
คุณกําลังดูเอกสารประกอบของ Apigee Edge
ไปที่เอกสารประกอบของ Apigee X info
การตรวจสอบ API ช่วยให้คุณสร้างกฎตามรูปแบบที่จะทริกเกอร์การแจ้งเตือนตามชุดเงื่อนไขที่กำหนดไว้ล่วงหน้าได้ การแจ้งเตือนประเภทนี้เรียกว่าการแจ้งเตือนแบบแก้ไข และเป็นประเภทการแจ้งเตือนเดียวที่รองรับในรุ่นแรกของการตรวจสอบ API
เช่น คุณสามารถส่งการแจ้งเตือนแบบคงที่เมื่อเกิดเหตุการณ์ต่อไปนี้
- [อัตราข้อผิดพลาด 5xx] [มากกว่า] [10%] เป็นเวลา [10 นาที] จาก [target mytarget1]
- [จำนวนข้อผิดพลาด 2xx] [น้อยกว่า] [50] สำหรับ [5 นาที] ใน [ภูมิภาค us-east-1]
- [เวลาในการตอบสนอง p90] [มากกว่า] [750 มิลลิวินาที] เป็นเวลา [10 นาที] ใน [proxy myproxy1]
เมื่อเป็นไปตามเงื่อนไขของการแจ้งเตือนที่แก้ไขแล้ว การตรวจสอบ API จะส่งการแจ้งเตือนเพื่อแจ้งให้คุณทราบถึงปัญหา อย่างไรก็ตาม คุณต้องกำหนดเงื่อนไขการแจ้งเตือนที่เฉพาะเจาะจงก่อนเพื่อให้การตรวจสอบ API ส่งการแจ้งเตือนได้
แม้ว่าการแจ้งเตือนแบบคงที่จะมีคุณค่า แต่การกำหนดเกณฑ์ที่เหมาะสมสำหรับเงื่อนไขหนึ่งๆ ก็อาจเป็นเรื่องยากเนื่องจากรูปแบบการเข้าชมจะเปลี่ยนแปลงเมื่อเวลาผ่านไป เช่น หากคุณตั้งค่าเกณฑ์ต่ำเกินไป คุณจะได้รับการแจ้งเตือนจำนวนมาก หากคุณตั้งค่าเกณฑ์ไว้สูงเกินไป คุณอาจพลาดปัญหาร้ายแรงหรือการหยุดทำงานบางอย่าง
การตรวจจับความผิดปกติ
การตรวจหาความผิดปกติช่วยให้ Edge ตรวจหาปัญหาการเข้าชมและประสิทธิภาพแทนที่คุณต้องกำหนดไว้ล่วงหน้าด้วยตนเอง Edge จะค้นหาเงื่อนไขที่ผิดปกติโดยอัตโนมัติในระดับองค์กร สภาพแวดล้อม และภูมิภาค เมื่อตรวจพบ ระบบจะบันทึกความผิดปกติเพื่อแสดงในแดชบอร์ดเหตุการณ์ใน UI ของ Edge
การตรวจหาความผิดปกติทํางานโดยใช้โมเดลปัญญาประดิษฐ์ (AI) และแมชชีนเลิร์นนิง (ML) กับข้อมูล API ที่ผ่านมา จากนั้นการตรวจหาความผิดปกติจะส่งการแจ้งเตือนแบบเรียลไทม์สำหรับสถานการณ์ที่คุณไม่เคยคิดถึงมาก่อน เพื่อปรับปรุงประสิทธิภาพการทำงานและลดเวลาเฉลี่ยในการแก้ปัญหา (MTTR) ของปัญหา API
ตัวอย่างความผิดปกติที่ตรวจพบอาจรวมถึงกรณีที่รุ่น API ใหม่ทําให้การเข้าชมเพิ่มขึ้นอย่างรวดเร็วโดยไม่คาดคิดและเวลาในการตอบสนองของ API เพิ่มขึ้นตามไปด้วย หรือรุ่นที่กําหนดค่าไม่ถูกต้องในแบ็กเอนด์ทําให้ข้อผิดพลาดแบ็กเอนด์ที่ API รายงานเพิ่มขึ้น
ความผิดปกติที่ตรวจพบจะมีข้อมูลต่อไปนี้
- เมตริกที่ทําให้เกิดความผิดปกติ เช่น เวลาในการตอบสนองของพร็อกซีหรือรหัสข้อผิดพลาด HTTP
- เกณฑ์ของความผิดปกติ ซึ่งอาจเป็นเล็กน้อย ปานกลาง หรือรุนแรง
ตัวอย่างเช่น Edge สามารถตรวจหาความผิดปกติต่างๆ โดยอัตโนมัติ เช่น
- [เพิ่มขึ้นเล็กน้อย] [ข้อผิดพลาด 503 เพิ่มขึ้น] ใน [environment prod, region region1]
- [ปานกลาง] [ข้อผิดพลาด 4xx เพิ่มขึ้น] ใน [environment prod, region region2]
- [ร้ายแรง] [เวลาในการตอบสนองเพิ่มขึ้น] ใน [environment prod, region region3]
จากข้อมูลความผิดปกติที่แสดงในแดชบอร์ดเหตุการณ์ คุณสามารถสร้างการแจ้งเตือนประเภทใหม่ได้ ซึ่งเรียกว่าการแจ้งเตือนความผิดปกติ เพื่อแจ้งให้คุณทราบถึงเงื่อนไขเหล่านี้
ประเภทความผิดปกติ
Edge จะตรวจหาความผิดปกติประเภทต่อไปนี้โดยอัตโนมัติ
- ข้อผิดพลาด HTTP 503 เพิ่มขึ้นที่ระดับองค์กร สภาพแวดล้อม และภูมิภาค
- เกิดข้อผิดพลาด HTTP 504 มากขึ้นที่ระดับองค์กร สภาพแวดล้อม และภูมิภาค
- เกิดข้อผิดพลาด HTTP 4xx หรือ 5xx ทั้งหมดเพิ่มขึ้นในระดับองค์กร สภาพแวดล้อม และภูมิภาค
- เวลาในการตอบสนองทั้งหมดที่เพิ่มขึ้นสำหรับเปอร์เซ็นต์ที่ 90 (p90) ที่ระดับองค์กร สภาพแวดล้อม และภูมิภาค
เปิดใช้การตรวจจับความผิดปกติ
ระบบจะปิดใช้การตรวจหาความผิดปกติสำหรับองค์กรและสภาพแวดล้อม Edge โดยค่าเริ่มต้น หากต้องการเปิดใช้การตรวจหาความผิดปกติ ให้ส่งคำขอไปยังทีมสนับสนุนของ Apigee Edge เพื่อเปิดใช้สำหรับองค์กรและสภาพแวดล้อมที่เฉพาะเจาะจง Apigee จะประเมินสภาพแวดล้อมและแจ้งให้ทราบหากเปิดใช้การตรวจหาความผิดปกติได้
โปรดอย่าเปิดใช้การตรวจหาความผิดปกติในองค์กรและสภาพแวดล้อมทั้งหมดเพื่อเหตุผลด้านประสิทธิภาพ Apigee ขอแนะนําให้คุณเปิดใช้การตรวจหาความผิดปกติเฉพาะในองค์กรและสภาพแวดล้อมที่มีปริมาณการเข้าชมโดยเฉลี่ยอย่างน้อย 10 ธุรกรรมต่อวินาที (tps)
ตรวจสอบว่าได้เปิดใช้การตรวจจับความผิดปกติหรือไม่
วิธีตรวจสอบว่าเปิดใช้การตรวจจับความผิดปกติหรือไม่
- เลือกวิเคราะห์ > กฎการแจ้งเตือนใน UI ของ Edge
เลือกปุ่ม + การแจ้งเตือน แผงสร้างการแจ้งเตือนจะเปิดขึ้น
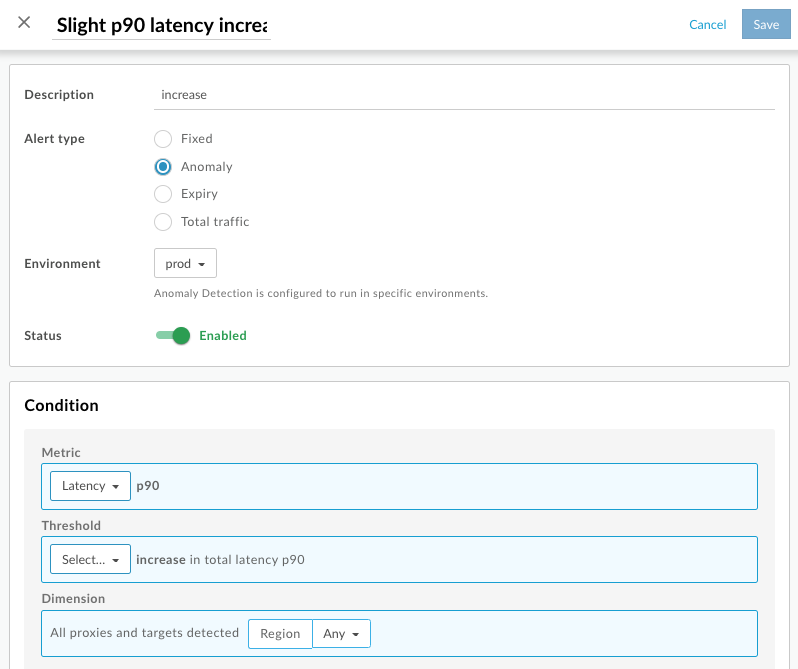
เลือกสภาพแวดล้อมที่ต้องการ
หากตัวเลือกความผิดปกติเป็นสีเทาสําหรับประเภทการแจ้งเตือน แสดงว่าการตรวจจับความผิดปกติปิดอยู่