
Apigee Edge 문서입니다.
Apigee X 문서로 이동 정보
API의 5xx 문제를 해결하는 방법을 보여주는 샘플 시나리오를 단계별로 살펴보세요.
| # | 단계 | 설명 |
|---|---|---|
| 1 | 최근 API 트래픽 모니터링 | 지난 1시간 동안 트래픽이 발생한 모든 API 프록시 및 대상의 최근 API 모니터링 데이터를 확인합니다. 오류율이 높은 API 프록시 또는 타겟을 드릴다운합니다. |
| 2 | API 모니터링 데이터에서 추세 확인 | 최대 3개월까지의 API 모니터링 데이터 기록 보기에 액세스하여 더 폭넓은 관점에서 살펴보세요. |
| 3 | 5xx 문제 조사하기 | 시간 경과에 따라 상대적으로 가장 많은 양의 오류가 발생하는 오류 코드를 확인하여 5xx 문제의 원인을 자세히 조사합니다. 일반적으로 5xx 상태 코드는 하나 이상의 장애 코드를 사용하여 분류할 수 있습니다. |
| 4 | 5xx 알림 설정 | 5xx 상태 코드 수가 특정 기준점을 초과하면 알림을 받도록 알림을 설정합니다. |
| 5 | 클라이언트 세부정보가 포함된 맞춤 보고서 생성 (선택사항) | 원하는 경우 맞춤 보고서를 생성하여 5xx 오류를 트리거하는 클라이언트에 관한 세부정보를 식별합니다. 참고: 맞춤 보고서를 생성하려면 조직 관리자여야 합니다. |
| 6 | API 프록시를 컬렉션으로 그룹화 | API 프록시를 그룹화하는 컬렉션을 만들고 그룹의 모든 구성원에 적절한 알림 기준 값을 설정하여 문제를 더 빠르게 진단합니다.
|
| 7 | 5xx 문제 해결하기 | 조사 및 진단에 따라 5xx 문제를 해결하기 위한 적절한 조치를 취합니다. |
1단계: 최근 API 트래픽 모니터링
지난 1시간 동안 트래픽이 발생한 API 프록시 및 타겟의 API 모니터링 데이터를 보려면 다음 단계를 따르세요.
- Edge UI에서 분석 > API 모니터링 > 최근을 선택하여 최근 대시보드에 액세스합니다.
지난 1시간 동안 오류율이 높은 API 프록시 및 대상을 확인합니다.
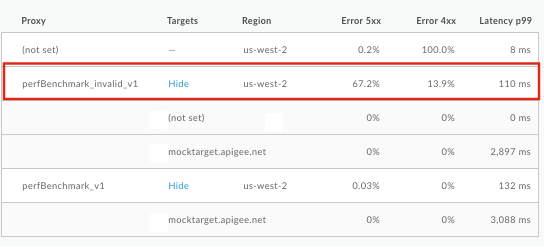
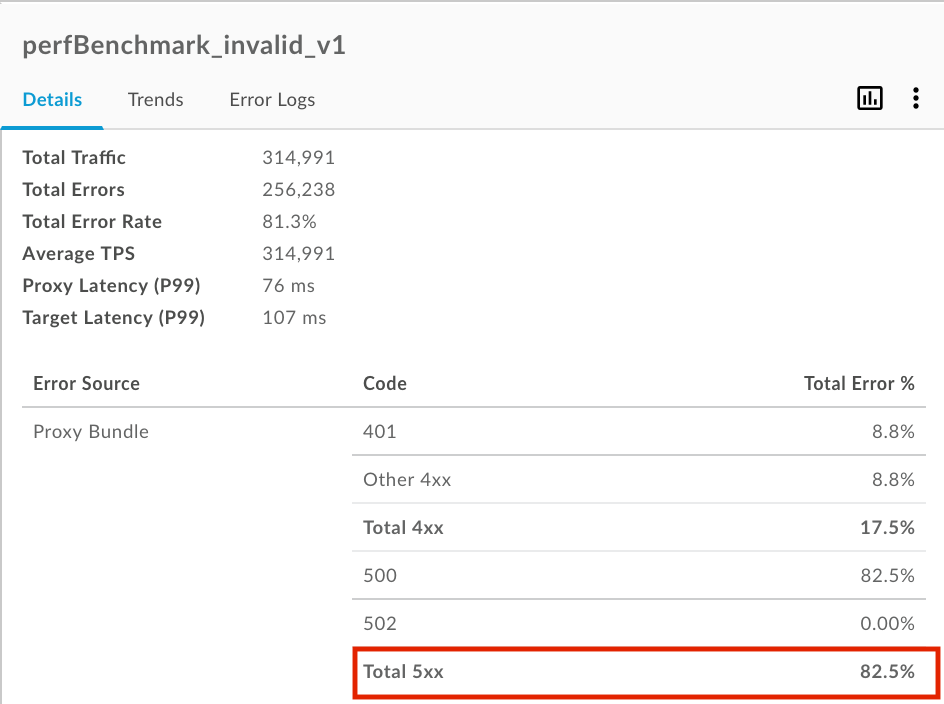
오류 비율이 높은 API 프록시 또는 타겟을 클릭하여 오른쪽 창에 세부정보를 표시합니다. 이 예시에서 5xx 오류의 비율이 높습니다.
이 단계에 관한 자세한 내용은 최근 API 트래픽 모니터링을 참고하세요.
2단계: API 모니터링 데이터에서 추세 확인
지난 3개월 동안 트래픽이 발생한 API 프록시 및 타겟의 API 모니터링 데이터에 대한 이전 뷰에 액세스하려면 다음 단계를 따르세요.
- 최근 대시보드의 오른쪽 창에서
 > 타임라인에서 보기를 선택하여 타임라인 대시보드에 액세스합니다.
또는 Edge UI에서 분석 > API 모니터링 > 타임라인을 클릭할 수도 있습니다.
> 타임라인에서 보기를 선택하여 타임라인 대시보드에 액세스합니다.
또는 Edge UI에서 분석 > API 모니터링 > 타임라인을 클릭할 수도 있습니다.
- 시간 경과에 따른 API 프록시 또는 타겟의 동향을 확인합니다. 지난 7일 동안 이 추세가 일관되게 유지되고 있습니다.
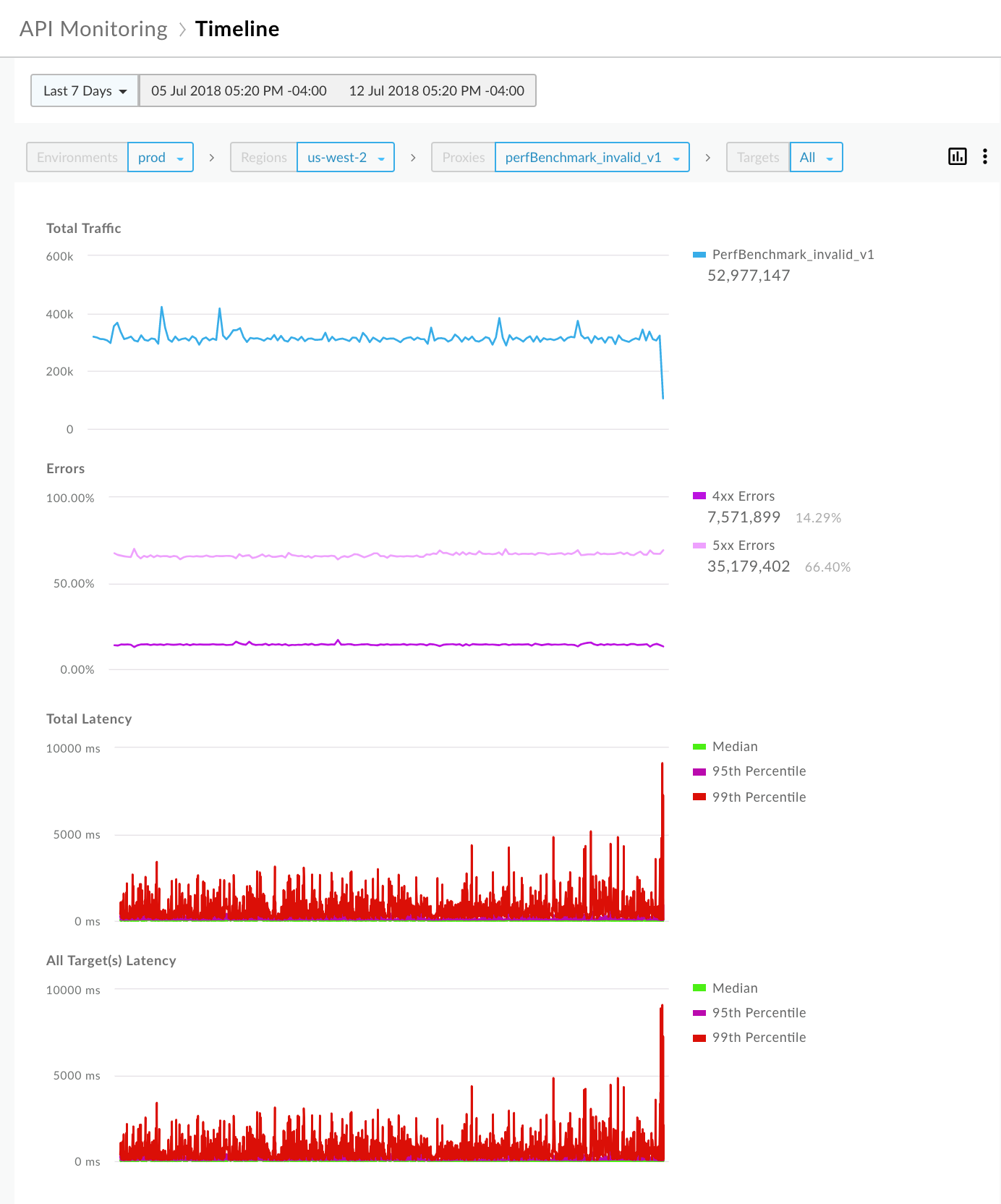
이 단계에 관한 자세한 내용은 API 모니터링 데이터에서 추세 확인을 참고하세요.
3단계: 5xx 문제 조사
Apigee는 문제를 진단하는 데 도움이 되는 일련의 오류 코드를 제공합니다. 일반적으로 5xx 상태 코드는 하나 이상의 장애 코드를 사용하여 분류할 수 있습니다.
5xx 문제를 조사하려면 다음 단계를 따르세요.
- 타임라인 대시보드의 오른쪽 창에서 > 조사에서 보기를 선택하여 조사 대시보드에 액세스합니다.
또는 Edge UI에서 분석 > API 모니터링 > 조사를 클릭해도 됩니다.
조사 대시보드를 사용하면 오류 코드와 시간 등 측정항목 간의 관계형 활동을 비교할 수 있습니다. 오류 코드 및 시간 비교 매트릭스를 확인하여 지난 1시간 동안의 오류 코드 활동을 확인하세요. 블록의 색상 음영을 기준으로 상대 볼륨이 가장 높은 오류 코드를 확인합니다. 블록이 어두울수록 상대 볼륨이 높습니다.
예를 들어
policies.ratelimit.SpikeArrestViolation및policies.ratelimit.QuotaViolation오류 코드는 다음 매트릭스에서 상대적으로 더 많은 양을 보여주고 있습니다.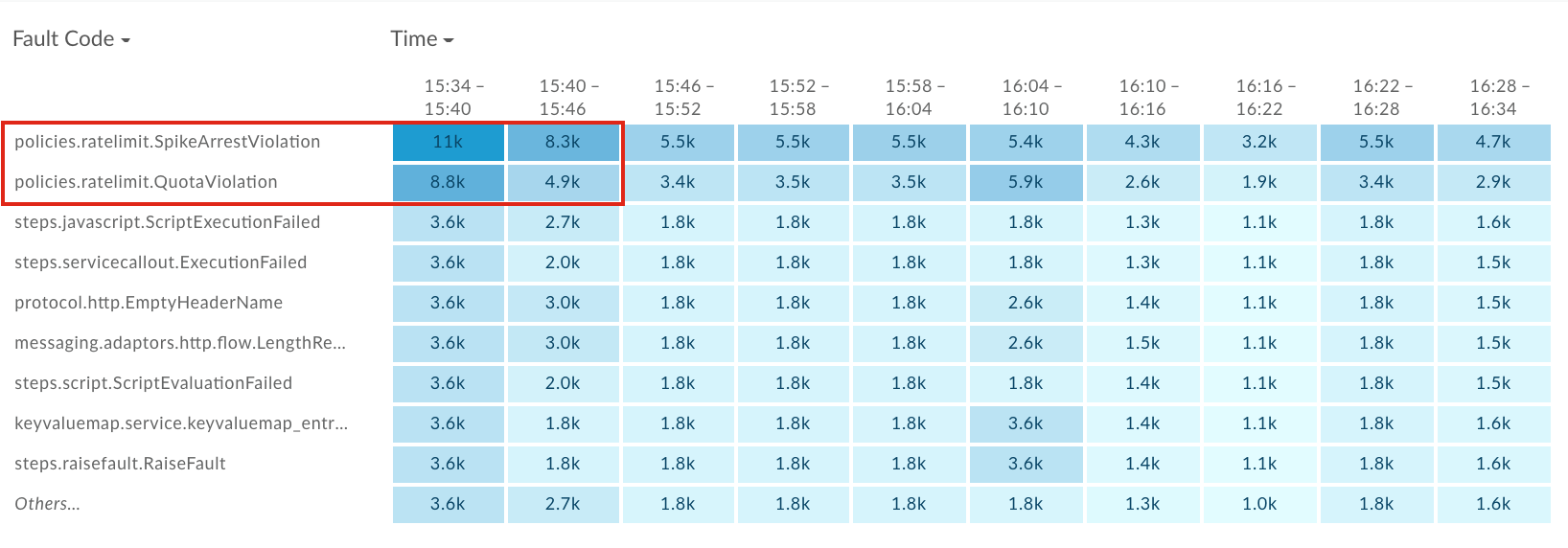
policies.ratelimit.SpikeArrestViolation행에서 가장 어두운 블록 (첫 번째 블록)을 클릭하여 오른쪽 창에서 세부정보를 확인합니다.
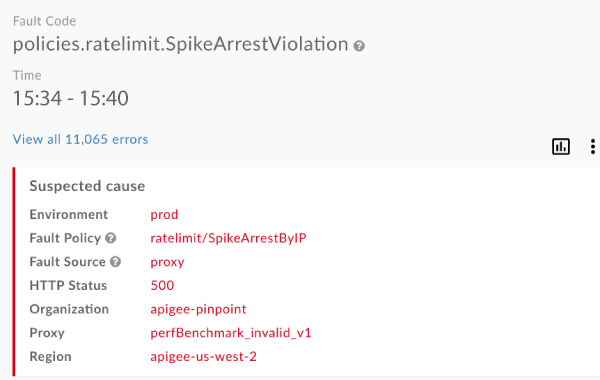
오류 소스가 perfBenchmark_invalid_v1 API 프록시이고 HTTP 상태 코드가 500입니다. 500 상태 코드는 급증 저지 정책 위반에 대한 일반적인 런타임 오류 코드입니다.
'추정 원인' 패널 바로 아래에 있는 '개발자 앱별 배포'를 확인하여 오류율이 가장 높은 개발자 앱을 파악합니다.

이 단계에 대한 자세한 내용은 문제 식별을 참고하세요.
4단계: 5xx 알림 설정
조사 세부정보 창에서 선택한 컨텍스트를 기반으로 알림을 설정하여 5xx 상태 코드 수가 특정 임곗값을 초과하면 알림을 받습니다.
조사 대시보드의 오른쪽 창에서
> 알림 만들기를 선택합니다.
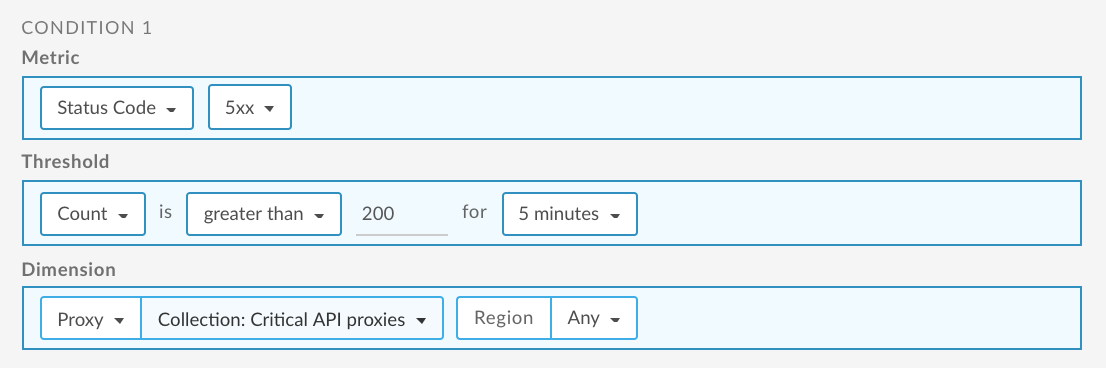
알림 대화상자의 필드를 작성합니다. 조건 필드는 현재 컨텍스트의 데이터로 자동 입력됩니다. 예를 들면 다음과 같습니다.
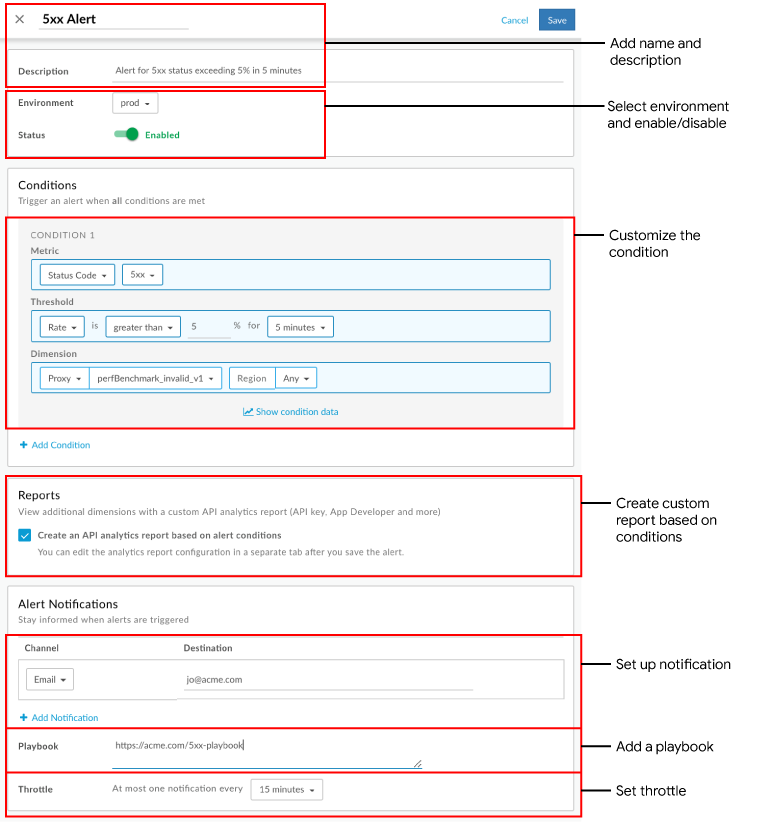
저장을 클릭합니다.
향후 5xx 오류율이 perfBenchmark_invalid_v1 API 프록시에 대해 5분 동안 5% 를 초과하면 지정된 이메일로 알림이 전송되고 UI에 시각적 경고가 표시됩니다. 예를 들면 다음과 같습니다.
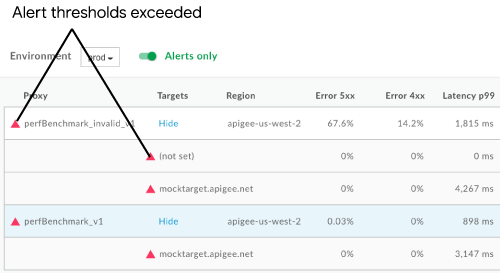
이 단계에 대한 자세한 내용은 경고 및 알림 설정을 참고하세요.
5단계: 고객 세부정보가 포함된 맞춤 보고서 생성 (선택사항)
원하는 경우 맞춤 보고서를 생성하여 5xx 오류를 트리거하는 클라이언트에 관한 자세한 정보를 확인합니다.
보고서 페이지에서 경고를 기반으로 생성된 맞춤 보고서의 이름은 API Monitoring Generated: alert-name 형식을 사용합니다.
다음 방법 중 하나를 사용하여 알림을 설정할 때 생성된 맞춤 보고서에 액세스합니다.
왼쪽 탐색 메뉴에서 분석 > 커스텀 보고서 > 보고서를 선택하여 보고서 페이지를 표시합니다. 목록에서 API 모니터링 생성: 5xx 알림 보고서 이름을 클릭합니다.
알림이 생성될 때 표시되는 알림 내에서 클릭합니다. 예를 들면 다음과 같습니다.

다음 측정기준을 추가합니다.
- 개발자 앱
- 클라이언트 ID
- 클라이언트 IP 주소
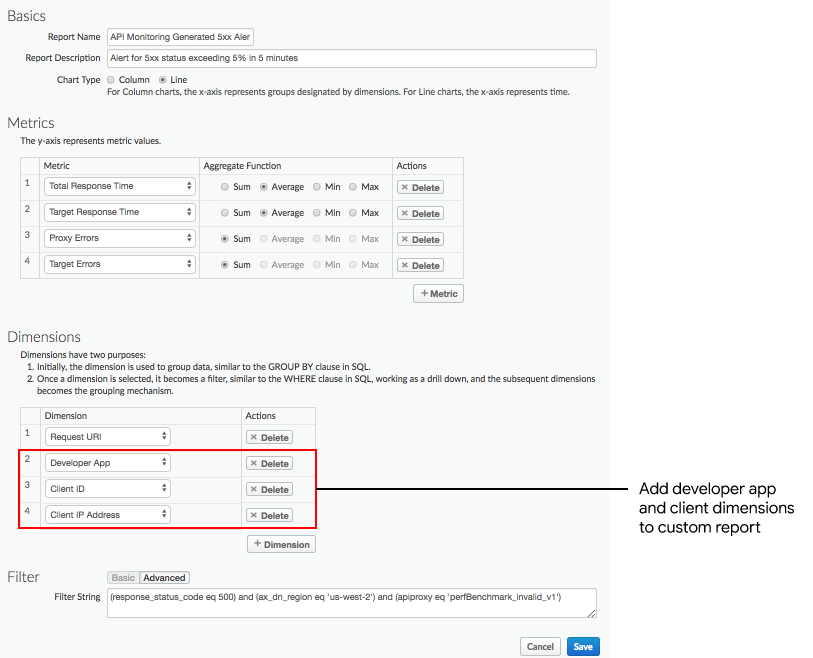
오류율이 높은 특정 개발자 앱을 기반으로 보고서를 보려면 다음과 유사한 필터를 추가합니다.
and (developer_app eq 'perfBenchmarkApp0')참고: 이 경우 측정기준 목록에서 개발자 앱을 삭제합니다.
저장을 클릭합니다.
보고서를 실행하여 5xx 상태 코드를 트리거하는 개발자 앱 및 클라이언트에 관한 세부정보를 확인합니다.
이 단계에 관한 자세한 내용은 맞춤 보고서 만들기를 참고하세요.
6단계: API 프록시를 컬렉션으로 그룹화
API 프록시를 그룹화하는 컬렉션을 만들고 그룹의 모든 구성원에 적절한 알림 기준 값을 설정하여 문제를 더 빠르게 진단합니다.
- Edge UI에서 분석 > API 모니터링 > 컬렉션을 선택하여 컬렉션 대시보드를 표시합니다.
- + 컬렉션을 클릭합니다.
- 프록시를 선택합니다.
- 환경 드롭다운에서 prod를 선택합니다.
- 다음을 클릭합니다.
- 컬렉션 대화상자의 필드를 작성합니다.
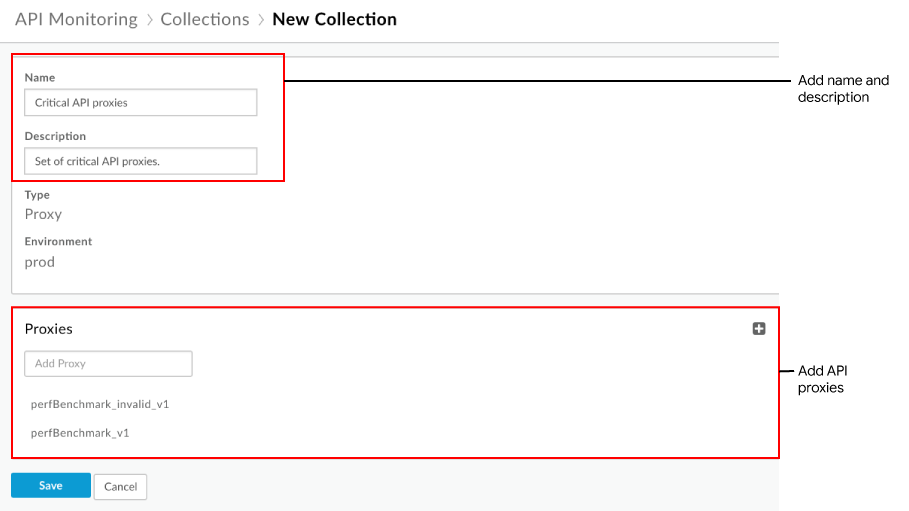
- 저장을 클릭합니다.
그런 다음 4단계와 마찬가지로 알림을 설정하고 측정기준을 위에 정의한 컬렉션으로 설정할 수 있습니다.
이 단계에 대한 자세한 내용은 컬렉션 관리를 참고하세요.
7단계: 5xx 문제 해결
5xx 문제를 해결하기 위해 적절한 조치를 취합니다. 예를 들어 진단에 따라 다음 작업 중 하나를 수행할 수 있습니다.
- Apigee Sense를 사용하여 요청 급증이 의심스러운지 확인하고 맞춤 보고서에서 식별된 클라이언트 IP 주소를 차단할지 결정합니다.
- 할당량 정책을 추가하여 개발자 앱이 특정 기간 동안 API 프록시에 연결할 수 있는 수를 제한합니다.
- API로 수익을 창출하여 특정 호출 횟수를 초과하는 사용량에 대해 개발자에게 요금을 청구합니다.