
您正在查看 Apigee Edge 說明文件。
前往 Apigee X 說明文件。 info
異常偵測包含三個主要階段:
訓練模型
異常偵測功能會根據歷來時序資料,訓練 API Proxy 行為的模型。您無須採取任何行動即可訓練模型。Edge 會自動根據過去六小時的流量資料,建立及訓練模型。因此,Edge 需要至少六小時的 API 代理資料,才能訓練模型,並記錄異常現象。
記錄異常事件
在執行階段,Edge 異常偵測功能會將 API Proxy 的目前行為,與模型預測的行為進行比較。異常偵測功能可根據特定信心門檻,判斷何時會出現超出預測值的作業指標。例如,當 5xx 錯誤率超過模型預測的率時。
Edge 偵測到異常情況時,會自動將該情況記錄到 Edge UI 中的事件資訊主頁。Edge 會針對每個偵測到的異常記錄輕微、中度或嚴重的信心門檻。舉例來說,嚴重異常值是指系統認為異常的值,且可信度極高。
事件資訊主頁會顯示的事件清單,包含 Edge 偵測到的所有異常事件和任何觸發的快訊。警示可以是固定警示或異常警示。
查看異常狀況:
- 在 Edge 使用者介面中,依序按一下「分析」>「事件」。新的「事件」資訊主頁隨即顯示:
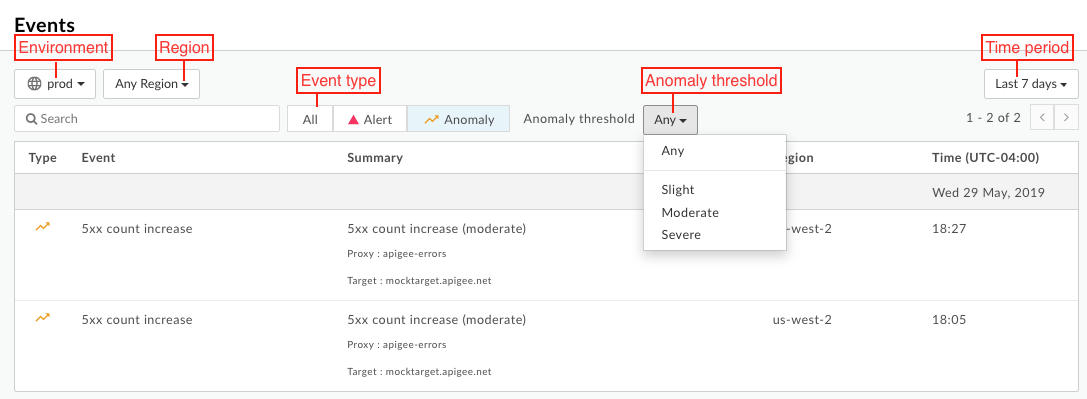
- 依下列條件篩選「事件」資訊主頁:
- 環境
- 區域
- 事件類型為「快訊」 (已修正和異常) 或「異常」
- 異常狀況門檻 (僅限異常狀況)
- 時間範圍
如何深入查看異常值:
在「事件」資訊主頁中選取異常值資料列,即可在 API 監控「調查」資訊主頁中開啟異常值。在以下範例中,您會針對 p90 延遲時間略微增加的異常狀況進行調查。黃色垂直條會指出異常發生的位置:
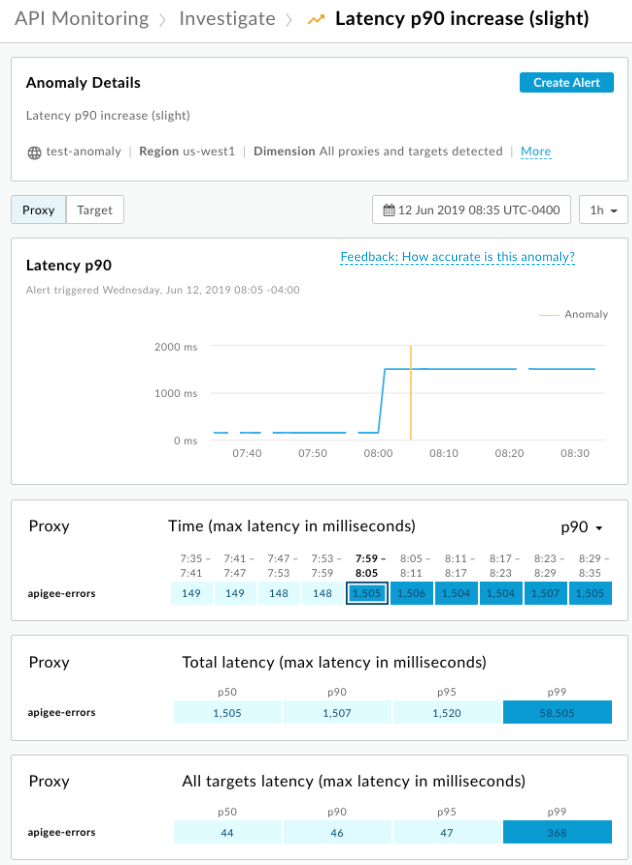
選取顯示中的區塊即可查看異常詳細資料:
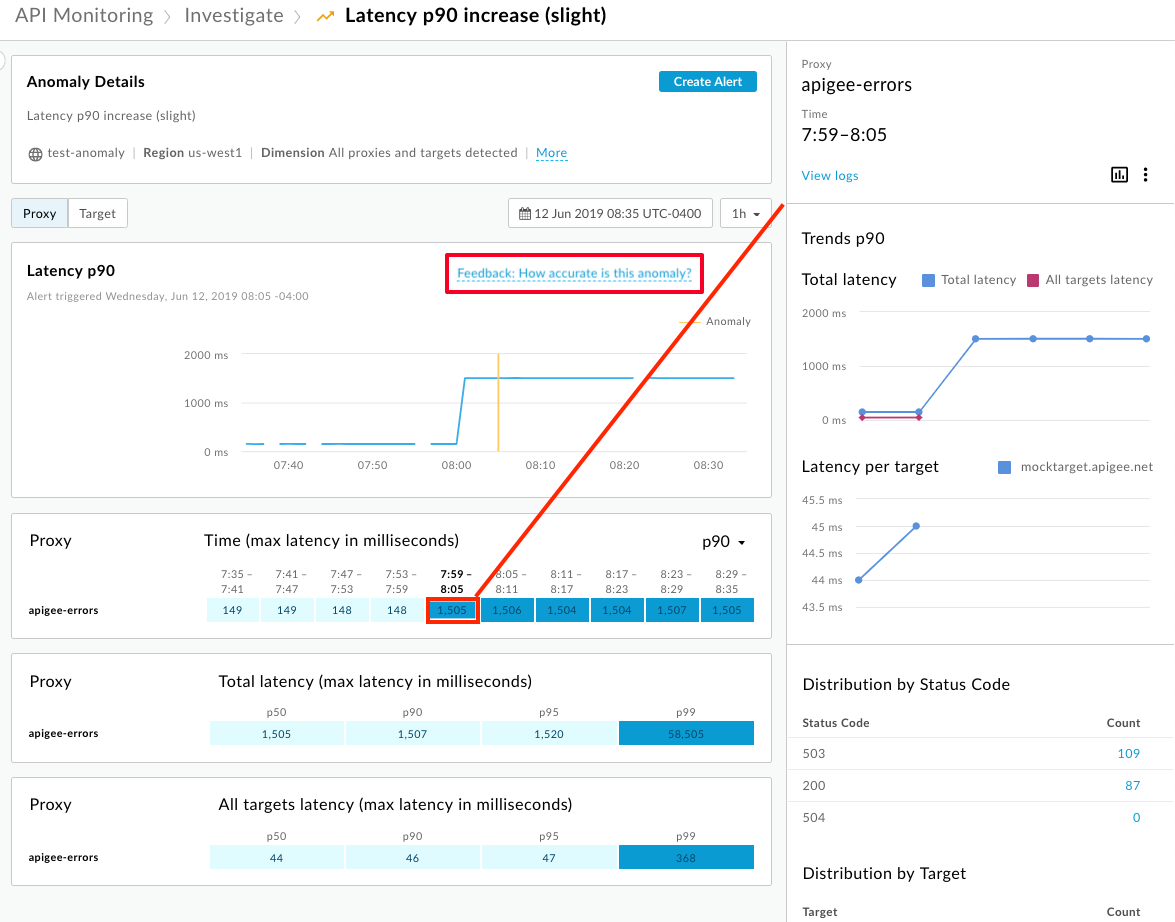
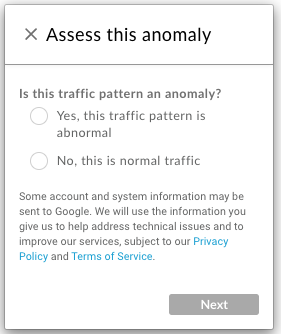
選取「意見回饋:這項異常值的準確度為何?」,向 Apigee 提供意見回饋,協助改善異常值偵測功能。請使用這個連結,指出流量模式是否確實異常、偵測功能對您有多實用,以及選擇性留下註解:
產生快訊
根據預設,Edge 會產生異常事件,但不會發出異常警示。您可以查看「事件」資訊主頁,判斷系統是否在計算出的閾值中偵測到異常現象,並視情況採取行動。如果是這樣,您就可以針對目前或其他門檻層級建立異常狀況快訊。下次發生異常情況時,Edge 會發出快訊,並傳送電子郵件或其他類型的通知給您。
注意:發出快訊後,Edge 不會在 10 分鐘過後再次發出相同的快訊,除非快訊條件仍存在。這個間隔可避免 Edge 針對相同情況發出重複警示。
建立異常狀況快訊:
- 在「事件」資訊主頁中選取異常值,即可查看上方顯示的異常值詳細資料。
- 在異常詳細資料中選取「建立快訊」按鈕。建立快訊面板隨即開啟。
設定快訊。在下列範例中,您會針對任何區域的
prod環境,設定 p90 延遲時間略微增加的快訊: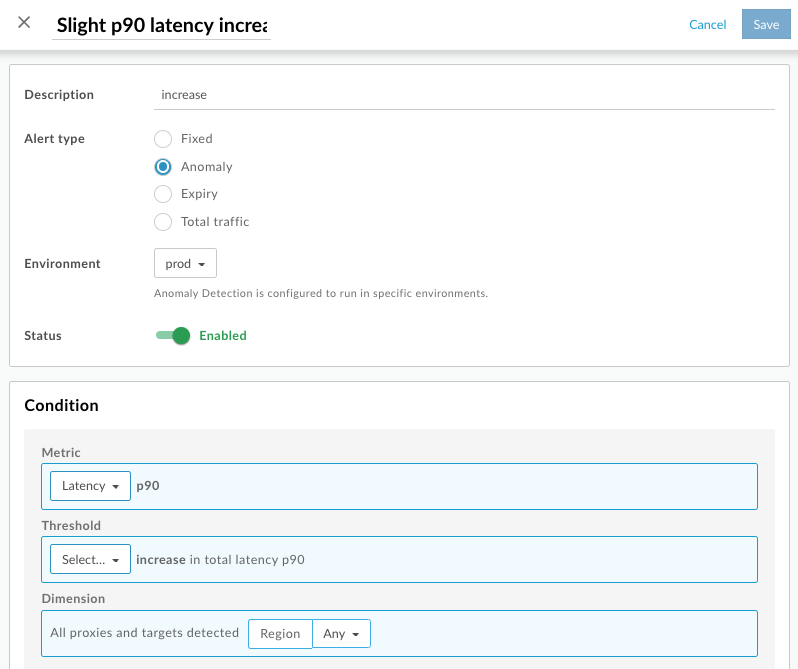
按一下「+ 通知」新增警示通知。
通知詳細資訊 說明 管道 選取要使用的通知管道,並指定目的地:電子郵件、Slack、PagerDuty 或 Webhook。 目的地 根據所選管道類型指定目的地:
- 電子郵件:電子郵件地址,例如 joe@company.com
- Slack - Slack 管道網址,例如 https://hooks.slack.com/services/T00000000/B00000000/XXXXX
- PagerDuty - PagerDuty 代碼,例如 abcd1234efgh56789
Webhook - Webhook 網址,例如 https://apigee.com/test-webhook
注意:每則通知只能指定一個目的地。 如要為相同管道類型指定多個目的地,請新增其他通知。
- 如要新增其他通知,請重複執行步驟 4。
- 如果您新增了通知,請設定下列欄位:
欄位 說明 節流 傳送通知的頻率。從下拉式清單中選取所需的值。 按一下 [儲存]。
系統會在下次發生異常情況時發出警報。