
Wyświetlasz dokumentację Apigee Edge.
Otwórz dokumentację Apigee X. info
Warunki alertu definiują konkretny kod stanu (np. 404/502/2xx/4xx/5xx), opóźnienie i wartości progowe kodu błędu, które po przekroczeniu uruchamiają wizualne alerty w interfejsie użytkownika i wysyłają powiadomienia przez różne kanały, takie jak e-mail, Slack, pagerduty czy webhooki. Alerty możesz konfigurować na poziomie środowiska, serwera proxy API, usługi docelowej lub regionu. Gdy zostanie uruchomiony alert, otrzymasz powiadomienie za pomocą metody zdefiniowanej podczas dodawania alertów i powiadomień.
Możesz na przykład wywołać alert i wysłać powiadomienie do zespołu operacyjnego, gdy współczynnik błędów 5xx przekroczy 23% przez okres 5 minut w przypadku serwera proxy interfejsu API orders-prod wdrożonego w środowisku produkcyjnym.
Na rysunku poniżej widać, jak alerty wyświetlają się w interfejsie:
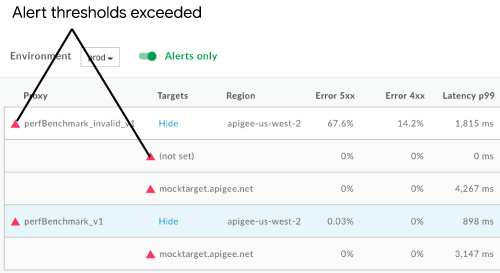
Poniżej znajdziesz przykład powiadomienia e-mail, które możesz otrzymać, gdy zostanie uruchomiony alert.
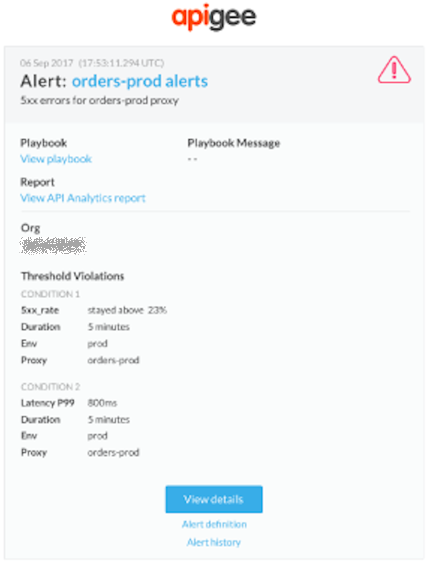
Aby dowiedzieć się więcej, w treści powiadomienia kliknij te linki:
- Wyświetl szczegóły, aby zobaczyć więcej szczegółów, w tym ustawienia alertu i aktywność dla każdego stanu w ciągu ostatniej godziny.
- Definicja alertu – aby wyświetlić definicję alertu.
- Historia alertów, aby wyświetlić więcej informacji o konkretnym alarmie.
- Wyświetl scenariusz, aby zobaczyć zalecane działania (jeśli są dostępne).
- Wyświetl raport Analytics API, aby wyświetlić raport niestandardowy dla warunku alertu.
W kolejnych sekcjach znajdziesz instrukcje konfigurowania alertów i powiadomień oraz zarządzania nimi.
Typy alertów
Pierwsza wersja Monitorowania interfejsu API umożliwia tworzenie reguł opartych na wzorach, które określają, kiedy należy wysłać alert na podstawie zestawu wstępnie zdefiniowanych warunków. Tego typu alerty nazywamy stałymi i były one jedynym typem alertów obsługiwanych w pierwszej wersji Monitorowania interfejsu API.
Możesz na przykład ustawić stały alert, gdy:
- [wskaźnik błędów 5xx] [jest większy niż] [10%] przez [10 minut] z [target mytarget1]
- [liczba błędów 2xx] [jest mniejsza niż] [50] [przez 5 minut] w [regionie us-east-1]
- [p90 latency] [is greater than] [750ms] for [10 minutes] on [proxy myproxy1]
Wersja beta 19.11.13 raportowania zagrożeń zawiera nowe typy alertów:
- alerty Całkowity ruch (beta). Typ alertu, który umożliwia wysyłanie alertów, gdy ruch zmienia się o określony odsetek w danym przedziale czasu.
- alerty Anomalii (beta). Typ alertu, w którym Edge wykrywa problemy z ruchu i wydajnością, zamiast wymagać od Ciebie ich wcześniejszego określenia. Możesz wtedy wysłać alert dotyczący tych anomalii.
- alerty TLS Expiry (Beta). Typ alertu, który umożliwia wysyłanie powiadomień, gdy kończy się ważność certyfikatu TLS.
Monitorowanie interfejsu API obsługuje teraz wiele typów alertów, dlatego w oknie dialogowym Utwórz alert wyświetla się opcja wyboru typu alertu:
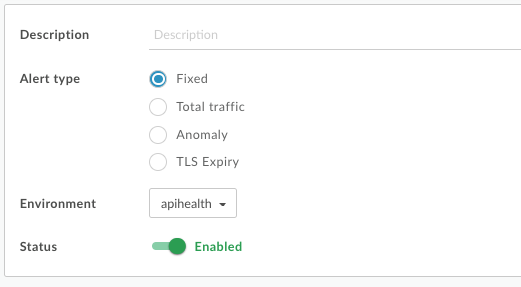
Wyświetlanie ustawień alertów
Aby wyświetlić aktualnie zdefiniowane ustawienia alertów, w interfejsie Edge kliknij Analizuj > Reguły alertów.
Wyświetli się strona Alert, jak pokazano na rysunku poniżej:
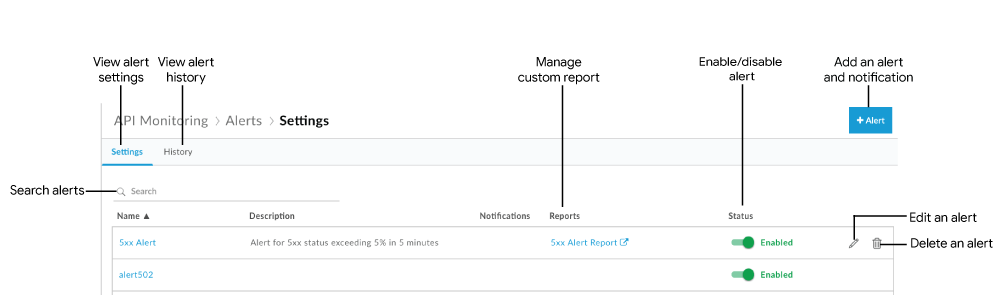
Jak widać na rysunku, na stronie Alert możesz:
- wyświetlić podsumowanie aktualnie zdefiniowanych ustawień alertów.
- wyświetlać historię alertów, które zostały aktywowane;
- Dodawanie alertów i powiadomień
- Tworzenie raportu niestandardowego na podstawie alertu
- Włączanie i wyłączanie alertu
- Edytowanie alertu
- Usuwanie alertu
- wyszukiwanie na liście alertów określonego ciągu znaków;
Wyświetlanie historii alertów, które zostały wyzwolone w organizacji
Aby wyświetlić historię alertów, które zostały wyzwolone w Twojej organizacji w ciągu ostatnich 24 godzin, w interfejsie Edge kliknij Analizuj > Reguły alertów, a potem kliknij kartę Historia.
Pojawi się strona Historia alertów.
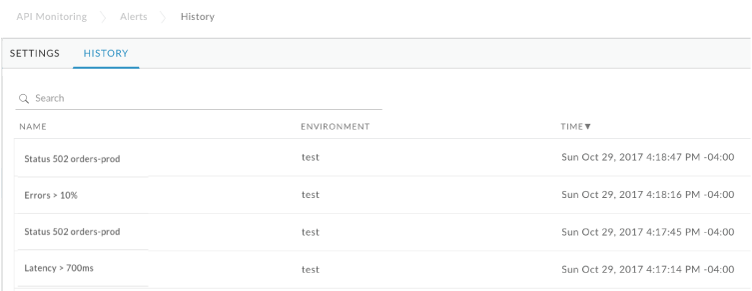
Kliknij nazwę alertu, aby wyświetlić jego szczegóły na panelu zbadania. Możesz filtrować listę, wyszukując całą nazwę alertu lub jej część.
Dodawanie alertów i powiadomień
Aby dodać alerty i powiadomienia:
- W interfejsie Edge kliknij Analizuj > Reguły alertów.
- Kliknij +Alert.
- Podaj te ogólne informacje o alertach:
Pole Opis Nazwa alertu Nazwa alertu. Użyj nazwy, która opisuje regułę i będzie dla Ciebie łatwa do zapamiętania. Nazwa nie może mieć więcej niż 128 znaków. Typ alertu Wybierz Stałe. Więcej informacji o typach alertów znajdziesz w artykule Typy alertów. Opis Opis alertu. Środowisko Wybierz środowisko z listy. Stan Przełącz, aby włączyć lub wyłączyć alert. - Zdefiniuj dane, próg i wymiar dla pierwszego warunku, który spowoduje uruchomienie alertu.
Pole warunku Opis Dane Wybierz jeden z tych rodzajów danych:
Kod stanu: wybierz z listy kod stanu, np. 401, 404, 2xx, 4xx lub 5xx HTTP.
Uwaga:
- Interfejs API umożliwia ustawienie większej liczby kodów stanu. Użyj interfejsu API, aby określić dowolny kod stanu w zakresie 200–299, 400–599 oraz wartości zastępcze 2xx, 4xx lub 5xx. Zobacz Tworzenie alertu.
- W przypadku alertów dotyczących ograniczania szybkości (kod stanu HTTP 429) ustaw dane na kod błędu Spike Arrest.
- Możesz użyć zapisu w zasadach przypisywania wiadomości, aby zastąpić kod odpowiedzi HTTP, który pochodzi z błędu serwera proxy lub docelowego. Monitorowanie interfejsu API ignoruje wszystkie zastąpione kody i rejestruje rzeczywiste kody odpowiedzi HTTP.
- Opóźnienie: wybierz wartość opóźnienia z listy. Dokładnie: p50 (50 centyl), p90 (90 centyl), p95 (95 centyl) lub p99 (99 centyl). Na przykład, aby skonfigurować alert, który będzie się uruchamiał, gdy czas oczekiwania dla 95 procentyla jest większy niż ustawiony poniżej próg, wybierz p95.
Kod błędu: wybierz kategorię, podkategorię i kod błędu z listy. Możesz też wybrać jedną z tych opcji w ramach kategorii lub podkategorii:
- Wszystkie – łączna liczba błędów we wszystkich kodach błędów w danej kategorii lub podkategorii musi spełniać kryteria danych.
- Dowolny – kod pojedynczego błędu w danej kategorii lub podkategorii musi spełniać kryteria danych.
Więcej informacji znajdziesz w tabeli kodów błędów.
- Cały ruch (wersja beta): wybierz wzrost lub spadek ruchu. Więcej informacji znajdziesz w artykule o alertach o ruchu (beta).
Próg Skonfiguruj próg dla wybranego wskaźnika:
- Kod stanu: ustaw próg jako procent, liczbę lub transakcje na sekundę (TPS) w czasie.
- Opóźnienie: wybierz próg jako łączny lub docelowy czas opóźnienia (ms) w czasie. W tym przypadku alert jest wywoływany, jeśli określony centyl obserwowanego opóźnienia, który jest aktualizowany co minutę, jeśli występuje ruch, przekracza warunek progowy w okresie obejmującym określony czas trwania. Oznacza to, że warunek progowy nie jest agregowany przez cały okres.
- Kod błędu: ustaw próg jako procent, liczbę lub transakcje na sekundę (TPS) w czasie.
Wymiar Kliknij + Dodaj wymiar i określ szczegóły wymiaru, dla których mają być zwracane wyniki, w tym serwer proxy interfejsu API, usługa docelowa lub aplikacja dewelopera oraz region. Jeśli dla konkretnego wymiaru ustawisz:
- Wszystkie – wszystkie elementy w wymiarze muszą spełniać kryteria danych. W przypadku danych typu Opóźnienie nie możesz wybrać opcji Wszystkie.
- Dowolny – dotyczy tylko regionu. Element w wymiarze musi spełniać kryteria danych w przypadku dowolnego regionu.
Uwaga: w przypadku usług pośredniczących API lub usług docelowych wybierz kolekcję, aby obsługiwać dowolną funkcjonalność. - Kolekcje – wybierz z listy kolekcją, aby określić zestaw serwerów proxy interfejsu API lub usług docelowych. W tym przypadku każdy element w kolekcji musi spełniać kryteria.
Jeśli ustawisz wymiar na Docelowy, możesz wybrać usługę docelową lub usługę określoną przez Zasady dotyczące podkreślenia usługi. Docelowy adres zasad dotyczących wywołania usługi jest wyświetlany jako wartość z prefiksem „sc://”. Przykład: „sc://mój.adres.internetowy”.
- Kliknij Pokaż dane o warunkach, aby wyświetlić najnowsze dane o warunkach w ciągu ostatniej godziny.
Na wykresie częstotliwość błędów jest wyświetlana na czerwono, gdy przekracza próg warunków alertu.
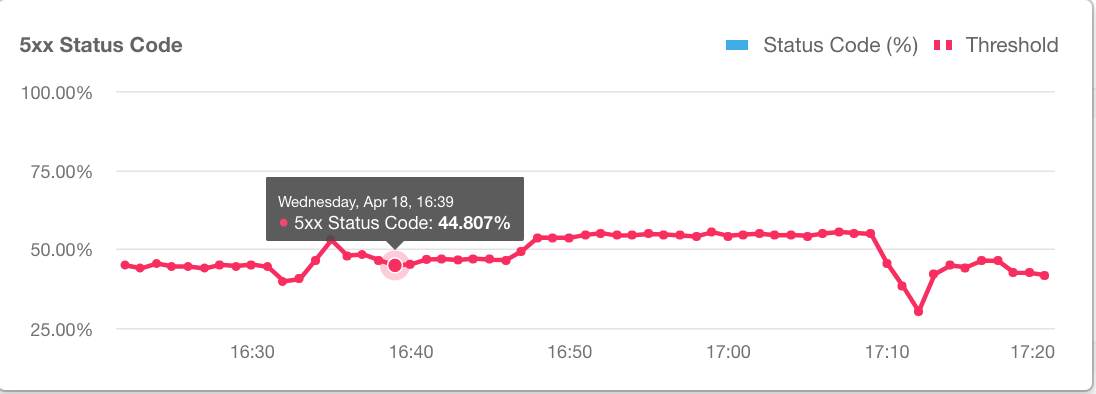
Aby ukryć dane, kliknij Ukryj dane warunków.
- Aby dodać kolejne warunki, kliknij + Dodaj warunek i powtórz kroki 4 i 5.
Uwaga: jeśli określisz kilka warunków, alert zostanie wyzwolony, gdy wszystkie warunki zostaną spełnione.
Jeśli chcesz utworzyć raport niestandardowy na podstawie skonfigurowanych warunków alertu, kliknij Utwórz raporty analityczne interfejsu API na podstawie warunków alertu. Ta opcja jest wyszarzona, jeśli nie jesteś administratorem organizacji.
Więcej informacji znajdziesz w artykule [GA4] Tworzenie raportu niestandardowego na podstawie alertu.
Uwaga: po zapisaniu alertu możesz zmodyfikować raport niestandardowy zgodnie z opisem w artykule Zarządzanie raportami niestandardowymi.
- Aby dodać powiadomienie o alertach, kliknij + Powiadomienie.
Szczegóły powiadomienia Opis Kanał Wybierz kanał powiadomień, którego chcesz użyć, i określ miejsce docelowe: e-mail, Slack, PagerDuty lub webhook. Miejsce docelowe Określ miejsce docelowe na podstawie wybranego typu kanału: - E-mail – adres e-mail, np.
joe@company.com - Slack – adres URL kanału Slack, np.
https://hooks.slack.com/services/T00000000/B00000000/XXXXX - PagerDuty – kod PagerDuty, np.
abcd1234efgh56789 Webhook – adres URL webhooka, np.
https://apigee.com/test-webhook. Opis obiektu wysyłanego na adres URL znajdziesz w formacie obiektu webhooka.Przekaz informacje o danych logowania w adresie URL webhooka. Przykład:
https://apigee.com/test-webhook?auth_token=1234_abcd.Możesz podać adres URL punktu końcowego, który może przeanalizować obiekt webhook, aby go zmodyfikować lub przetworzyć. Możesz na przykład podać adres URL interfejsu API, takiego jak interfejs API Edge, lub dowolnego innego punktu końcowego, który może przetworzyć obiekt.
Uwaga: w powiadomieniu możesz określić tylko jeden cel. Aby określić wiele miejsc docelowych dla tego samego typu kanału, dodaj dodatkowe powiadomienia.
- E-mail – adres e-mail, np.
- Aby dodać kolejne powiadomienia, powtórz krok 8.
- Jeśli dodasz powiadomienie, ustaw te pola:
Pole Opis Poradnik (Opcjonalnie) Pole tekstowe, w którym można podać krótki opis zalecanych działań, które należy wykonać, aby rozwiązać problemy, gdy wystąpią. Możesz też podać link do wewnętrznej strony wiki lub strony społeczności, na której znajdziesz sprawdzone metody. Informacje w tym polu zostaną uwzględnione w powiadomieniu. Treść w tym polu nie może przekraczać 1500 znaków. Ograniczenie Częstotliwość wysyłania powiadomień. Wybierz wartość z listy. Prawidłowe wartości to: 15 minut, 30 minut i 1 godzina. - Kliknij Zapisz.
Format obiektu webhooka
Jeśli jako miejsce docelowe powiadomienia o alertach podasz adres URL webhooka, obiekt wysłany pod ten adres ma taki format:{ "alertInstanceId": "event-id", "alertName": "name", "org": "org-name", "description": "alert-description", "alertId": "alert-id", "alertTime": "alert-timestamp", "thresholdViolations":{"Count0": "Duration=threshold-duration Region=region Status Code=2xx Proxy=proxy Violation=violation-description" }, "thresholdViolationsFormatted": [ { "metric": "count", "duration": "threshold-duration", "proxy": "proxy", "region": "region", "statusCode": "2xx", "violation": "violation-description" } ], "playbook": "playbook-link" }
Właściwości thresholdViolations i thresholdViolationsFormatted zawierają szczegóły dotyczące alertu. Właściwość thresholdViolations zawiera pojedynczy ciąg znaków z szczegółami, a właściwość thresholdViolationsFormatted zawiera obiekt opisujący alert.
Zwykle używasz właściwości thresholdViolationsFormatted, ponieważ jest ona łatwiejsza do odkodowania.
Powyższy przykład pokazuje zawartość tych właściwości w przypadku stałego alertu, gdy skonfigurujesz dane alertu, aby były wywoływane na podstawie kodu stanu HTTP 2xx, jak wskazuje właściwość statusCode.
Treść tych właściwości zależy od typu alertu (np. stały lub nietypowy) oraz konkretnej konfiguracji alertu.
Jeśli np. utworzysz stały alert na podstawie kodu błędu, usługa thresholdViolationsFormatted będzie zawierać usługę faultCode, a nie usługę statusCode.
W tabeli poniżej przedstawiono wszystkie możliwe wartości właściwości thresholdViolationsFormatted w przypadku różnych typów alertów:
| Typ alertu | Możliwy prógBłędyFormatowanie treści |
|---|---|
| Nieruchomo | metric, proxy, target, developerApp, region, statusCode, faultCodeCategory, faultCodeSubCategory, faultCode, percentile, comparisonType, thresholdValue, triggerValue, duration, violation |
| Łączny ruch | metric, proxy, target, developerApp, region, comparisonType, thresholdValue, triggerValue, duration, violation |
| Anomalia | metric, proxy, target, region, statusCode, faultCode, percentile, sensitivity, violation |
| Wygaśnięcie TLS | envName, certificateName, thresholdValue, violation |
Tworzenie raportu niestandardowego na podstawie alertu
Aby utworzyć raport niestandardowy na podstawie alertu:
- Podczas tworzenia alertu kliknij Utwórz raporty analityczne API na podstawie warunków alertu, jak opisano w artykule Dodawanie alertów i powiadomień.
Po zapisaniu alertu w interfejsie pojawi się komunikat:
Alert alertName saved successfully. To customize the report generated, click here.
Kliknij wiadomość, aby otworzyć raport w nowej karcie z odpowiednimi polami wypełnionymi wstępnie. Domyślna nazwa raportu niestandardowego to:
API Monitoring Generated alertName - Edytuj raport niestandardowy według potrzeb, a potem kliknij Zapisz.
- Kliknij nazwę raportu na liście i wygeneruj raport niestandardowy.
Aby zarządzać raportem niestandardowym utworzonym na podstawie warunków alertu:
- W interfejsie Edge kliknij Analizuj > Reguły alertów.
- Kliknij kartę Ustawienia.
- W kolumnie Raporty kliknij raport niestandardowy powiązany z alertem, którym chcesz zarządzać.
Strona raportu niestandardowego otworzy się w nowej karcie. Jeśli kolumna Raporty jest pusta, raport niestandardowy nie został jeszcze utworzony. Możesz edytować alert, aby w razie potrzeby dodać raport niestandardowy.
- Edytuj raport niestandardowy według potrzeb, a potem kliknij Zapisz.
- Kliknij nazwę raportu na liście i wygeneruj raport niestandardowy.
Włączanie i wyłączanie alertu
Aby włączyć lub wyłączyć alert:
- W interfejsie Edge kliknij Analizuj > Reguły alertów.
- Kliknij przełącznik w kolumnie Stan obok alertu, który chcesz włączyć lub wyłączyć.

Edycja alertu
Aby edytować alert:
- W interfejsie Edge kliknij Analizuj > Reguły alertów.
- Kliknij nazwę alertu, który chcesz edytować.
- W razie potrzeby zmodyfikuj alert.
- Kliknij Zapisz.
Usuwanie alertu
Aby usunąć alert:
- W interfejsie Edge kliknij Analizuj > Reguły alertów.
- Najedź kursorem na alert, który chcesz usunąć, i w menu czynności kliknij
 .
.
Sugerowane alerty
Apigee zaleca skonfigurowanie poniższych alertów, aby otrzymywać powiadomienia o typowych problemach. Niektóre z tych alertów dotyczą implementacji interfejsów API i są przydatne tylko w określonych sytuacjach. Na przykład niektóre z alertów wyświetlanych poniżej są ważne tylko wtedy, gdy używasz zasad dotyczących ServiceCallout lub zasad dotyczących JavaCallout.
| Alert | Przykład interfejsu | Przykład interfejsu API |
|---|---|---|
| Kody stanu 5xx dla wszystkich interfejsów API | Konfigurowanie alertu o kodzie stanu 5xx dla serwera proxy interfejsu API | Konfigurowanie alertu o kodzie stanu 5xx dla serwera proxy interfejsu API za pomocą interfejsu API |
| Czas oczekiwania (95 centyl) na proxy interfejsu API | Konfigurowanie alertu dotyczącego czasu oczekiwania P95 w przypadku serwera proxy interfejsu API | Konfigurowanie alertu o czasie oczekiwania P95 dla serwera proxy interfejsu API za pomocą interfejsu API |
| Kody stanu 404 (nie znaleziono aplikacji) dla wszystkich serwerów proxy API | Konfigurowanie alertu o kodzie stanu 404 (nie znaleziono aplikacji) dla wszystkich serwerów pośredniczących API | Konfigurowanie alertu o kodzie stanu 404 (nie znaleziono aplikacji) dla wszystkich serwerów proxy interfejsu API korzystających z tego interfejsu |
| Liczba proxy interfejsów API | Konfigurowanie alertu dotyczącego liczby serwerów proxy interfejsu API | Konfigurowanie alertu dotyczącego liczby serwerów proxy interfejsu API dla interfejsów API korzystających z interfejsu API |
| Częstotliwość występowania błędów w usługach docelowych | Konfigurowanie alertu o częstotliwości występowania błędów w przypadku usług docelowych | Konfigurowanie alertu o częstotliwości błędów dla usług docelowych za pomocą interfejsu API |
| Częstotliwość występowania błędów w przypadku zasad dotyczących powiadomień o usługach (w stosownych przypadkach) | Konfigurowanie alertu o częstotliwości błędów w przypadku zasady ServiceCallout | Konfigurowanie alertu o częstotliwości błędów dla zasady ServiceCallout za pomocą interfejsu API |
konkretne kody błędów, w tym:
|
Konfigurowanie alertu o kodzie błędu zasad | Konfigurowanie alertu o kodzie błędu zasad za pomocą interfejsu API |
Konfigurowanie alertu o kodzie stanu 5xx dla proxy interfejsu API
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy liczba transakcji na sekundę (TPS) kodów stanu 5xx w przypadku usługi proxy interfejsu API hoteli przekroczy 100 przez 10 minut w dowolnym regionie. Więcej informacji znajdziesz w artykule Dodawanie alertów i powiadomień.
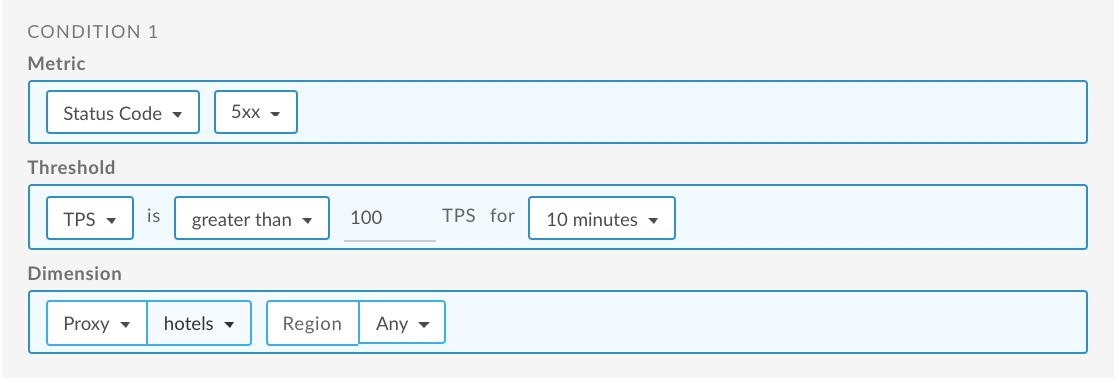
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu o kodzie stanu 5xx dla serwera proxy za pomocą interfejsu API.
Konfigurowanie alertu o czasie oczekiwania P95 dla serwera proxy interfejsu API
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy łączny czas oczekiwania na odpowiedź dla 95 procentyla przekracza 100 ms przez 5 minut w przypadku usługi proxy interfejsu API hoteli w dowolnym regionie. Więcej informacji znajdziesz w artykule Dodawanie alertów i powiadomień.
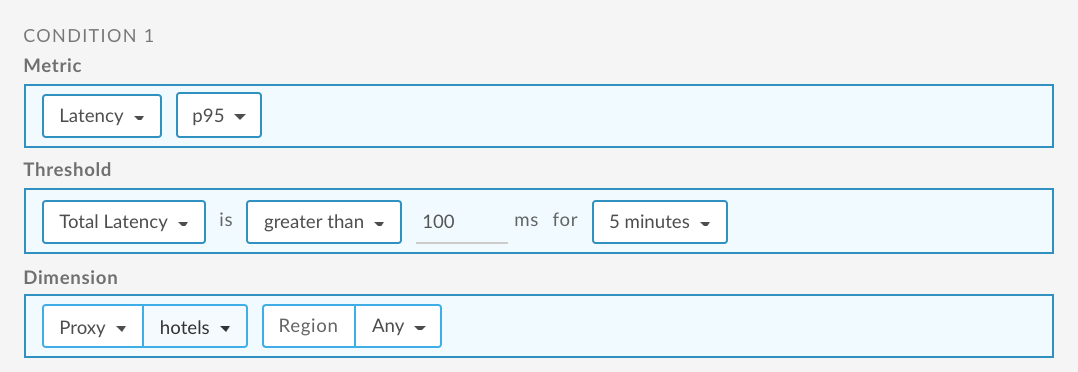
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu o opóźnieniu P95 dla serwera proxy interfejsu API za pomocą interfejsu API.
Konfigurowanie alertu 404 (nie znaleziono aplikacji) dla wszystkich serwerów proxy interfejsu API
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy odsetek kodów stanu 404 dla wszystkich proxy interfejsu API przekroczy 5% przez 5 minut w dowolnym regionie. Więcej informacji znajdziesz w artykule Dodawanie alertów i powiadomień.
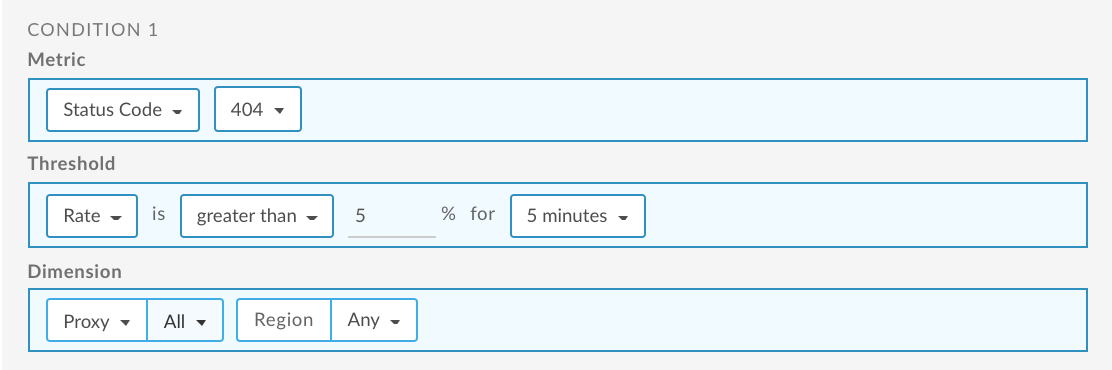
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu o błędzie 404 (nie znaleziono aplikacji) dla wszystkich serwerów proxy interfejsu API za pomocą interfejsu API.
Konfigurowanie alertu dotyczącego liczby wywołań proxy interfejsu API
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy liczba kodów 5xx dla interfejsów API przekroczy 200 w ciągu 5 minut w dowolnym regionie. W tym przykładzie interfejsy API są rejestrowane w zbiorze proxy interfejsów API o wysokiej dostępności. Aby dowiedzieć się więcej, zobacz:
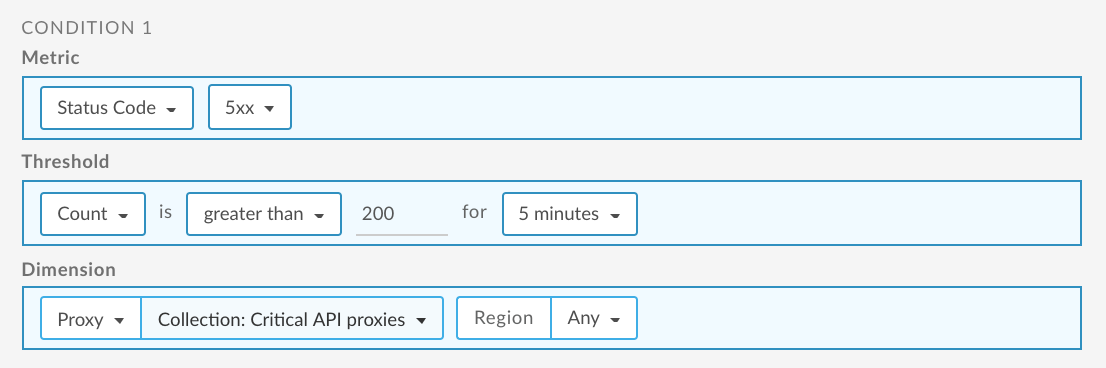
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu dotyczącego liczby serwerów proxy interfejsu API dla interfejsów API korzystających z interfejsu API.
Konfigurowanie alertu dotyczącego odsetka błędów w usługach docelowych
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy współczynnik kodu 500 w przypadku usług docelowych przekroczy 10% przez 1 godzinę w dowolnym regionie. W tym przykładzie usługi docelowe są uwzględnione w kolekcji Krytyczne cele. Aby dowiedzieć się więcej, zobacz:
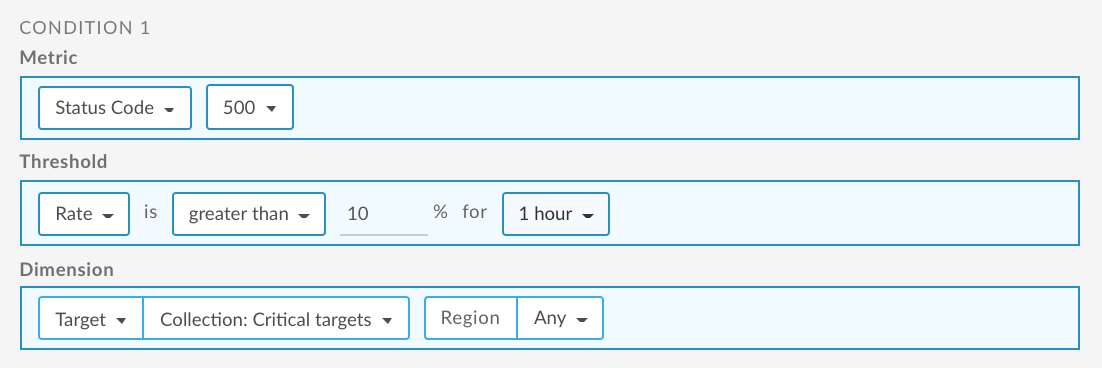
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu o częstości błędów dla usług docelowych za pomocą interfejsu API.
Konfigurowanie alertu dotyczącego współczynnika błędów w przypadku zasady dotyczącej powiadomień o problemach z usługą
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy współczynnik kodu 500 usługi określonej przez zasadę ServiceCallout przekroczy 10% przez 1 godzinę w dowolnym regionie. Aby dowiedzieć się więcej, zobacz:
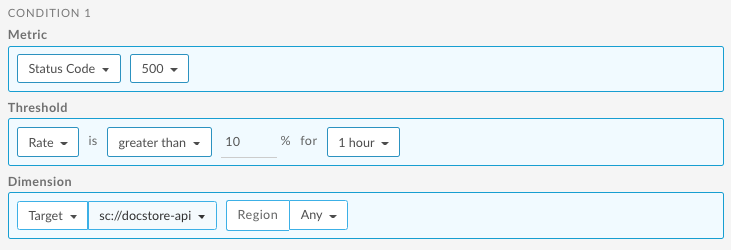
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu o częstości błędów w ramach zasad dotyczących powiadomień o problemach z usługą za pomocą interfejsu API.
Konfigurowanie alertu o kodzie błędu zasad
Poniżej znajdziesz przykładowy sposób konfigurowania alertu za pomocą interfejsu użytkownika, który jest uruchamiany, gdy JWT AlgorithmMismatch liczba kodów błędów dla reguły VerifyJWT jest większa niż 5 przez 10 minut w przypadku wszystkich interfejsów API.
Aby dowiedzieć się więcej, zobacz:
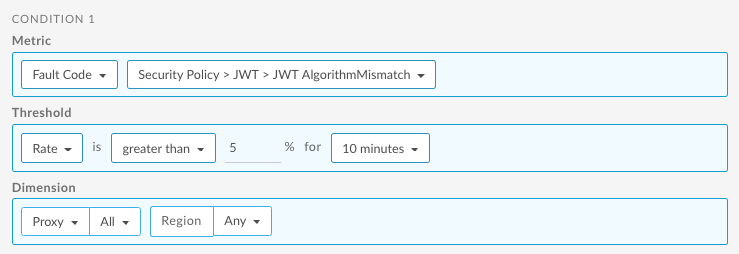
Informacje o korzystaniu z interfejsu API znajdziesz w artykule Konfigurowanie alertu o błędach kodu zasad za pomocą interfejsu API.