
You're viewing Apigee Edge documentation.
Go to the
Apigee X documentation. info
Edge API Analytics is a very powerful built-in feature provided by Apigee Edge. It collects and analyzes a broad spectrum of data that flows across APIs. The analytics data captured can provide very useful insights. For instance, How is the API traffic volume trending over a period of time? Which is the most used API? Which APIs are having high error rates?
Regular analysis of this data and insights can be used to take appropriate actions such as future capacity planning of APIs based on the current usage, business and future investment decisions, and many more.
Analytics Data and its storage
API Analytics captures many different types of data such as:
- Information about an API - Request URI, Client IP address, Response Status Codes, and so on
- API Proxy Performance - Success/Failure rate, Request and Response Processing Time, and so on
- Target Server Performance - Success/Failure rate, Processing Time
- Error Information - Number of Errors, Fault Code, Failing Policy, Number of Apigee and Target Server caused errors.
- Other Information - Number of requests made by Developers, Developer Apps, and so on
All these data are stored in an analytics schema created and managed within a
Postgres database by Apigee Edge.
Typically, in a vanilla Edge installation, Postgres will have following schemata:
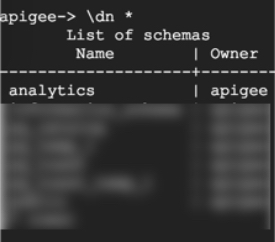
The schema named analytics is used by Edge for storing all the analytics data for
each organization and environment. If monetization is installed there will be a rkms
schema. Other schemata are meant for Postgres internals.
The analytics schema will keep changing as Apigee Edge will dynamically add new fact
tables to it at runtime. The Postgres server component will aggregate the fact data into aggregate
tables which get loaded and displayed on the Edge UI.
Antipattern
Adding custom columns, tables, and/or views to any of the Apigee owned schemata in Postgres Database on Private Cloud environments directly using SQL queries is not advisable, as it can have adverse implications.
Let's take an example to explain this in detail.
Consider a custom table named account has been created under analytics schema as
shown below:
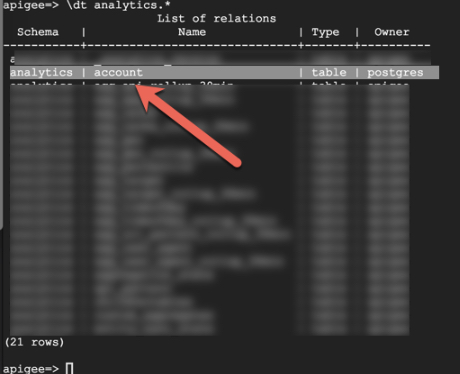
After a while, let's say there's a need to upgrade Apigee Edge from a lower version to a higher version. Upgrading Private Cloud Apigee Edge involves upgrading Postgres amongst many other components. If there are any custom columns, tables, or views added to the Postgres Database, then Postgres upgrade fails with errors referencing the custom objects as they are not created by Apigee Edge. Thus, the Apigee Edge upgrade also fails and cannot be completed.
Similarly errors can occur during Apigee Edge maintenance activities where in backup and restore of Edge components including Postgres database are performed.
Impact
- Apigee Edge upgrade cannot be completed because the Postgres component upgrade fails with errors referencing to custom objects not created by Apigee Edge.
- Inconsistencies (and failures) while performing Apigee Analytics service maintenance (backup/restore).
Best Practice
- Don't add any custom information in the form of columns, tables, views, functions, and
procedures directly to any of the Apigee owned schema such as
analytics, and so on - If there's a need to support custom information, it can be added as columns (fields) using
a Statistics Collector policy to
analyticsschema.