
מוצג המסמך של Apigee Edge.
עוברים אל
מסמכי תיעוד של Apigee X. מידע
Edge API Analytics אוסף ומנתח מגוון רחב של מידע סטטיסטי מכל בקשת API ותגובה. המידע הזה נאסף באופן אוטומטי ולאחר מכן ניתן להציג אותו ממשק המשתמש של Edge או באמצעות ה-API של המדדים. לעיון במדדים והמאפיינים כדי לקבל מידע נוסף על הנתונים הסטטיסטיים האלה.
כדאי גם לאסוף ניתוח נתונים בהתאמה אישית שספציפיים לשרתי ה-proxy ל-API, לאפליקציות, למוצרים או מפתחים. לדוגמה, אפשר לאסוף נתונים מפרמטרים של שאילתות, מכותרות של בקשות, גופי בקשות ותגובה, או משתנים שאתם מגדירים בממשקי ה-API.
הנושא הזה מדגים איך להשתמש במדיניות של אוסף הנתונים הסטטיסטיים כדי לחלץ ניתוח נתונים מותאמים אישית מבקשה/תשובה של API ולהעביר את הנתונים האלה אל Edge API Analytics. לאחר מכן הם מסבירים איך להציג את ניתוח הנתונים בדוח בממשק המשתמש של Edge או באמצעות ה-Edge API.
מידע על Google Book API
בנושא הזה נסביר איך לתעד נתוני ניתוח מותאמים אישית מבקשות לשרת proxy ל-API Google Books API. Google Books API מאפשר לחפש ספרים לפי כותרת, נושא, מחבר ומאפיינים אחרים.
לדוגמה, אפשר לשלוח בקשות לנקודת הקצה (endpoint) /volumes כדי לבצע חיפוש לפי שם הספר.
מעבירים ל-Book API פרמטר של שאילתה אחת שמכיל את שם הספר:
curl https://www.googleapis.com/books/v1/volumes?q=davinci%20code
הקריאה מחזירה מערך JSON של פריטים שנמצאו שתואמים לקריטריוני החיפוש. למטה מוצגת רכיב המערך הראשון בתגובה (שימו לב שחלק מהתוכן הושמט מטעמי פשטות):
{ "kind": "books#volumes", "totalItems": 1799, "items": [ { "kind": "books#volume", "id": "ohZ1wcYifLsC", "etag": "4rzIsMdBMYM", "selfLink": "https://www.googleapis.com/books/v1/volumes/ohZ1wcYifLsC", "volumeInfo": { "title": "The Da Vinci Code", "subtitle": "Featuring Robert Langdon", "authors": [ "Dan Brown" ], "publisher": "Anchor", "publishedDate": "2003-03-18", "description": "MORE THAN 80 MILLION COPIES SOLD ....", "industryIdentifiers": [ { "type": "ISBN_10", "identifier": "0385504217" }, { "type": "ISBN_13", "identifier": "9780385504218" } ], "readingModes": { "text": true, "image": true }, "pageCount": 400, "printType": "BOOK", "categories": [ "Fiction" ], "averageRating": 4.0, "ratingsCount": 710, "maturityRating": "NOT_MATURE", "allowAnonLogging": true, "contentVersion": "0.18.13.0.preview.3", "panelizationSummary": { "containsEpubBubbles": false, "containsImageBubbles": false }, ... "accessInfo": { "country": "US", "viewability": "PARTIAL", "embeddable": true, "publicDomain": false, "textToSpeechPermission": "ALLOWED_FOR_ACCESSIBILITY", "epub": { "isAvailable": true, "acsTokenLink": "link" }, "pdf": { "isAvailable": true, "acsTokenLink": "link" }, ... } }
שימו לב שהודגשו מספר נקודות בתשובה:
- מספר תוצאות החיפוש
- דירוג ספר ממוצע
- מספר הדירוגים
- זמינות גרסאות PDF של הספר
בקטעים הבאים נתאר איך לאסוף נתונים סטטיסטיים לגבי התחומים האלה של התגובות, וגם
עבור פרמטר השאילתה q, המכיל את הקריטריונים לחיפוש.
יצירת שרת proxy ל-API עבור Google Book API
לפני שתוכלו לאסוף נתונים סטטיסטיים עבור Google Book API, עליכם ליצור שרת proxy של Edge API קוראת לזה. לאחר מכן, מפעילים את ה-Proxy ל-API כדי לשלוח את הבקשות ל-Google Book API.
שלב 2: יצירת שרת proxy ל-API במדריך ליצירת שרת proxy ל-API שמתאר איך ליצור שרת proxy שקורא ממשק API של https://mocktarget.apigee.net. שימו לב ששרת ה-Proxy שמתואר במדריך הזה לא דורש מפתח API כדי לקרוא לו.
מבצעים את אותו התהליך כדי ליצור proxy ל-API עבור נקודת הקצה /volumes של
Google Book API. בשלב 5 של התהליך, כשיוצרים את ה-Proxy ל-API, מגדירים את המאפיינים הבאים
כדי להפנות אל Google Books API:
- שם שרת ה-proxy: "mybooksearch"
- נתיב הבסיס של שרת ה-proxy: "/mybooksearch"
- ממשק API קיים: "https://www.googleapis.com/books/v1/volumes"
אחרי שיוצרים את שרת ה-Proxy ופורסים אותו, אפשר לקרוא לו באמצעות curl
הפקודה:
curl http://org_name-env_name.apigee.net/mybooksearch?q=davinci%20code
כאשר org_name ו-env_name מציינים את הארגון והסביבה שבהם שפרסתם את שרת ה-Proxy. לדוגמה:
curl http://myorg-test.apigee.net/mybooksearch?q=davinci%20code
איסוף של ניתוח נתונים בהתאמה אישית
האיסוף של נתוני ניתוח נתונים מבקשת API הוא תהליך דו-שלבי:
מחלצים את הנתונים שמעניינים אתכם וכותבים אותם במשתנה.
כל הנתונים שמועברים אל Edge API Analytics מגיעים מהערכים שמאוחסנים במשתנים. חלק מהנתונים מאוחסנים אוטומטית במשתנים מוגדרים מראש flow של Edge, כמו של הפרמטרים של שאילתה שמועברים לשרת ה-proxy של ה-API. מידע נוסף זמין בקטע סקירה כללית של משתני הזרימה לקבלת מידע נוסף על משתני הזרימה המוגדרים מראש.
משתמשים בחילוץ משתנים. מדיניות לחילוץ תוכן מותאם אישית מבקשה או מתגובה ולכתיבת הנתונים האלו במשתנה.
לכתוב נתונים ממשתנה ל-Edge API Analytics.
צריך להשתמש במדיניות בנושא אוסף הנתונים הסטטיסטיים כדי לכתוב נתונים ממשתנה ב-Edge API Analytics. הנתונים יכולים להגיע משתני זרימה של Edge, או משתנים שנוצרו במסגרת המדיניות בנושא חילוץ משתנים.
אחרי שתאספו את הנתונים הסטטיסטיים, תוכלו להשתמש בממשק המשתמש או ב-API של Edge management כדי לאחזר. ולסנן נתונים סטטיסטיים. לדוגמה, אפשר ליצור דוח בהתאמה אישית שמציג את הדירוג הממוצע כל כותר ספר, שבו שם הספר תואם לערך של פרמטר השאילתה שהועבר ל-API.
שימוש במדיניות חילוץ משתנים כדי לחלץ נתונים מניתוח הנתונים
יש לחלץ את נתוני Analytics ולאחסן אותם במשתנה, או משתנה זרימה המוגדר מראש על ידי משתנים מותאמים אישית או Edge שאתם מגדירים, לפני שניתן להעביר אותם ל-API Analytics. כדי לכתוב נתונים במשתנה משתמשים במדיניות בנושא חילוץ משתנים.
המדיניות בנושא חילוץ משתנים יכולה לנתח מטענים ייעודיים של הודעות באמצעות ביטויים מסוג JSONPath או XPath.
כדי לחלץ את המידע מתוצאות החיפוש בפורמט JSON של Google Book API, משתמשים בביטוי JSONPath.
לדוגמה, כדי לחלץ את הערך של averageRating מהפריט הראשון ב-JSON
מערך תוצאות, ביטוי JSONPath הוא:
$.items[0].volumeInfo.averageRating
אחרי הערכת JSONPath, מדיניות חילוץ משתנים כותבת את הערך שחולץ במשתנה.
בדוגמה הזו משתמשים במדיניות חילוץ משתנים כדי ליצור ארבעה משתנים:
responsejson.totalitemsresponsejson.ratingscountresponsejson.avgratingresponsejson.pdf
במשתנים האלה, responsejson הוא המשתנה prefix וגם totalitems,
ratingscount, avgrating ו-pdf הם שמות המשתנים.
במדיניות הבאה של חילוץ משתנים מוסבר איך לחלץ נתונים מתגובת JSON ולכתוב אותה
ועד למשתנים מותאמים אישית. כל רכיב <Variable> משתמש במאפיין name ש
מציין את השם של המשתנים המותאמים אישית ואת ביטוי JSONPath המשויך.
הרכיב <VariablePrefix> מציין שתחילית המשתנה.
צריך להוסיף את המדיניות הזו לשרת ה-proxy ל-API בממשק המשתמש של Edge. אם אתם מפתחים את ה-Proxy ל-API ב-XML,
מוסיפים את המדיניות לקובץ בשם /apiproxy/policies בשם ExtractVars.xml:
<ExtractVariables name="ExtractVars"> <Source>response</Source> <JSONPayload> <Variable name="totalitems"> <JSONPath>$.totalItems</JSONPath> </Variable> <Variable name="ratingscount"> <JSONPath>$.items[0].volumeInfo.ratingsCount</JSONPath> </Variable> <Variable name="avgrating"> <JSONPath>$.items[0].volumeInfo.averageRating</JSONPath> </Variable> <Variable name="pdf"> <JSONPath>$.items[0].accessInfo.pdf.isAvailable</JSONPath> </Variable> </JSONPayload> <VariablePrefix>responsejson</VariablePrefix> <IgnoreUnresolvedVariables>true</IgnoreUnresolvedVariables> </ExtractVariables>
שימוש במדיניות של אוסף הנתונים הסטטיסטיים כדי לכתוב נתונים בשירות Analytics
צריך להשתמש במדיניות בנושא אוסף הנתונים הסטטיסטיים כדי לכתוב נתונים ממשתנה ב-Edge API Analytics. המדיניות בנושא אוסף הנתונים הסטטיסטיים מוצגת כך:
<StatisticsCollector> <DisplayName>Statistics Collector-1</DisplayName> <Statistics> <Statistic name="statName" ref="varName" type="dataType">defVal</Statistic> … </Statistics> </StatisticsCollector>
איפה:
- statName מציין את השם שבו משתמשים כדי להתייחס לנתונים הסטטיסטיים בדוח מותאם אישית.
- varName מציין את שם המשתנה שמכיל את הנתונים מ-Analytics לאיסוף. אפשר להגדיר את המשתנה הזה ב-Edge או להיות משתנה מותאם אישית שנוצר באמצעות המדיניות חילוץ משתנים.
dataType מציין את סוג הנתונים של הנתונים המוקלטים כמחרוזת, מספר שלם, מספר ממשי (float), ארוך, כפול או בוליאני.
לגבי נתונים מסוג מחרוזת, אתם מפנים לנתונים הסטטיסטיים בתור מאפיין בדוח מותאם אישית. בסוגי נתונים מספריים (מספר שלם/צף/אורך/כפול), צריך להפנות אל נתונים סטטיסטיים בתור מאפיין או מדד בדוח מותאם אישית.
- defValue (אופציונלי) יכול לספק ערך ברירת מחדל למשתנה מותאם אישית, שיישלח אל API Analytics אם לא ניתן לפענח את המשתנים או שהמשתנה לא מוגדר.
בדוגמה הבאה אתם משתמשים במדיניות של אוסף הנתונים הסטטיסטיים כדי לאסוף נתונים עבור המשתנים נוצרה במדיניות בנושא חילוץ משתנים. אוספים גם את הערך של פרמטר השאילתה שהועבר בכל קריאה ל-API. להפנות לפרמטרים של שאילתות באמצעות flow variable:
request.queryparam.queryParamName
לפרמטר השאילתה בשם 'q' כ:
request.queryparam.q
צריך להוסיף את המדיניות הזו לשרת ה-proxy ל-API בממשק המשתמש של Edge. לחלופין, אם מפתחים את ה-proxy ל-API ב-XML,
הוסף קובץ תחת /apiproxy/policies בשם AnalyzeBookResults.xml, עם התוכן הבא:
<StatisticsCollector name="AnalyzeBookResults"> <Statistics> <Statistic name="totalitems" ref="responsejson.totalitems" type="integer">0</Statistic> <Statistic name="ratingscount" ref="responsejson.ratingscount" type="integer">0</Statistic> <Statistic name="avgrating" ref="responsejson.avgrating" type="float">0.0</Statistic> <Statistic name="pdf" ref="responsejson.pdf" type="boolean">true</Statistic> <Statistic name="booktitle" ref="request.queryparam.q" type="string">none</Statistic> </Statistics> </StatisticsCollector>
צירוף כללי מדיניות לתהליך התגובה של ProxyEndpoint
כדי שדברים יפעלו כראוי, צריך לצרף את המדיניות לתהליך ה-proxy של ה-API במיקום המתאים. בתרחיש לדוגמה הזה, המדיניות חייבת לפעול אחרי שהתשובה מתקבלת מ-Google Book API ולפני שהתגובה תישלח ללקוח ששלח את הבקשה. לכן, יש לצרף את המדיניות PreFlow של תגובת ProxyEndpoint.
ההגדרה לדוגמה של ProxyEndpoint שמופיעה בהמשך מפעילה קודם את המדיניות שנקראת ExtractVars
כדי לנתח את הודעת התגובה. לאחר מכן, המדיניות שנקראת AnalyzeBookResults מעבירה אותם
ל-API Analytics:
<ProxyEndpoint name="default">
><PreFlow name="PreFlow">
<Request/>
<Response>
<Step>
<Name>Extract-Vars</Name>
</Step>
<Step>
<Name>AnalyzeBookResults</Name>
</Step>
</Response>
</PreFlow>
<HTTPProxyConnection>
<!-- Base path used to route inbound requests to this API proxy -->
<BasePath>/mybooksearch</BasePath>
<!-- The named virtual host that defines the base URL for requests to this proxy -->
<VirtualHost>default</VirtualHost>
</HTTPProxyConnection>
<RouteRule name="default">
<!-- Connects the proxy to the target defined under /targets -->
<TargetEndpoint>default</TargetEndpoint>
</RouteRule>
</ProxyEndpoint>פריסה של שרת ה-proxy ל-API
לאחר ביצוע השינויים האלה, צריך לפרוס את שרת ה-proxy ל-API שהגדרתם.
אכלוס נתוני ניתוח
לאחר פריסת שרת ה-proxy ל-API, צריך להפעיל את שרת ה-proxy כדי לאכלס נתונים ב-API Analytics. אפשר לבצע באמצעות הרצת הפקודות הבאות, שכל אחת מהן משתמשת בשם ספר שונה:
מובי דיק:
curl https://org_name-env_name.apigee.net/mybooksearch?q=mobey%20dick
קוד דה וינצ'י:
curl https://org_name-env_name.apigee.net/mybooksearch?q=davinci%20code
נעלמת:
curl https://org_name-env_name.apigee.net/mybooksearch?q=gone%20girl
משחקי הכס:
curl https://org_name-env_name.apigee.net/mybooksearch?q=game%20of%20thrones
הצגת ניתוח הנתונים
ב-Edge יש שתי דרכים להציג את ניתוח הנתונים בהתאמה אישית:
- ממשק המשתמש של Edge תומך בדוחות בהתאמה אישית שמאפשרים להציג את הנתונים בתרשים גרפי.
- API למדדים מאפשר לאחזר נתוני ניתוח נתונים על ידי ביצוע קריאות REST API של Edge. תוכלו להשתמש ב-API כדי ליצור המחשות חזותיות משלכם בצורת ווידג'טים מותאמים אישית שאפשר להטמיע בפורטלים או באפליקציות מותאמות אישית.
יצירת דוח של נתונים סטטיסטיים באמצעות ממשק המשתמש של Edge
דוחות בהתאמה אישית מאפשרות לכם להציג פירוט של נתונים סטטיסטיים ספציפיים לגבי ה-API, כדי להציג את הנתונים המדויקים שאתם רוצים לראות. אפשר ליצור דוח בהתאמה אישית באמצעות כל אחד מהמדדים והמאפיינים המובנים ב-Edge. בנוסף, אפשר להשתמש בכל נתוני Analytics שחילצתם באמצעות הפונקציה המדיניות בנושא אוסף הנתונים הסטטיסטיים.
כשיוצרים מדיניות של אוסף הנתונים הסטטיסטיים, מציינים את סוג הנתונים שנאספים. לגבי סוג הנתונים של המחרוזת, אפשר להפנות לנתונים הסטטיסטיים בתור מאפיין בדוח בהתאמה אישית. לסוגי נתונים מספריים (מספר שלם/צף/אורך/שני), מפנים את התאריך הסטטיסטי בדוח בהתאמה אישית כמאפיין או כמדד. מידע נוסף זמין במאמר ניהול דוחות בהתאמה אישית.
יצירת דוח בהתאמה אישית באמצעות ממשק המשתמש של Edge:
- נכנסים לדף 'דוחות בהתאמה אישית', כמו שמתואר בהמשך.
Edge
כדי לגשת לדף 'דוחות בהתאמה אישית' באמצעות ממשק המשתמש של Edge:
- נכנסים לחשבון בכתובת apigee.com/edge.
- בוחרים באפשרות ניתוח > דוחות בהתאמה אישית > דוחות בסרגל הניווט הימני.
Classic Edge (ענן פרטי)
כדי לגשת לדף 'דוחות בהתאמה אישית' באמצעות ממשק המשתמש של Classic Edge:
- יש להיכנס אל
http://ms-ip:9000, כאשר ms-ip הוא כתובת ה-IP או שם ה-DNS של הצומת של שרת הניהול. בוחרים באפשרות Analtyics > דוחות בסרגל הניווט העליון.
- בדף 'דוחות בהתאמה אישית', לוחצים על +דוח בהתאמה אישית.
- מציינים שם הדוח, למשל mybookreport.
בוחרים מדד מובנה, כמו תנועה, ופונקציית צבירה, כמו Sum.
לחלופין, בוחרים באחד מהנתונים הסטטיסטיים של הנתונים המספריים שיצרתם באמצעות המדיניות StatisticsCollector. לדוגמה, בוחרים ratingscount ופונקציית צבירה של Sum.
בוחרים מאפיין מובנה, כמו API Proxy ל-API או אחד מהם המחרוזת או הנתונים הסטטיסטיים המספריים שיצרתם באמצעות המדיניות StatisticsCollector.
לדוגמה, בוחרים באפשרות שם הספר. עכשיו יוצג בדוח הסכום של ratingscount לפי booktitle:
- לוחצים על שמירה. הדוח מופיע ברשימה של כל הדוחות בהתאמה אישית.
כדי להפיק את הדוח, בוחרים את שם הדוח. כברירת מחדל, בדוח מוצגים נתונים מהשעה האחרונה.
- כדי להגדיר את טווח התאריכים, לוחצים על תצוגת התאריכים בפינה השמאלית העליונה כדי לפתוח את החלון הקופץ של בורר התאריכים.
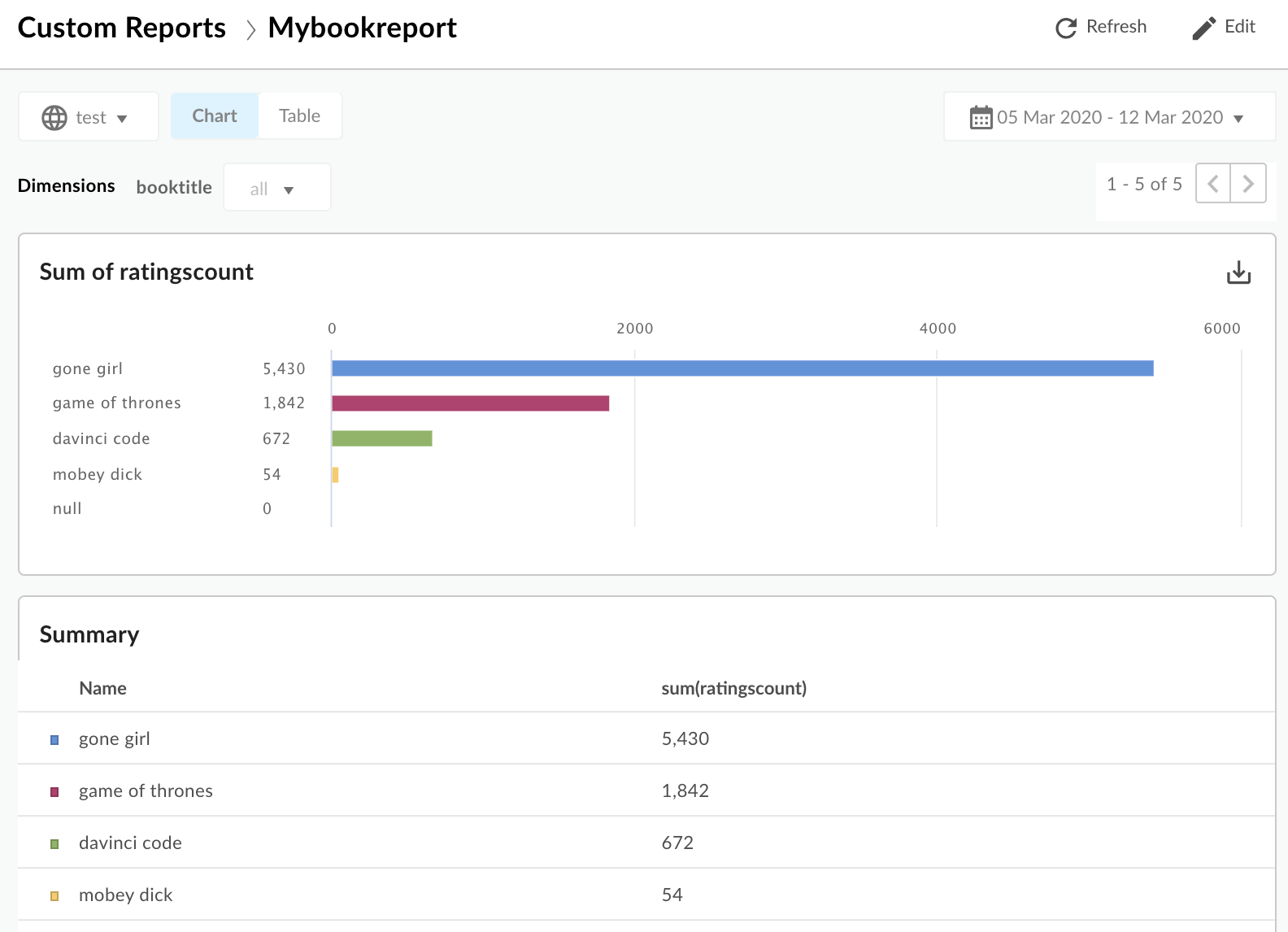
בוחרים באפשרות 7 הימים האחרונים. הדוח מתעדכן ומציג את סכום הדירוגים לכל שם ספר:
קבלת נתונים סטטיסטיים באמצעות Edge API
משתמשים ב-Edge metrics API לנתונים סטטיסטיים על הניתוחים המותאמים אישית שלכם. בבקשה לדוגמה הבאה:
- המשאב לכתובת ה-URL אחרי
/statsמציין את המאפיין הרצוי. בדוגמה הזו תקבלו נתונים עבור המאפייןbooktitle. - פרמטר השאילתה
selectלציון המדדים כדי לאחזר. הבקשה הזו מחזירה ניתוח נתונים על סמך הסכום שלratingscount. הפרמטר
timeRangeמציין את מרווח הזמן לנתונים המוחזרים. טווח הזמן מופיע בפורמט:MM/DD/YYYY%20HH:MM~MM/DD/YYYY%20HH:MM
הקריאה המלאה ל-API היא:
curl -X GET "https://api.enterprise.apigee.com/v1/organizations/org_name/environments/env_name/stats/booktitle?select=sum(ratingscount)&timeRange=04/21/2019&2014:00:00~04/22/2019&2014:00:00" / -u email:password
התשובה אמורה להופיע בטופס:
{
"environments": [
{
"dimensions": [
{
"metrics": [
{
"name": "sum(ratingscount)",
"values": [
"5352.0"
]
}
],
"name": "gone girl"
},
{
"metrics": [
{
"name": "sum(ratingscount)",
"values": [
"4260.0"
]
}
],
"name": "davinci code"
},
{
"metrics": [
{
"name": "sum(ratingscount)",
"values": [
"1836.0"
]
}
],
"name": "game of thrones"
},
{
"metrics": [
{
"name": "sum(ratingscount)",
"values": [
"1812.0"
]
}
],
"name": "mobey dick"
}
],
"name": "prod"
}
],
"metaData": {
"errors": [],
"notices": [
"query served by:9b372dd0-ed30-4502-8753-73a6b09cc028",
"Table used: uap-prod-gcp-us-west1.edge.edge_api_raxgroup021_fact",
"Source:Big Query"
]
}
}Edge metrics API יש אפשרויות רבות. לדוגמה, אפשר למיין את התוצאות בסדר עולה או יורד. בדוגמה הבאה משתמשים בסדר עולה:
curl -X GET "https://api.enterprise.apigee.com/v1/organizations/org_name/environments/env_name/stats/booktitle?select=sum(ratingscount)&timeRange=04/21/2019&2014:00:00~04/22/2019&2014:00:00&sort=ASC" / -u email:password
אפשר גם לסנן את התוצאות על ידי ציון הערכים של המאפיינים הרצויים. בדוגמה הבאה, הדוח מסונן לפי תוצאות של 'Gone Girl'. ו"קוד דה וינצ'י":
$ curl -X GET "https://api.enterprise.apigee.com/v1/organizations/org_name/environments/env_name/stats/booktitle?select=sum(ratingscount)&timeRange=04/21/2019&2014:00:00~04/22/2019&2014:00:00&filter=(booktitle%20in%20'gone%20girl'%2C%20'davinci%20code')" / -u email:password
יצירת משתנים מותאמים אישית של ניתוח נתונים באמצעות הכלי ליצירת פתרונות
בונה הפתרונות מאפשר לכם ליצור משתנים מותאמים אישית של ניתוח נתונים באמצעות כלי קל לשימוש תיבת דו-שיח של ממשק המשתמש לניהול.
מומלץ לקרוא את הקטע הקודם בנושא איסוף נתונים בהתאמה אישית של ניתוח נתונים. שמסביר איך פועלים משתני החילוץ וכללי המדיניות של אוסף הנתונים הסטטיסטיים להזין משתנים מותאמים אישית באופן ידני ל-Edge API Analytics. כמו שאפשר לראות, ממשק המשתמש דומה בדפוס הזה, אבל מספק דרך נוחה להגדיר דברים דרך ממשק המשתמש. אפשר לנסות את הדוגמה של Google Books API באמצעות ממשק המשתמש במקום לערוך ולצרף כללי מדיניות באופן ידני.
תיבת הדו-שיח של הכלי ליצירת פתרונות מאפשרת לכם להגדיר משתני ניתוח נתונים ישירות בממשק המשתמש. הזה יוצר כללי מדיניות ומצרף אותם עבורכם לשרת ה-proxy של ה-API. חֶלֶץ כללי המדיניות של משתנים שמעניינים את הבקשות או התשובות, ומעבירים את המשתנים שחולצו אל Edge ניתוח נתונים ב-API.
יוצר הפתרונות יוצר משתני חילוץ חדשים כללי המדיניות של אוסף הנתונים הסטטיסטיים ונותנים להם שמות ייחודיים. הכלי ליצירת פתרונות לא מאפשר לכם לחזור ולשנות את המדיניות הזו לאחר שהם נוצרים בגרסה נתונה של שרת proxy. שפת תרגום לבצע שינויים, לערוך את כללי המדיניות שנוצרו ישירות בכלי לעריכת המדיניות.
- בממשק המשתמש של Edge, עוברים לדף הסקירה הכללית של שרת ה-proxy.
- לוחצים על פיתוח.
- בדף 'פיתוח', בוחרים באפשרות אוסף ניתוח נתונים מותאם אישית מהכלים תפריט תיבת הדו-שיח של הכלי ליצירת פתרונות תופיע.
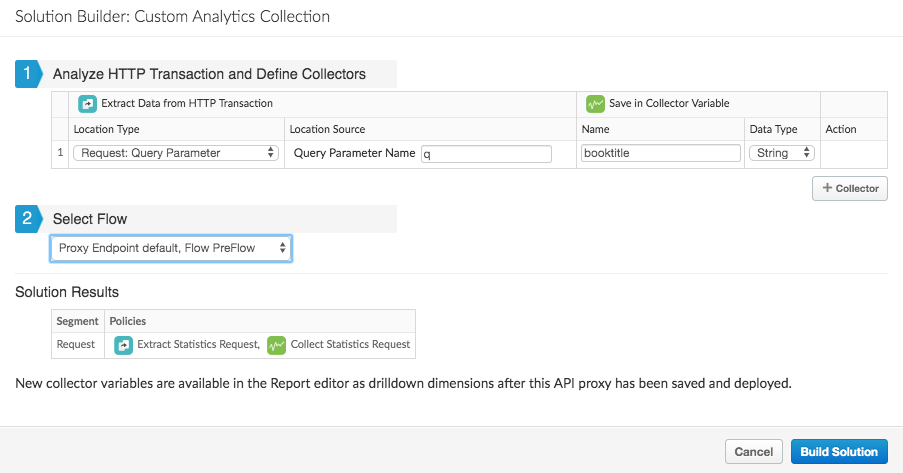
- בתיבת הדו-שיח של יוצר הפתרונות, תחילה מגדירים שני כללי מדיניות: חילוץ משתנים ו אוסף הנתונים הסטטיסטיים. לאחר מכן צריך להגדיר לאן לצרף את כללי המדיניות.
- מציינים את הנתונים שרוצים לחלץ:
- סוג מיקום: בוחרים את סוג הנתונים שרוצים לאסוף ואיפה כדי לאסוף אותו משם. אפשר לבחור נתונים מהצד של הבקשה או התשובה. לדוגמה, בקשה: פרמטר או תשובה של שאילתה: גוף XML.
- מקור מיקום: מזהים את הנתונים שרוצים לאסוף. לדוגמה, שם הפרמטר של השאילתה או ה-XPath של נתוני ה-XML בגוף התגובה.
- מציינים משתנה name (וסוג) שהמדיניות של אוסף הנתונים הסטטיסטיים
ישמשו לזיהוי הנתונים שחולצו. ניתן לעיין בהגבלות על שמות בנושא זה.
השם שבו תשתמשו יופיע בתפריט הנפתח בקטע מאפיינים או מדדים בממשק המשתמש של הכלי ליצירת דוחות בהתאמה אישית. - עליך לבחור את המיקום בתהליך ה-proxy של ה-API שבו ברצונך לצרף את חילוץ המדיניות שנוצרה משתנים ואוסף נתונים סטטיסטיים. לקבלת הנחיות, ראה "צירוף מדיניות לתהליך התגובה של ProxyEndpoint". כדי שדברים יפעלו כראוי, יהיו מצורפים לנתיב של שרת Proxy ל-API במיקום המתאים. עליך לצרף את הקובץ מדיניות בשלב בתהליך שבו המשתנים שאתם לוכדים נמצאים בהיקף. (מאוכלס).
- לוחצים על +Collector כדי להוסיף עוד משתנים מותאמים אישית.
כשמסיימים, לוחצים על יצירת פתרון.
- שומרים ופורסים את שרת ה-proxy.
עכשיו אפשר ליצור דוח בהתאמה אישית לגבי הנתונים, כמו שמתואר למעלה.