
Edge for Private Cloud v. 4.17.05
באופן כללי, בהגדרה בסביבת הייצור צריך להפעיל מנגנוני מעקב בפריסה של Apigee Edge for Private Cloud. שיטות המעקב האלה מאפשרות לאדמינים (או למפעילים) של הרשת לקבל התראות על שגיאות או כשלים. כל שגיאה שנוצרת מדווחת בתור התראה ב-Apigee Edge. מידע נוסף על התראות זמין במאמר שיטות מומלצות למעקב.
כדי להקל עליכם, רכיבי Apigee מסווגים בעיקר לשתי קטגוריות:
- שירותי שרת Java ספציפיים ל-Apigee – השירותים האלה כוללים את Management Server, Message Processor, Qpid Server ו-Postgres Server.
- שירותי צד שלישי – אלה כוללים את Nginx Router, Apache Cassandra, Apache ZooKeeper, OpenLDAP, מסד נתונים של PostgreSQL ו-Qpid.
בפריסה מקומית של Apigee Edge, בטבלה הבאה מפורטת סקירה מהירה של הפרמטרים שאפשר לעקוב אחריהם:
|
רכיב |
בדיקות מערכת |
נתונים סטטיסטיים ברמת התהליך |
בדיקות ברמת ה-API |
בדיקות של תהליך העברת ההודעות |
ספציפי לרכיב |
|
|---|---|---|---|---|---|---|
|
שירותי Java ספציפיים ל-Apigee |
שרת ניהול |
? |
? |
? |
||
|
מעבד בקשות |
? |
? |
? |
? |
||
|
שרת Qpid |
? |
? |
? |
|||
|
שרת Postgres |
? |
? |
? |
|||
|
שירותים של צד שלישי |
Apache Cassandra |
? |
? |
|||
|
Apache ZooKeeper |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
מסד נתונים של PostgreSQL |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
Nginx Router |
? |
? |
? |
|||
באופן כללי, אחרי שתתקינו את Apigee Edge, תוכלו לבצע את משימות המעקב הבאות כדי לעקוב אחרי הביצועים של התקנה של Apigee Edge לענן פרטי.
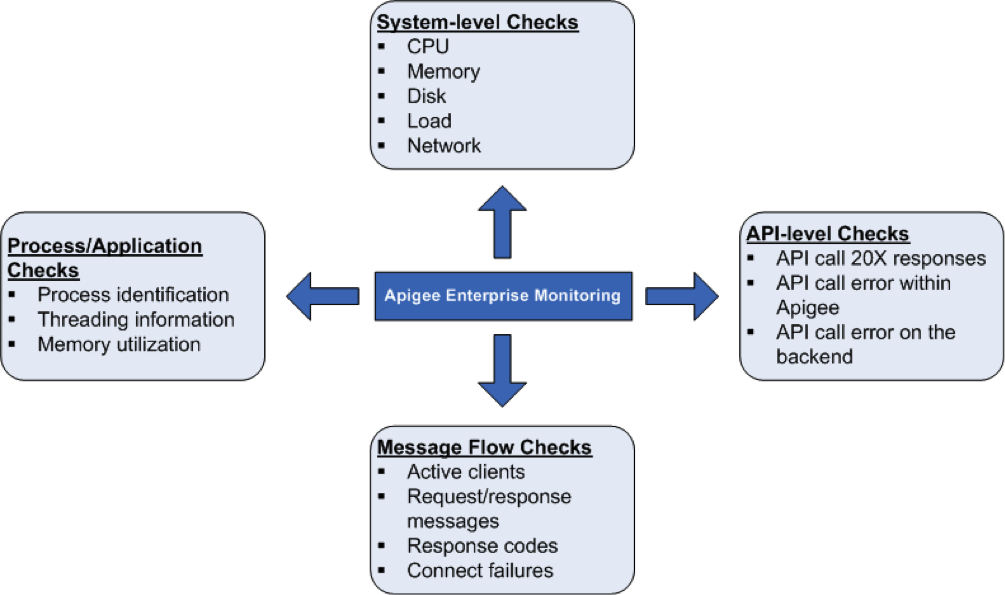
בדיקות תקינות של המערכת
חשוב מאוד למדוד את הפרמטרים של תקינות המערכת, כמו ניצול המעבד (CPU), ניצול הזיכרון וקישוריות היציאות, ברמה גבוהה יותר. אפשר לעקוב אחרי הפרמטרים הבאים כדי לקבל מידע בסיסי על בריאות המערכת.
- ניצול מעבד – מציין את הנתונים הסטטיסטיים הבסיסיים (User/System/IO Wait/Idle) לגבי ניצול המעבד. לדוגמה, סה"כ השימוש במעבד על ידי המערכת.
- זיכרון פנוי/בשימוש – מציין את ניצול זיכרון המערכת ביחידות ביייט. לדוגמה, זיכרון פיזי שהמערכת משתמשת בו.
- Disk Space Usage – מידע על מערכת הקבצים על סמך ניצול האחסון הנוכחי בדיסק. לדוגמה, נפח האחסון בכונן הקשיח שבו המערכת משתמשת.
- Load Average – מציין את מספר התהליכים שממתינים להפעלה.
- נתונים סטטיסטיים של רשת – חבילות נתונים או ביטים ברשת שנשלחו ו/או התקבלו, יחד עם שגיאות השידור של רכיב ספציפי.
בדיקות של תהליכים/אפליקציות
ברמת התהליך, אפשר לראות מידע חשוב על כל התהליכים שפועלים. לדוגמה, נתונים סטטיסטיים על שימוש בזיכרון ובמעבד (CPU) של תהליך או אפליקציה. בתהליכים כמו qpidd, postgres postmaster, java וכו', אפשר לעקוב אחרי הנתונים הבאים:
- זיהוי תהליך: זיהוי תהליך מסוים ב-Apigee. לדוגמה, אפשר לעקוב אחרי קיומו של תהליך Java בשרת Apigee.
- נתונים סטטיסטיים של חוטים: הצגת דפוסי השרשור הבסיסיים שבהם נעשה שימוש בתהליך. לדוגמה, אפשר לעקוב אחרי מספר השיא של השרשור, מספר השרשור בכל התהליכים.
- שימוש בזיכרון: הצגת השימוש בזיכרון של כל תהליכי Apigee. לדוגמה, אפשר לעקוב אחרי פרמטרים כמו שימוש בזיכרון אשכול, שימוש בזיכרון שאינו אשכול בתהליך.
בדיקות ברמת ה-API
ברמת ה-API, אפשר לעקוב אחרי סטטוס השרת של קריאות API נפוצות שמתבצעות דרך שרת proxy של Apigee. לדוגמה, אפשר לבצע בדיקת API בשרת הניהול, בנתב ובמעבד ההודעות באמצעות הפקודה הבאה של cURL:
curl http://<host>:<port>/v1/servers/self/up
כאשר <host> היא כתובת ה-IP של הרכיב Apigee Edge. המספר <port> הוא ספציפי לכל רכיב Edge. לדוגמה:
שרת ניהול: 8080
- נתב: 8081
- מעבד בקשות: 8082
- וכו'
בקטע הבא מוסבר איך מריצים את הפקודה הזו לכל רכיב בנפרד.
הקריאה הזו מחזירה את הערכים 'true' ו-'false'. כדי לקבל את התוצאות הטובות ביותר, אפשר גם להפעיל קריאות API ישירות בקצה העורפי (שתוכנת Apigee מקיימת איתו אינטראקציה) כדי לקבוע במהירות אם יש שגיאה בסביבת התוכנה של Apigee או בקצה העורפי.
הערה: כדי לעקוב אחרי שרתי ה-proxy ל-API, אפשר גם להשתמש ב-API Health של Apigee. התכונה 'מצב API' מבצעת קריאות מתוזמנות לשרתי ה-proxy של ה-API ומעדכנת אתכם אם הן נכשלו ואיך. כשהקריאות מצליחות, מוצגים ב-API Health זמני התגובה, ואפשר גם לקבל התראות כשזמן האחזור של התגובה גבוה. בעזרת API Health אפשר לבצע קריאות ממיקומים שונים ברחבי העולם כדי להשוות את התנהגות ה-API בין אזורים.
בדיקות של תהליך העברת ההודעות
אפשר לאסוף נתונים מרשתות וממעבדי הודעות לגבי דפוס או נתונים סטטיסטיים של זרימת ההודעות. כך תוכלו לעקוב אחרי הנתונים הבאים:
- מספר הלקוחות הפעילים
- מספר התשובות (פי 10, פי 20, פי 30, פי 40 ופי 50)
- כשלים בחיבור
כך תוכלו לספק לוחות בקרה לתעבורת ההודעות ב-API. מידע נוסף זמין במאמרים הבאים:
- איך עוקבים אחרי מעבד ההודעות
- סקירה כללית על גרסת הבטא של לוח הבקרה למעקב אחרי Apigee עבור הנתב
בדיקת תקינות הנתב של מעבד ההודעות
הנתב מטמיע מנגנון לבדיקת תקינות כדי לקבוע אילו מעבדי הודעות פועלים כצפוי. אם מערכת לעיבוד הודעות מזוהה כמושבתת או איטית, הנתב יכול להוציא אותה באופן אוטומטי מהרוטציה. במקרה כזה, הנתב יכתוב הודעות 'Mark Down' בקובץ היומן של הנתב בכתובת /opt/apigee/var/log/edge-router/logs/system.log.
אפשר לעקוב אחרי ההודעות האלה בקובץ היומן של הנתב. לדוגמה, אם הנתב מוציא מערך עיבוד הודעות מהרוטציה, הוא רושם את ההודעה ביומן בפורמט:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
כאשר /<MP_IP>:<PORT> היא כתובת ה-IP ומספר היציאה של מעבד ההודעות.
אם בהמשך הנתב יבצע בדיקת תקינות ויקבע ש-Message Processor פועל כראוי, הנתב יחזור להעביר את Message Processor לתור באופן אוטומטי. הנתב גם רושם ביומן הודעה מסוג 'Mark Up' בפורמט:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up