
您正在查看 Apigee Edge 說明文件。
前往 Apigee X 說明文件。 info
API 監控可讓您建立以模式為依據的規則,根據一組預先定義的條件觸發快訊。這類警示稱為「固定」警示,是 API Monitoring 初始版本支援的唯一警示類型。
舉例來說,您可以針對下列情況發出固定快訊:
- [5xx 錯誤率] [大於] [10%],持續 [10 分鐘],來自 [目標 mytarget1]
- [2xx 錯誤計數] [小於] [50],持續 [5 分鐘],發生在 [us-east-1 區域]
- [p90 延遲時間] [大於] [750 毫秒],持續 [10 分鐘],發生於 [proxy myproxy1]
當符合固定快訊的條件時,API Monitoring 會發出快訊,通知您發生問題。不過,您必須先定義特定警示條件,API Monitoring 才能發出警示。
雖然固定快訊很實用,但由於流量模式會隨時間變化,因此很難判斷哪些條件有適當的門檻。舉例來說,如果設定的門檻過低,就會收到大量快訊。如果設定的門檻過高,可能會錯過一些重大問題或服務中斷情形。
異常偵測
透過異常偵測功能,您可以讓 Edge 偵測流量和效能問題,而不需要自行預先判斷。Edge 會自動在機構、環境和區域層級尋找異常狀況。系統偵測到異常現象時,會記錄異常現象,並在 Edge 使用者介面的事件資訊主頁中顯示。
異常偵測功能會將人工智慧 (AI) 和機器學習 (ML) 模型套用至歷來的 API 資料。異常偵測功能可針對您未曾想到的情況,即時發出快訊,協助您提升工作效率,並縮短 API 問題的平均回應時間 (MTTR)。
舉例來說,偵測到的異常情況可能包括新 API 版本導致流量突然暴增,並導致 API 延遲時間隨之增加。或者,後端的版本設定錯誤,導致 API 回報的後端錯誤數量增加。
系統偵測到的異常狀況包含下列資訊:
- 導致異常的評估指標,例如 Proxy 延遲或 HTTP 錯誤代碼。
- 異常狀況的門檻。閾值可以是「輕微」、「中度」或「嚴重」。
舉例來說,Edge 可自動偵測異常狀況,例如:
- [環境為產品環境,區域為 region1] 中的 [503 錯誤數量上升] 有 [輕微上升]
- [環境:prod,區域:region2] 中的 [中等] [4xx 錯誤次數上升]
- [環境:prod、區域:region3] 發生 [嚴重] [延遲時間增加]
您可以根據「事件」資訊主頁顯示的異常資訊,建立新類型的快訊 (稱為「異常」快訊),以便在發生這些情況時收到通知。
異常類型
Edge 會自動偵測下列異常類型:
- 機構、環境和區域層級的 HTTP 503 錯誤數量增加
- 機構、環境和區域層級的 HTTP 504 錯誤數量增加
- 機構、環境和區域層級的所有 HTTP 4xx 或 5xx 錯誤數量增加
- 在機構、環境和區域層級,第 90 百分位數 (p90) 的整體回應延遲時間增加
啟用異常偵測
根據預設,Edge 機構和環境會停用異常偵測功能。如要啟用異常偵測功能,請向 Apigee Edge 支援團隊提出要求,為特定機構和環境啟用這項功能。Apigee 會評估您的環境,並通知您是否可以啟用異常偵測功能。
基於效能考量,請勿在所有機構和環境中啟用異常偵測功能。Apigee 建議您只在平均流量負載至少為每秒 10 筆交易 (tps) 的機構和環境中啟用異常偵測功能。
檢查是否已啟用異常偵測功能
如要確認是否已啟用異常偵測功能,請按照下列步驟操作:
- 在 Edge UI 中,依序選取「Analyze」>「Alert Rules」。
選取「+ 快訊」按鈕。建立快訊面板隨即開啟:
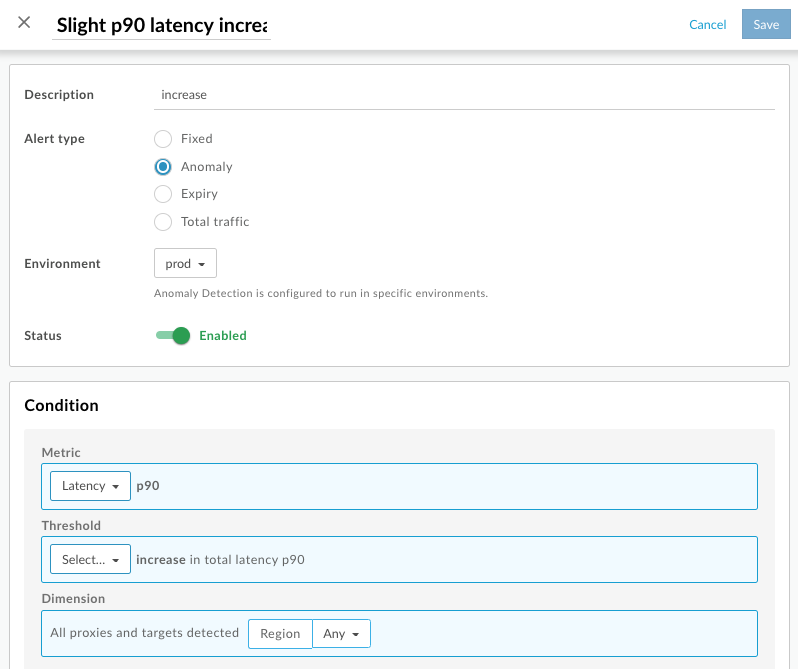
選取所需環境。
如果「警示類型」的「異常狀況」選項顯示為灰色,表示異常狀況偵測功能已停用。