
Edge for Private Cloud w wersji 4.18.01
Zasadniczo w środowiskach produkcyjnych konieczne jest włączenie mechanizmów monitorowania Wdrożenie Apigee Edge na potrzeby chmury prywatnej. Te techniki monitorowania ostrzegają sieć administratorów (lub operatorów) błędu lub awarii. Każdy wygenerowany błąd jest zgłaszany jako w Apigee Edge. Więcej informacji o alertach znajdziesz w artykule Monitorowanie sprawdzonych metod.
Dla ułatwienia komponenty Apigee są klasyfikowane głównie na 2 kategorie:
- Usługi serwera Java w przypadku Apigee – obejmują między innymi usługi zarządzania Serwer, procesor wiadomości, serwer Qpid i serwer Postgres.
- Usługi innych firm – obejmują router Nginx, Apache Cassandra, Apache ZooKeeper, OpenLDAP, baza danych PostgreSQL i Qpid.
W przypadku lokalnego wdrożenia Apigee Edge poniżej znajdziesz parametry, które możesz monitorować:
|
Komponent |
Kontrole systemu |
Statystyki na poziomie procesu |
Testy na poziomie interfejsu API |
Kontrole przepływu wiadomości |
Informacje o komponencie |
|
|---|---|---|---|---|---|---|
|
Usługi Java specyficzne dla Apigee |
Serwer zarządzania |
? |
? |
? |
||
|
procesor komunikatów |
? |
? |
? |
? |
||
|
Serwer Qpid |
? |
? |
? |
|||
|
Serwer Postgres |
? |
? |
? |
|||
|
Usługi innych firm |
Apache Cassandra, |
? |
? |
|||
|
Apache ZooKeeper |
? |
? |
||||
|
OpenLDAP |
? |
? |
||||
|
Baza danych PostgreSQL |
? |
? |
||||
|
Qpid |
? |
? |
||||
|
Router Nginx |
? |
? |
? |
|||
Ogólnie po zainstalowaniu Apigee Edge możesz wykonywać te monitorowanie zadania do śledzenia wydajności instalacji Apigee Edge for Private Cloud.
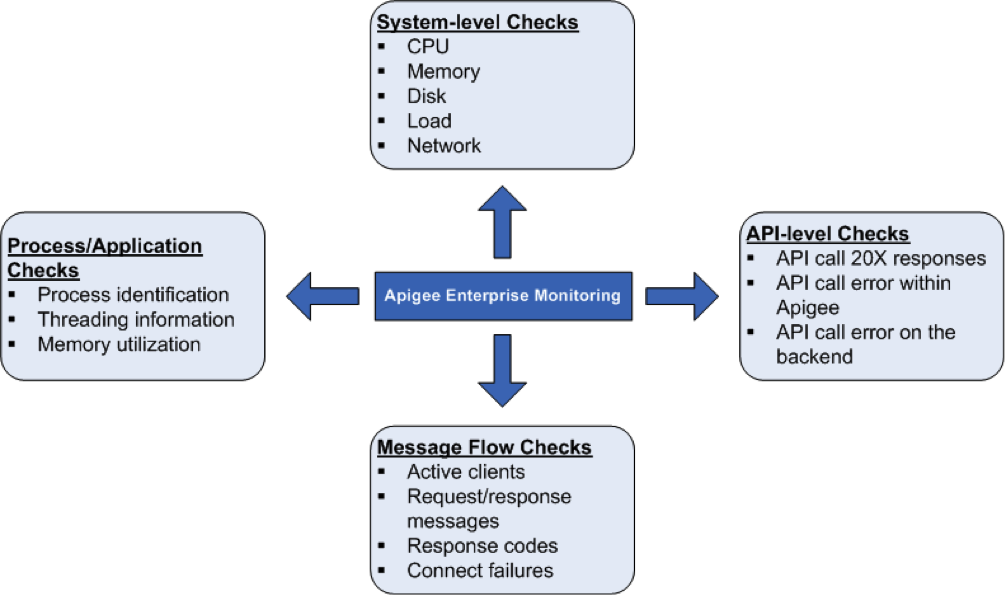
Kontrole stanu systemu
Pomiar parametrów stanu systemu, takich jak wykorzystanie procesora czy pamięci, jest bardzo ważny. wykorzystanie i połączenia portów na wyższym poziomie. Możesz monitorować poniższe parametry, aby: poznasz podstawy stanu systemu.
- CPU Wykorzystanie (Wykorzystanie procesora) – określa podstawowe statystyki (użytkownik/system/IO). Oczekiwanie/Brak aktywności) dotyczące wykorzystania procesora. Na przykład łączna liczba procesorów używanych przez system.
- wolna/używana pamięć – określa wykorzystanie pamięci systemowej w bajtach; Może to być na przykład pamięć fizyczna używana przez system.
- Wykorzystanie miejsca na dysku – określa informacje o systemie plików na podstawie danych. bieżące wykorzystanie dysku. Dotyczy to na przykład miejsca na dysku twardym wykorzystywanego przez system.
- LoadŚrednia – określa liczbę procesów oczekujących na bieganie.
- Statystyki sieci – pakiety sieciowe oraz bajty przesłane i oraz błędy transmisji określonego komponentu.
Procesy/weryfikacje zgłoszeń
Na poziomie procesu możesz wyświetlić ważne informacje o wszystkich procesach, które są w domu. Obejmują one na przykład statystyki wykorzystania pamięci i procesora i sposobu ich wykorzystania. W przypadku procesów takich jak qpidd, postgres postmaster, java itp. możesz monitorować :
- Identyfikacja procesu: zidentyfikuj konkretny proces Apigee. Przykład: możesz monitorować, czy istnieje proces Java serwera Apigee.
- Statystyki wątków: wyświetla podstawowe wzorce wątków, których używa proces. zastosowań. Możesz na przykład monitorować szczytową liczbę wątków i wątków we wszystkich procesach.
- Wykorzystanie pamięci: wyświetlanie wykorzystania pamięci przez wszystkie procesy Apigee. Możesz na przykład monitorować parametry takie jak wykorzystanie pamięci sterty czy wykorzystanie pamięci innej niż sterta proces.
Kontrole na poziomie interfejsu API
Na poziomie interfejsu API możesz monitorować, czy serwer dla często używanego interfejsu API jest uruchomiony i działa połączeń przesyłanych przez Apigee przez serwer proxy. Można na przykład sprawdzić interfejs API na serwerze zarządzania, routerze i procesora wiadomości, wywołując to polecenie cURL:
curl http://<host>:<port>/v1/servers/self/up
Gdzie <host> to adres IP. adresu komponentu Apigee Edge. <port> jest niepowtarzalny dla każdego komponentu Edge. Na przykład:
Serwer zarządzania: 8080
- Router: 8081
- Procesor komunikatów: 8082
- itd.
Informacje o uruchamianiu tego polecenia w przypadku każdego z nich znajdziesz w sekcjach poniżej składnik
To wywołanie zwraca wartość „true” (prawda) i „false”. Aby uzyskać najlepsze wyniki, możesz też wysyłać wywołania interfejsu API bezpośrednio w backendzie (z którym oprogramowanie Apigee współpracuje), aby szybko określić sprawdzić, czy błąd występuje w środowisku oprogramowania Apigee czy w backendzie.
Uwaga: do monitorowania serwerów proxy API możesz też użyć narzędzia Stan API w Apigee. Stan API Health sprawia, zaplanowanych wywołań do serwerów proxy interfejsu API oraz powiadamia Cię o niepowodzeniu i o tym, w jaki sposób. Po udanym wywołaniu Interfejs API Health pokazuje czas reakcji i może nawet Cię powiadomić o dużym czasie oczekiwania na odpowiedź. Interfejs API Zdrowie może wykonywać wywołania z różnych lokalizacji na całym świecie, aby porównywać zachowanie interfejsów API między i regionach.
Sprawdzanie przepływu wiadomości
Możesz zbierać dane dotyczące przepływu wiadomości od routerów i podmiotów przetwarzających wiadomości wzorcem/statystykami. Dzięki temu możesz monitorować:
- Liczba aktywnych klientów
- Liczba odpowiedzi (10X, 20X, 30X, 40X i 50X)
- Nieudane połączenia
Ułatwia to udostępnienie paneli informacyjnych dla przepływu komunikatów interfejsu API. Więcej informacji:
- Jak monitorować pod kątem procesora wiadomości
- Panel Apigee Monitoring w wersji beta Omówienie routera
Kontrola stanu routera procesora wiadomości
Router wdraża mechanizm kontroli stanu w celu określenia, które procesory wiadomości. działają zgodnie z oczekiwaniami. W przypadku wykrycia, że procesor wiadomości nie działa lub wolno działa, router może automatycznie wyłączy procesor wiadomości z rotacji. W takim przypadku router zapisuje „Znacznik” do pliku dziennika routera pod adresem /opt/apigee/var/log/edge-router/logs/system.log.
Możesz monitorować plik dziennika routera pod kątem tych komunikatów. Jeśli na przykład router pobierze Procesor wiadomości poza rotacją zapisuje komunikat w logu w postaci:
2014-05-06 15:51:52,159 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now DISCONNECTED. handle = <MP_IP> at 1399409512159 2014-04-17 12:54:48,512 org: env: nioEventLoopGroup-2-2 INFO HEARTBEAT - HBTracker.gotResponse() : No HeartBeat detected from /<MP_IP>:<PORT> Mark Down
gdzie /<MP_IP>:<PORT> to adres IP, a numeru portu procesora wiadomości.
Jeśli później router przeprowadzi kontrolę stanu i ustali, że procesor wiadomości działa poprawnie, router automatycznie przełącza procesor wiadomości z powrotem w rotację. Router zapisuje również znaczniki do dziennika w formularzu:
2014-05-06 16:07:29,054 org: env: RPCClientClientProtocolChildGroup-RPC-0 INFO CLUSTER - ServerState.setState() : State of 2a8a0e0c-3619-416f-b037-8a42e7ad4577 is now CONNECTED. handle = <IP> at 1399410449054 2014-04-17 12:55:06,064 org: env: nioEventLoopGroup-4-1 INFO HEARTBEAT - HBTracker.updateHB() : HeartBeat detected from /<IP>:<PORT> Mark Up