
Edge for Private Cloud v4.18.01
Im Allgemeinen müssen in einer Produktionsumgebung Monitoringmechanismen in einer Apigee Edge für die Bereitstellung der privaten Cloud Diese Monitoringtechniken warnen das Netzwerk Administratoren (oder Operatoren) eines Fehlers oder Fehlers. Jeder generierte Fehler wird gemeldet als in Apigee Edge erhalten. Weitere Informationen zu Benachrichtigungen finden Sie unter Best Practices für das Monitoring.
Der Einfachheit halber werden Apigee-Komponenten hauptsächlich in zwei Kategorien unterteilt:
- Apigee-spezifische Java Server-Dienste – dazu gehört die Verwaltung Server, Message Processor, Qpid Server und Postgres Server.
- Drittanbieterdienste – Dazu gehören Nginx Router, Apache Cassandra, Apache ZooKeeper, OpenLDAP, PostgreSQL-Datenbank und Qpid
Bei einer lokalen Bereitstellung von Apigee Edge bietet die folgende Tabelle einen kurzen Überblick die Parameter, die Sie überwachen können:
|
Komponente |
Systemprüfungen |
Statistiken auf Prozessebene |
Prüfungen auf API-Ebene |
Prüfungen des Nachrichtenflusses |
Komponentenspezifisch |
|
|---|---|---|---|---|---|---|
|
Apigee-spezifische Java-Dienste |
Verwaltungsserver |
? |
? |
? |
||
|
Message Processor |
? |
? |
? |
? |
||
|
QPID-Server |
? |
? |
? |
|||
|
Postgres-Server |
? |
? |
? |
|||
|
Drittanbieterdienste |
Apache Cassandra |
? |
? |
|||
|
Apache ZooKeeper |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
PostgreSQL-Datenbank |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
Nginx-Router |
? |
? |
? |
|||
Im Allgemeinen können Sie nach der Installation von Apigee Edge das folgende Monitoring ausführen: um die Leistung einer Apigee Edge for Private Cloud-Installation zu verfolgen.
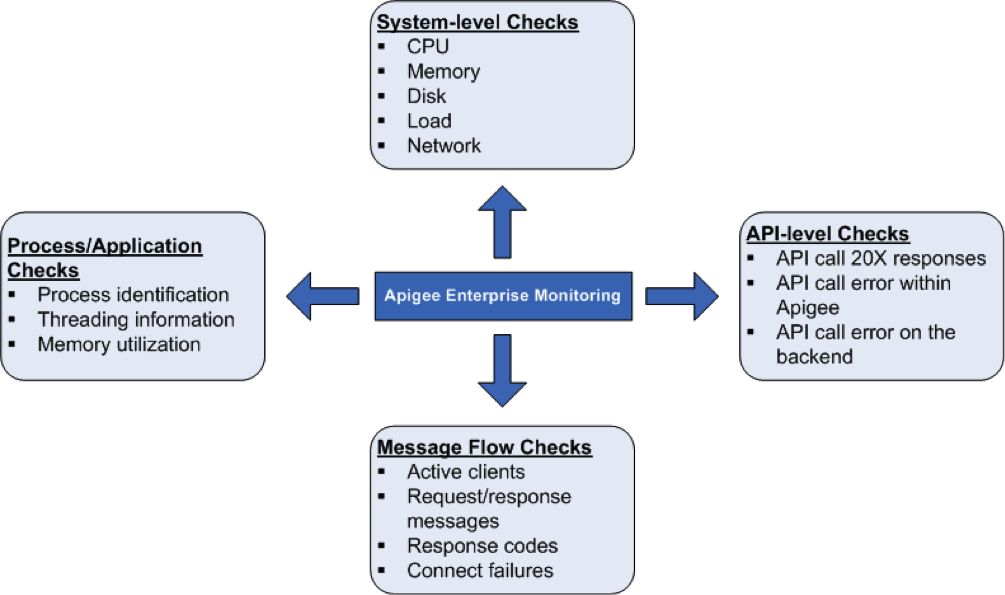
Systemzustandsprüfungen
Es ist sehr wichtig, die Parameter des Systemzustands wie CPU-Auslastung und Arbeitsspeicher und Portverbindung auf einer höheren Ebene. Sie können die folgenden Parameter überwachen, die Grundlagen des Systemzustands.
- CPU Utilization (CPU-Auslastung): Gibt die grundlegenden Statistiken an (User/System/IO). Warte/Inaktivität) zur CPU-Auslastung. Beispiel: die gesamte vom System verwendete CPU.
- Free/Used Memory: Gibt die Systemspeicherauslastung in Byte an. Zum Beispiel der vom System verwendete physische Arbeitsspeicher.
- Speicherplatznutzung: Gibt die Dateisysteminformationen an, basierend auf die aktuelle Laufwerksnutzung. Zum Beispiel der vom System belegte Festplattenspeicher.
- Load Average (Auslastungsdurchschnitt): Gibt die Anzahl der Prozesse an, ausführen.
- Netzwerkstatistik – Netzwerkpakete und/oder übertragene Byte zusammen mit den Übertragungsfehlern für eine bestimmte Komponente an.
Prozesse/Anwendungsprüfungen
Auf Prozessebene können Sie wichtige Informationen über alle Prozesse einsehen, ausgeführt wird. Dazu gehören beispielsweise Speicher- und CPU-Nutzungsstatistiken, die ein Prozess oder eine Anwendung verwendet. Für Prozesse wie qpidd, postgres postmaster, java usw. können Sie die Folgendes:
- Prozessidentifikation: Identifizieren Sie einen bestimmten Apigee-Prozess. Beispiel: können Sie überwachen, ob ein Apigee-Server-Java-Prozess vorhanden ist.
- Thread-Statistiken: Sehen Sie sich die zugrunde liegenden Threading-Muster an, die ein Prozess ausführt. verwendet werden. Sie können beispielsweise die maximale Thread-Anzahl und die Thread-Anzahl für alle Prozesse überwachen.
- Arbeitsspeicherauslastung: Sehen Sie sich die Arbeitsspeichernutzung für alle Apigee-Prozesse an. Sie können beispielsweise Parameter wie Heap-Speichernutzung und verwendete Nicht-Heap-Speichernutzung überwachen. durch einen Prozess.
Prüfungen auf API-Ebene
Auf API-Ebene lässt sich überprüfen, ob der Server für eine häufig verwendete API in Betrieb ist. von Apigee weitergeleitete Aufrufe. Sie können beispielsweise eine API-Prüfung auf dem Verwaltungsserver, dem Router, und Message Processor, indem sie den folgenden cURL-Befehl aufrufen:
curl http://<host>:<port>/v1/servers/self/up
Dabei ist <host> die IP-Adresse. Adresse der Apigee Edge-Komponente. Das <port> ist für jede Edge-Komponente spezifisch. Beispiel:
Verwaltungsserver: 8080
- Router: 8081
- Message Processor: 8082
- usw.
Informationen zum Ausführen dieses Befehls finden Sie in den folgenden Abschnitten. Komponente
Bei diesem Aufruf wird „true“ und „false“. Für optimale Ergebnisse können Sie auch API-Aufrufe direkt im Back-End, mit dem die Apigee-Software interagiert, um schnell zu ermitteln, Ob ein Fehler in der Apigee-Softwareumgebung oder im Backend vorliegt.
Hinweis: Zum Überwachen Ihrer API-Proxys können Sie auch API Health von Apigee verwenden. API Health macht geplante Aufrufe an Ihre API-Proxys und benachrichtigt Sie, wenn sie fehlschlagen und wie sie funktionieren. Bei erfolgreichen Aufrufen API Health zeigt Ihnen die Antwortzeiten an und kann Sie sogar benachrichtigen, wenn die Antwortlatenz hoch ist. API Gesundheit kann von verschiedenen Standorten weltweit aus Anrufe tätigen, um das API-Verhalten zwischen Regionen.
Überprüfungen des Nachrichtenflusses
Sie können Daten zum Nachrichtenfluss von Routern und Message Processor erfassen Muster/Statistiken. So können Sie Folgendes überwachen:
- Anzahl der aktiven Kunden
- Anzahl der Antworten (10-, 20-, 30-, 40- und 50-fache)
- Verbindungsfehler
Dies hilft Ihnen, Dashboards für den API-Nachrichtenfluss bereitzustellen. Weitere Informationen:
- Monitoring für den Message Processor
- Apigee-Monitoring-Dashboard (Beta) Router
Router-Systemdiagnose des Message Processor
Der Router implementiert einen Systemdiagnosemechanismus, um zu bestimmen, welcher der Message Processor wie erwartet funktioniert. Wenn ein Message Processor als ausgefallen oder langsam erkannt wird, kann der Router der Message Processor automatisch aus der Rotation. In diesem Fall schreibt der Router eine „Markdown“ an die Router-Protokolldatei unter /opt/apigee/var/log/edge-router/logs/system.log.
Sie können die Router-Protokolldatei auf diese Meldungen prüfen. Wenn der Router zum Beispiel eine Wenn der Message Processor nicht rotiert ist, schreibt er eine Nachricht im folgenden Format in das Protokoll:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
Dabei ist /<MP_IP>:<PORT> die IP-Adresse und Portnummer des Message Processor.
Wenn der Router später eine Systemdiagnose durchführt und feststellt, dass der Message Processor ordnungsgemäß funktioniert, setzt der Router den Message Processor automatisch wieder in Rotation. Die Der Router schreibt auch ein "Markup" an das Protokoll im folgenden Formular:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up