
您正在查看 Apigee Edge 文档。
前往 Apigee X 文档。 信息
为指定的服务代理设置权限
为应对上述变更,请执行以下步骤,为分配的服务代理设置权限。
- 输入以下命令,查找您的 Google Cloud 服务客服人员的姓名:
curl -X GET \ "https://api.enterprise.apigee.com/v1/organizations/ORG" \ -u email:password \ | jq -r '.properties.property[] | select(.name=="serviceAgent.analytics") | .value'
其中 ORG 是您的组织。 这会返回服务代理的名称和值,如下所示:
"property" : [ { "name" : "serviceAgent.analytics", "value" : "service-9q1ibk@gcp-sa-apigee-uap.iam.gserviceaccount.com" }, - 在 Google Cloud 控制台中打开 IAM 信息中心。
- 选择您的 Google Cloud 项目。
- 点击 IAM 窗格顶部的添加。
- 在新的主账号字段中,输入第 1 步中返回的服务代理
value。例如,第 1 步中显示的value为service-9q1ibk@gcp-sa-apigee-uap.iam.gserviceaccount.com。 - 点击 + 添加其他角色按钮,然后添加以下角色:
- BigQuery User
- Storage Admin
- 点击保存。
Apigee Analytics 数据
Apigee Analytics 会收集并分析流经您的 API 的大量数据,并提供直观的工具,包括互动式信息中心、自定义报告以及其他可标识 API 代理性能趋势的工具。 现在,您可以通过将分析数据从 Apigee Analytics 导出到您自己的数据存储区(例如 Google Cloud Storage 或 Google BigQuery)来解锁这些丰富内容。然后,您可以利用 Google BigQuery 和 TensorFlow 提供的强大的查询和机器学习功能来执行您自己的数据分析。您还可以将导出的分析数据与其他数据(如网络日志)合并,从而深入了解您的用户、API 和应用。导出数据格式
将分析数据导出为以下格式之一:
逗号分隔值 (CSV)
默认分隔符是英文逗号 (,) 字符。支持的分隔符包括逗号 (,)、竖线 (|) 和制表符 (\t)。使用
csvDelimiter属性配置值,如导出请求属性参考文档中所述。JSON(以换行符分隔)
允许将换行符用作分隔符。
导出的数据包括 Edge 内置的所有分析指标和维度,以及您添加的任何自定义分析数据。如需了解导出数据的说明,请参阅分析指标、维度和过滤器参考文档。
您可以将分析数据导出至以下数据存储区:
导出流程概览
以下步骤汇总了用于导出分析数据的过程:
为数据导出配置数据存储区(Cloud Storage 或 BigQuery)。您必须确保已正确配置数据存储区,并且用于将数据写入数据存储区的服务账号具有正确的权限。
创建数据存储区,以定义用于导出数据的数据存储区(Cloud Storage 或 BigQuery)的属性,包括用于访问数据存储区的凭据。
创建数据存储区时,您需要将数据库凭据上传到 Edge 凭据保险柜以安全地存储它们。然后,数据导出机制会使用这些凭据将数据写入您的数据仓库。
使用数据导出 API 发起数据导出。数据导出会在后台异步运行。
使用数据导出 API 确定导出何时完成。
导出完成后,访问数据存储库中导出的数据。
下面几个部分将详细介绍这些步骤。
配置数据存储区
分析数据导出机制会将数据写入 Cloud Storage 或 BigQuery。为了实现此写入,您必须满足以下条件:
- 创建 Google Cloud Platform 服务账号。
- 设置服务账号的角色,以便其可以访问 Cloud Storage 或 BigQuery。
为 Cloud Storage 或 BigQuery 创建服务账号
服务账号是一种属于应用而非个别用户的 Google 账号。然后,您的应用使用该服务账号访问服务。
服务账号具有由 JSON 字符串表示的服务账号密钥。创建用于定义与数据库连接的 Edge 数据存储区时,您需要向其传递此密钥。然后,数据导出机制会使用该密钥访问您的数据存储库。
与密钥关联的服务账号必须是 Google Cloud Platform 项目所有者,并且对 Google Cloud Storage 存储分区拥有写入权限。如需创建服务密钥并下载所需的载荷,请参阅 Google Cloud Platform 文档中的创建和管理服务账号密钥。
例如,当您首次下载密钥时,其格式为 JSON 对象:
{ "type": "service_account", "project_id": "myProject", "private_key_id": "12312312", "private_key": "-----BEGIN PRIVATE KEY-----\n...", "client_email": "client_email@developer.gserviceaccount.com", "client_id": "879876769876", "auth_uri": "https://accounts.google.com/organizations/oauth2/auth", "token_uri": "https://oauth2.googleapis.com/token", "auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2", "client_x509_cert_url": "https://www.googleapis.com" }
配置 Google Cloud Storage
在将数据导出到 Google Cloud Storage 之前,请先做好以下准备:
- 确保您的 Google Cloud Platform 项目已启用 BigQuery 和 Cloud Resource Manager API。如需了解相关说明,请参阅启用 API。导出到 Cloud Storage 时,Apigee 会使用 BigQuery API 来利用 BigQuery 导出功能,并在每次导出之前使用 Cloud Resource Manager API 检查权限。
确保将该服务账号分配给以下角色:
- BigQuery Job User
- Storage Object Creator
- 存储空间管理员(仅在测试数据存储区时需要,如测试数据存储区配置中所述)。如果此角色过于宽泛,您可以改为向现有角色添加
storage.buckets.get权限。)
此外,如果您要修改现有角色或创建自定义角色,请在角色中添加以下权限:
bigquery.jobs.createstorage.objects.createstorage.buckets.get(仅在测试数据存储区时需要,如测试数据存储区配置中所述)
配置 Google BigQuery
在将数据导出到 Google BigQuery 之前,请先做好以下准备:
- 确保您的 Google Cloud Platform 项目已启用 BigQuery 和 Cloud Resource Manager API。如需了解相关说明,请参阅启用 API。Apigee 会在每次导出之前使用 Cloud Resource Manager API 检查权限。
- 确保您的 Google Cloud Platform 项目已启用 BigQuery API。如需了解相关说明,请参阅启用和停用 API。
确保将该服务账号分配给以下角色:
- BigQuery Job User
- BigQuery 数据编辑者
如果您要修改现有角色或创建自定义角色,请在角色中添加以下权限:
bigquery.datasets.createbigquery.datasets.getbigquery.jobs.createbigquery.tables.createbigquery.tables.getbigquery.tables.updateData
创建数据存储区
数据存储区定义与导出数据存储区(Cloud Storage、BigQuery)的连接,包括用于访问数据存储区的凭据。
Edge 凭据保险柜简介
Edge 使用 Credentials Vault 安全地存储用于访问导出数据存储库的凭据。为了让服务能够访问 Edge 凭据保险柜中的凭据,您必须定义凭据使用方。
使用 Edge 界面创建数据存储时(如下所述),Edge 会自动创建用于访问凭据的使用方。
测试数据存储区配置
创建数据存储区时,Edge 不会测试或验证您的凭据和数据存储区配置是否有效。这意味着您可以创建数据存储区,并且在运行首次数据导出之前不检测到任何错误。
或者,您也可以先测试数据存储区配置,然后再创建数据存储区。测试非常有用,因为大量数据导出过程可能需要很长时间才能执行完毕。在开始下载大量数据之前,请先测试您的凭据和数据存储区配置,以便快速修复设置中存在的任何问题。
如果测试成功,请创建数据存储区。如果测试失败,请修正错误,然后重新测试配置。您只需在测试成功后创建数据存储区。
如需启用测试功能,您必须:
- 确保已在您的 Google Cloud Platform 项目中启用 Cloud Resource Manager API。如需了解相关说明,请参阅启用和停用 API。
创建数据存储区
如需在界面中创建数据存储区,请执行以下操作:
以组织管理员身份登录 https://apigee.com/edge,然后选择您的组织。
注意:您必须是 Edge 组织管理员,才能创建数据存储区。
在左侧导航栏中,依次选择管理 > Google Analytics 数据存储空间。系统随即会显示 Analytics 数据存储空间页面。
选择 + 添加数据存储空间按钮。系统会提示您选择数据存储区类型:
选择导出数据目标类型:
- Google Cloud Storage
- Google BigQuery
系统随即会显示配置页面:
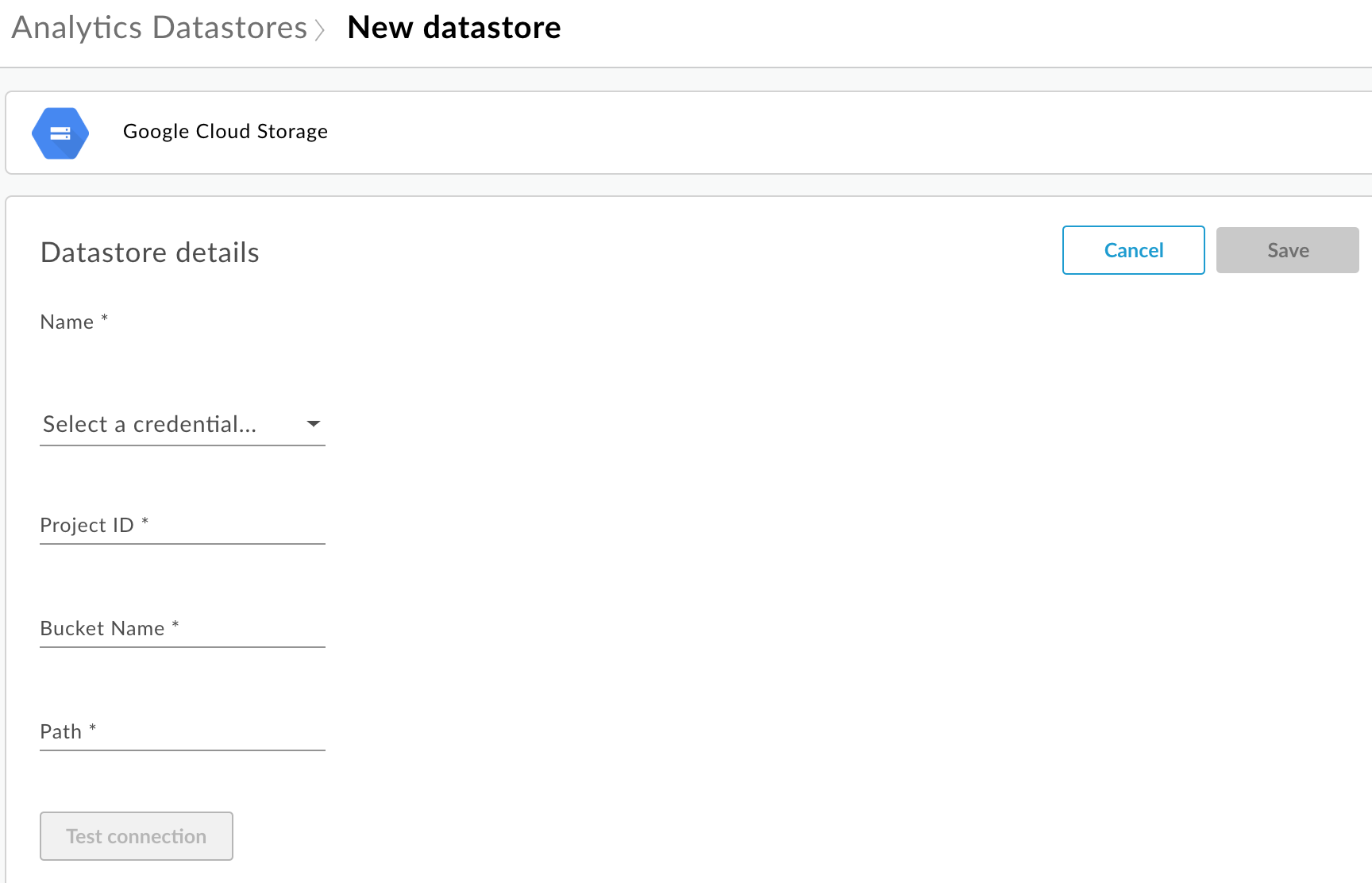
输入数据存储区名称。
选择用于访问数据仓库的凭据。系统会显示可用凭据的下拉列表。
凭据因数据仓库类型而异。如需了解详情,请参阅为 Cloud Storage 或 BigQuery 创建服务账号。
如果您已上传凭据,请从下拉列表中选择凭据。请确保您选择的凭据适用于数据仓库类型。
如果您要向数据存储区添加新的凭据,请选择添加新的凭据。在对话框中,输入以下内容:
- 凭据名称。
- 凭据内容是特定于您的数据存储库的 JSON 服务账号密钥,如为 Cloud Storage 或 BigQuery 创建服务账号中所定义。
- 选择 Create。
输入特定于数据仓库类型的属性:
- 对于 Google Cloud Storage:
属性 说明 是否必需? 项目 ID Google Cloud Platform 项目 ID。 如需创建 Google Cloud Platform 项目,请参阅 Google Cloud Platform 文档中的创建和管理项目。
是 存储分区名称 Cloud Storage 中您希望导出分析数据的存储分区的名称。在执行数据导出之前,此存储分区必须已存在。 如需创建 Cloud Storage 存储分区,请参阅 Google Cloud Platform 文档中的创建存储分区。
是 路径 用于存储 Cloud Storage 存储分区中的分析数据的目录。 是 - 对于 BigQuery:
属性 说明 是否必需? 项目 ID Google Cloud Platform 项目 ID。 如需创建 Google Cloud Platform 项目,请参阅 Google Cloud Platform 文档中的创建和管理项目。
是 数据集名称 您希望将分析数据导出到其中的 BigQuery 数据集的名称。确保在请求数据导出之前创建数据集。 如需创建 BigQuery 数据集,请参阅 Google Cloud Platform 文档中的创建和使用数据集。
是 表前缀 为 BigQuery 数据集中的分析数据创建的表名称的前缀。 是
- 对于 Google Cloud Storage:
选择测试连接,确保可以使用这些凭据访问数据库。
如果测试成功,请保存数据存储区。
如果测试失败,请解决所有问题,然后重试。将鼠标悬停在界面中的错误消息上,即可在提示中显示更多信息。
连接测试通过后,保存数据存储区。
修改数据存储区
如需修改数据存储区,请执行以下操作:
以组织管理员身份登录 https://apigee.com/edge,然后选择您的组织。
在左侧导航栏中,依次选择管理 > Google Analytics 数据存储空间。系统随即会显示 Analytics 数据存储空间页面。
将鼠标指针悬停在要修改的报告的修改时间列上。系统会显示修改和删除图标。
修改或删除数据存储区。
如果您修改了数据存储区,请选择测试连接,确保凭据可用于访问数据存储区。
如果测试成功,您可以在数据仓库中查看示例数据。
如果测试失败,请解决所有问题,然后重试。
连接测试通过后,更新数据存储区。
导出分析数据
如需导出分析数据,请向 /analytics/exports API 发出 POST 请求。在请求正文中传递以下信息:
- 导出请求的名称和说明
- 所导出数据的日期范围(值只能跨越一天)
- 所导出数据的格式
- 数据存储区名称
- 组织是否启用了获利功能
下面提供了导出请求的示例。如需请求正文属性的完整说明,请参阅导出请求属性参考文档。
来自 POST 的响应格式如下:
{
"self": "/organizations/myorg/environments/test/analytics/exports/a7c2f0dd-1b53-4917-9c42-a211b60ce35b",
"created": "2017-09-28T12:39:35Z",
"state": "enqueued"
}
请注意,响应中的 state 属性设置为 enqueued。POST 请求是异步运行的。这表示请求在返回响应后会继续在后台运行。state 可能的值包括:enqueued、running、completed、failed。
使用 self 属性中返回的网址查看数据导出请求的状态,如查看分析导出请求的状态中所述。请求完成后,响应中的 state 属性的值设置为 completed。然后,您便可以访问数据存储区中的分析数据。
示例 1:将数据导出到 Cloud Storage
以下请求会从 myorg 组织的 test 环境中导出过去 24 小时的完整原始数据集。内容会以 JSON 格式导出到 Cloud Storage:
curl -X POST -H "Content-Type:application/json" \
"https://api.enterprise.apigee.com/v1/organizations/myorg/environments/test/analytics/exports" \
-d \
'{
"name": "Export raw results to Cloud Storage",
"description": "Export raw results to Cloud Storage for last 24 hours",
"dateRange": {
"start": "2018-06-08",
"end": "2018-06-09"
},
"outputFormat": "json",
"datastoreName": "My Cloud Storage data repository"
}' \
-u orgAdminEmail:password
使用 self 属性指定的 URI 来监控作业状态,如查看分析导出请求的状态中所述。
示例 2:将数据导出到 BigQuery
以下请求会将以英文逗号分隔的 CSV 文件导出到 BigQuery:
curl -X POST -H "Content-Type:application/json" \
"https://api.enterprise.apigee.com/v1/organizations/myorg/environments/test/analytics/exports" \
-d \
'{
"name": "Export query results to BigQuery",
"description": "One-time export to BigQuery",
"dateRange": {
"start": "2018-06-08",
"end": "2018-06-09"
},
"outputFormat": "csv",
"csvDelimiter": ",",
"datastoreName": "My BigQuery data repository"
}' \
-u orgAdminEmail:password
注意:导出的 CSV 文件会创建一个具有以下前缀的 BigQuery 表:
<PREFIX>_<EXPORT_DATE>_api_<UUID>_from_<FROM_DATE>_to_<TO_DATE>
使用 self 属性指定的 URI 来监控作业状态,如查看分析导出请求的状态中所述。
示例 3:导出获利数据
如果在组织的环境中启用了获利功能,您可以执行两种类型的数据导出:
- 标准数据导出(如前面的两个示例所示)。
- 获利数据导出,以导出特定于获利的数据。
如需执行获利数据导出,请在请求载荷中指定 "dataset":"mint"。组织和环境必须支持获利,才能设置此选项,否则将从载荷中省略 dataset 属性:
'{
"name": "Export raw results to Cloud Storage",
"description": "Export raw results to Cloud Storage for last 24 hours",
"dateRange": {
"start": "2018-06-08",
"end": "2018-06-09"
},
"outputFormat": "json",
"datastoreName": "My Cloud Storage data repository",
"dataset":"mint"
}'Export API 配额简介
为防止过度使用昂贵的数据导出 API 调用,Edge 会对 /analytics/exports API 调用强制执行配额:
对于尚未启用获利功能的组织和环境,配额如下:
- 每个组织/环境每月 70 次调用。
例如,如果贵组织中有两个环境(
prod和test),则每个环境每月可以进行 70 次 API 调用。对于已启用获利功能的组织和环境,配额为:
- 对于标准数据,每个组织和环境每月 70 次调用。
- 对于获利数据,每个组织和环境每月 70 次调用。
例如,如果您为
prod组织启用了获利功能,您可以对标准数据进行 70 次 API 调用,以及针对获利数据再进行 70 次调用。
如果超过调用配额,API 将返回 HTTP 429 响应。
查看所有分析导出请求的状态
如需查看所有分析导出请求的状态,请向 /analytics/exports 发出 GET 请求。
例如,以下请求将返回 myorg 组织中 test 环境的所有分析导出请求的状态:
curl -X GET \ "https://api.enterprise.apigee.com/v1/organizations/myorg/environments/test/analytics/exports" \ -u email:password
下面提供一个响应示例,其中列出两个导出请求,即一个已加入队列的请求(在队列中创建),以及一个已完成的请求:
[
{
"self":
"/v1/organizations/myorg/environments/test/analytics/exports/e8b8db22-fe03-4364-aaf2-6d4f110444ba",
"name": "Export results To Cloud Storage",
"description": "One-time export to Google Cloud Storage",
"userId": "my@email.com",
"datastoreName": "My Cloud Storage data store",
"executionTime": "36 seconds",
"created": "2018-09-28T12:39:35Z",
"updated": "2018-09-28T12:39:42Z",
"state": "enqueued"
},
{
"self":
"/v1/organizations/myorg/environments/test/analytics/exports/9870987089fe03-4364-aaf2-6d4f110444ba"
"name": "Export raw results to BigQuery",
"description": "One-time export to BigQuery",
...
}
]
查看一个分析导出请求的状态
如需查看特定分析导出请求的状态,请向 /analytics/exports/{exportId} 发出 GET 请求,其中 {exportId} 是与分析导出请求关联的 ID。
例如,以下请求将返回 ID 为 4d6d94ad-a33b-4572-8dba-8677c9c4bd98 的分析导出请求的状态。
curl -X GET \ "https://api.enterprise.apigee.com/v1/organizations/myorg/environments/test/analytics/exports/4d6d94ad-a33b-4572-8dba-8677c9c4bd98" \ -u email:password
以下提供了一个响应示例:
{
"self":
"/v1/organizations/myorg/environments/test/analytics/exports/4d6d94ad-a33b-4572-8dba-8677c9c4bd98",
"name": "Export results To Cloud Storage",
"description": "One-time export to Google Cloud Storage",
"userId": "my@email.com",
"datastoreName": "My Cloud Storage data store",
"executionTime": "36 seconds",
"created": "2018-09-28T12:39:35Z",
"updated": "2018-09-28T12:39:42Z",
"state": "enqueued"
}
如果分析导出未返回分析数据,则 executionTime 设置为“0 秒”。
导出请求属性参考文档
下表介绍了您可以在导出分析数据时,在请求正文中以 JSON 格式传递的属性。
| 属性 | 说明 | 是否必需? |
|---|---|---|
description
|
导出请求的说明。 | 否 |
name
|
导出请求的名称。 | 是 |
dateRange
|
以
"dateRange": {
"start": "2018-07-29",
"end": "2018-07-30"
}
注意:为了确保获取前一天的数据,您可能需要延迟导出请求的开始时间(例如,00:05:00 AM 世界协调时间 [UTC])。 |
是 |
outputFormat
|
指定为 json 或 csv。 |
是 |
csvDelimiter
|
如果将 |
否 |
datastoreName
|
包含数据存储区定义的数据存储区的名称。 | 是 |
例如:
{
"name": "Export raw results to Cloud Storage",
"description": "Export raw results to Cloud Storage for last 24 hours",
"dateRange": {
"start": "2018-06-08",
"end": "2018-06-09"
},
"outputFormat": "json",
"datastoreName": "My Cloud Storage data repository"
}