
Você está visualizando a documentação do Apigee Edge.
Acesse a
documentação da
Apigee X. info
O Monitoramento da API permite criar regras baseadas em padrões que acionam alertas com base em um conjunto de condições predefinidas. Esses tipos de alertas são chamados de alertas fixos e eram o único tipo de alerta compatível com a versão inicial da API Monitoring.
Por exemplo, você pode gerar um alerta fixo quando:
- [taxa de erros 5xx] [é maior que] [10%] por [10 minutos] de [segmentar mytarget1]
- [contagem de erros 2xx] [é menor que] [50] por [5 minutos] em [região us-east-1]
- [p90 latência] [é maior que] [750 ms] por [10 minutos] em [proxy myproxy1]
Quando as condições de um alerta fixo são atendidas, o API Monitoring emite um alerta para notificar você sobre o problema. No entanto, você precisa ter definido as condições específicas de alerta para que a API Monitoring possa aumentá-lo.
Ainda que os alertas fixos sejam valiosos, pode ser difícil determinar os limites certos para uma condição, porque os padrões de tráfego mudam ao longo do tempo. Por exemplo, se você definir um limite muito baixo, haverá muitos alertas. Se você definir um limite muito alto, poderá perder alguns problemas críticos ou interrupções.
Detecção de anomalias
Com a detecção de anomalias, você permite que o Edge detecte problemas de tráfego e desempenho em vez de predeterminá-los por conta própria. O Edge procura automaticamente condições de anomalias nos níveis da organização, do ambiente e da região. Quando detectada, a anomalia é registrada para exibição no Painel de eventos na IU do Edge.
A detecção de anomalias funciona com a aplicação de modelos de inteligência artificial (IA) e machine learning (ML) aos dados históricos da API. Assim, a detecção de anomalias pode gerar alertas em tempo real para cenários em que você não imaginou para melhorar a produtividade e reduzir o tempo médio de resolução (MTTR, na sigla em inglês) dos problemas com a API.
Exemplos de anomalias detectadas podem incluir situações em que uma nova versão da API leva a um aumento inesperado no tráfego e a um aumento correspondente na latência da API. Ou uma versão mal configurada no back-end leva a um aumento nos erros de back-end informados pela API.
Uma anomalia detectada inclui as seguintes informações:
- A métrica que causou a anomalia, como a latência de proxy ou um código de erro HTTP.
- O limite da anomalia. O limite pode ser leve, moderado ou grave.
Por exemplo, o Edge pode detectar automaticamente uma anomalia, como:
- Um [slight] [uptick in 503 errors] em [environment prod, region region1]
- Um [moderate] [uptick in 4xx errors] em [environment prod, region region2]
- Um [severe] [latency increase] em [environment prod, region region3]
Com base nas informações de anomalia exibidas no painel Eventos, é possível criar um novo tipo de alerta, chamado alerta de anomalia, para notificá-lo sobre essas condições.
Tipos de anomalia
O Edge detecta automaticamente os seguintes tipos de anomalias:
- Aumento nos erros HTTP 503 para organização, ambiente e região
- Aumento nos erros HTTP 504 no nível da organização, do ambiente e da região
- Aumento de todos os erros HTTP 4xx ou 5xx nos níveis de organização, ambiente e região
- Aumento da latência total da resposta para o 90o percentil (p90) no nível da organização, do ambiente e da região
Ativar detecção de anomalias
Por padrão, a detecção de anomalias é desativada para organizações e ambientes do Edge. Para ativar a detecção de anomalias, faça uma solicitação ao suporte do Apigee Edge para ativá-la em uma organização e um ambiente específicos. A Apigee avaliará seu ambiente e informará se a detecção de anomalias pode ser ativada.
Por motivos de desempenho, não ative a detecção de anomalias em todas as organizações e ambientes. A Apigee recomenda que você ative a detecção de anomalias apenas em uma organização e em um ambiente que tenha uma carga de tráfego média de pelo menos 10 transações por segundo (tps).
Verificar se a detecção de anomalias está ativada
Para verificar se a detecção de anomalias está ativada:
- Clique em Analisar > Regras de alerta na interface do usuário do Edge.
Selecione o botão + Alerta. O painel de criação de alerta é aberto.
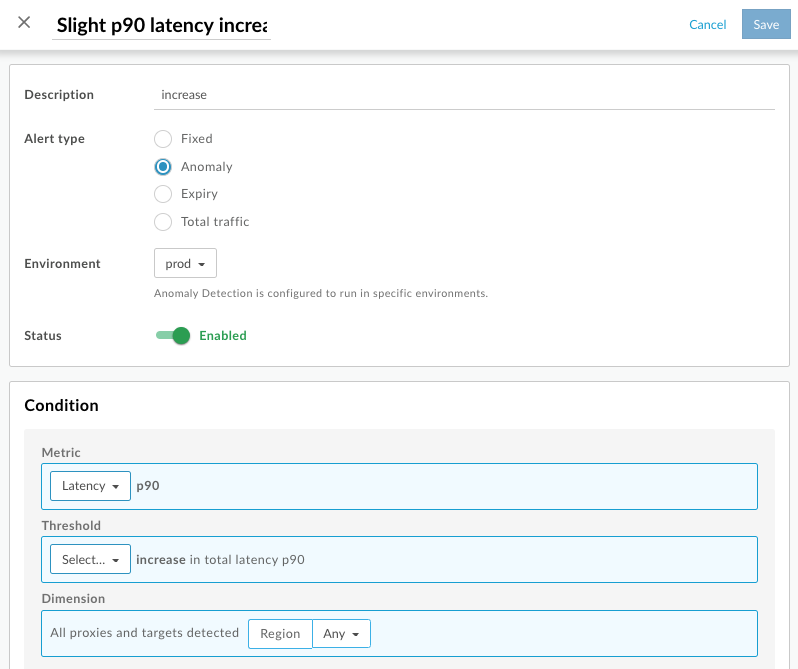
Selecione o ambiente pretendido.
Se a opção Anomalia estiver esmaecida em Tipo de alerta, a detecção de anomalias será desativada.