 수신된 네트워크 패킷 또는 바이트와 지정된 구성요소에 관한 전송 오류입니다.
프로세스/애플리케이션 검사
프로세스 수준에서는 실행 중인 모든 프로세스에 관한 중요한 정보를 볼 수 있습니다. 예를 들어 프로세스 또는 애플리케이션에서 사용하는 메모리 및 CPU 사용량 통계가 여기에 포함됩니다. qpidd, postgres postmaster, java와 같은 프로세스의 경우 다음을 모니터링할 수 있습니다.
- 프로세스 식별: 특정 Apigee 프로세스를 식별합니다. 예를 들어 Apigee 서버 Java 프로세스의 존재를 모니터링할 수 있습니다.
- 스레드 통계: 프로세스가 사용하는 기본 스레딩 패턴을 확인합니다. 예를 들어 모든 프로세스의 최대 스레드 수, 스레드 수를 모니터링할 수 있습니다.
- 메모리 사용률: 모든 Apigee 프로세스의 메모리 사용량을 확인합니다. 예를 들어 힙 메모리 사용량, 프로세스에서 사용하는 비힙 메모리 사용량과 같은 매개변수를 모니터링할 수 있습니다.
API 수준 검사
API 수준에서 Apigee에서 프록시하는 자주 사용되는 API 호출에 대해 서버가 실행 중인지 모니터링할 수 있습니다. 예를 들어 다음 cURL 명령어를 호출하여 관리 서버, 라우터, 메시지 프로세서에서 API 검사를 실행할 수 있습니다.
curl http://<host>:<port>/v1/servers/self/up
여기서 <host>는 Apigee Edge 구성요소의 IP 주소입니다. <port> 번호는 각 Edge 구성요소마다 다릅니다. 예를 들면 다음과 같습니다.
관리 서버: 8080
- 라우터: 8081
- 메시지 프로세서: 8082
- 등
각 구성요소에 대해 이 명령어를 실행하는 방법에 관한 자세한 내용은 아래의 개별 섹션을 참고하세요.
이 호출은 'true' 및 'false'를 반환합니다. 최상의 결과를 얻으려면 Apigee 소프트웨어와 상호작용하는 백엔드에서 직접 API 호출을 실행하여 Apigee 소프트웨어 환경 또는 백엔드에 오류가 있는지 빠르게 확인할 수도 있습니다.
참고: API 프록시를 모니터링하려면 Apigee의 API 상태를 사용해도 됩니다. API 상태는 API 프록시를 예약된 시간에 호출하고 실패 시점과 방법을 알려줍니다. 호출이 성공하면 API Health에 응답 시간이 표시되며 응답 지연 시간이 길면 알림을 받을 수도 있습니다. API 상태는 전 세계 여러 위치에서 호출하여 지역 간의 API 동작을 비교할 수 있습니다.
메시지 흐름 확인
라우터와 메시지 프로세서에서 메시지 흐름 패턴/통계에 관한 데이터를 수집할 수 있습니다. 이를 통해 다음을 모니터링할 수 있습니다.
- 활성 클라이언트 수
- 응답 수 (10배, 20배, 30배, 40배, 50배)
- 연결 실패
이렇게 하면 API 메시지 흐름에 대한 대시보드를 제공하는 데 도움이 됩니다. 자세한 내용은 다음을 참고하세요.
- 메시지 프로세서 모니터링 방법
- 라우터의 Apigee 모니터링 대시보드 베타 개요
메시지 프로세서의 라우터 상태 점검
라우터는 상태 확인 메커니즘을 구현하여 예상대로 작동하는 메시지 프로세서를 확인합니다. 메시지 프로세서가 다운되었거나 느린 것으로 감지되면 라우터는 메시지 프로세서를 자동으로 순환에서 제외할 수 있습니다. 이 경우 라우터는 /opt/apigee/var/log/edge-router/logs/system.log의 라우터 로그 파일에 'Mark Down' 메시지를 작성합니다.
라우터 로그 파일에서 이러한 메시지를 모니터링할 수 있습니다. 예를 들어 라우터가 메시지 프로세서를 순환에서 제외하면 다음과 같은 형식으로 로그에 메시지를 씁니다.
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
여기서 /<MP_IP>:<PORT>는 메시지 프로세서의 IP 주소 및 포트 번호입니다.
나중에 라우터가 상태 확인을 실행하고 메시지 프로세서가 제대로 작동하는 것으로 확인되면 라우터는 메시지 프로세서를 자동으로 로테이션에 다시 배치합니다. 라우터는 다음 형식의 'Mark Up' 메시지를 로그에 기록합니다.
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up