
<ph type="x-smartling-placeholder"></ph>
Sie sehen die Dokumentation zu Apigee Edge.
Gehen Sie zur
Apigee X-Dokumentation. Weitere Informationen
Mit der RaiseFault-Richtlinie können API-Entwickler einen Fehlerablauf initiieren, Fehlervariablen in einer Antworttextnachricht festlegen und die entsprechenden Antwortstatuscodes festlegen. Sie können auch die RaiseFault-Richtlinie verwenden, um Ablauffehler, die sich auf den Fehler beziehen, festzulegen, z. B. fault.name, fault.type und fault.category. Da diese Variablen in Analysedaten und Router-Zugriffslogs angezeigt werden, die für die Fehlerbehebung verwendet werden, ist es wichtig, den Fehler genau zu identifizieren.
Sie können die RaiseFault-Richtlinie verwenden, um bestimmte Bedingungen als Fehler zu behandeln, auch wenn kein tatsächlicher Fehler in einer anderen Richtlinie oder auf dem Back-End-Server des API-Proxys aufgetreten ist. Wenn der Proxy zum Beispiel eine benutzerdefinierte Fehlermeldung an die Client-App senden soll, wenn der Back-End-Antworttext den String unavailable enthält, können Sie die RaiseFault-Richtlinie wie in Code-Snippet unten aufrufen:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
Der Name der RaiseFault-Richtlinie ist in
API Monitoring als fault.name und in den Zugriffs- und Routerzugriffslogs als x_apigee_fault_policy sichtbar.
Dies hilft, die Fehlerursache zu diagnostizieren.
Anti-Pattern
Verwendung der RaiseFault-Richtlinie in FaultRules, nachdem bereits eine andere Richtlinie einen Fehler ausgelöst hat
Betrachten Sie das folgende Beispiel, bei dem eine OAuthV2-Richtlinie im API-Proxy-Ablauf mit dem InvalidAccessToken-Fehler fehlgeschlagen ist. Bei einem Fehler legt Edge den fault.name als InvalidAccessToken fest, tritt in
Fehlerfluss und führen alle definierten FaultRules aus. In der FaultRule gibt es eine RaiseFault-Richtlinie mit dem Namen RaiseFault, die immer dann eine benutzerdefinierte Fehlerantwort sendet, wenn ein InvalidAccessToken-Fehler auftritt. Die Verwendung der RaiseFault-Richtlinie in einer FaultRule bedeutet jedoch, dass die fault.name-Variable überschrieben wird und die tatsächliche Fehlerursache maskiert.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
RaiseFault-Richtlinie in einer FaultRule unter allen Bedingungen verwenden
Im folgenden Beispiel wird eine RaiseFault-Richtlinie mit dem Namen RaiseFault ausgeführt, wenn fault.name nicht RaiseFault ist:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
Wie im ersten Szenario werden die Schlüsselfehlervariablen fault.name, fault.code und fault.policy durch den Namen der RaiseFault-Richtlinie überschrieben. Dadurch ist es nahezu unmöglich, herauszufinden, welche Richtlinie den Fehler verursacht hat, ohne auf eine Trace-Datei zuzugreifen, die den Fehler anzeigt oder das Problem reproduziert.
Verwendung der RaiseFault-Richtlinie zur Rückgabe einer HTTP-2x-Antwort außerhalb des Fehlerflusses.
Im folgenden Beispiel wird eine RaiseFault-Richtlinie namens HandleOptionsRequest ausgeführt, wenn das Verb der Anfrage OPTIONS lautet:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
Der Intent ist, die Antwort sofort an den API-Client zurückzugeben, ohne dass weitere Richtlinien verarbeitet werden. Dies führt jedoch zu irreführenden Analysedaten, da die Fehlervariablen den Namen der RaiseFault-Richtlinie enthalten und den Proxy erschweren. Die richtige Methode zur Implementierung des gewünschten Verhaltens ist die Verwendung von Abläufen mit besonderen Bedingungen, wie unter CORS-Unterstützung hinzufügen beschrieben.
Auswirkungen
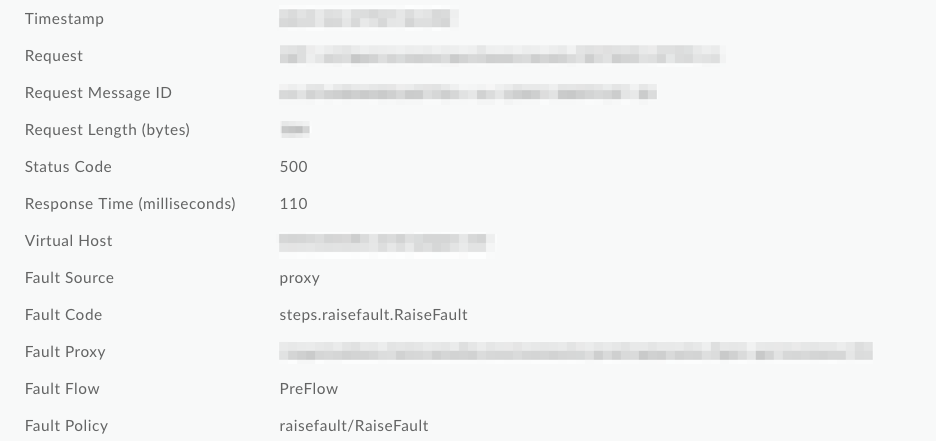
Wenn Sie wie oben beschrieben die Richtlinie "Capturefault" verwenden, werden Schlüsselfehlervariablen mit dem Namen der RaiseFault-Richtlinie anstelle des Namens der fehlerhaften Richtlinie überschrieben. In Analytics- und NGINX Access-Logs werden die Variablen x_apigee_fault_code und x_apigee_fault_policy überschrieben. In API Monitoring werden Fault Code und Fault Policy überschrieben. Dieses Verhalten erschwert die Fehlerbehebung und bestimmt, welche Richtlinie die tatsächliche Ursache des Fehlers ist.
Im folgenden Screenshot aus API-Monitoring sehen Sie, dass der Fehlercode und die Fehlerrichtlinie auf allgemeine RaiseFault-Werte überschrieben wurden. Dadurch ist es unmöglich, die Ursache des Fehlers in den Logs zu bestimmen:
Best Practice
Wenn eine Edge-Richtlinie einen Fehler ausgibt und Sie die Fehlermeldung anpassen möchten, Verwenden Sie die Zuweisungs- oder JavaScript-Richtlinie anstelle der Richtlinie "RaiseFault".
Die RaiseFault-Richtlinie sollte in einem nicht fehlerfreien Ablauf verwendet werden. Das bedeutet, dass Sie eine Ausnahme nur als RaiseFault behandeln, wenn eine bestimmte Bedingung als Fehler behandelt wird, selbst wenn tatsächlich ein Fehler in einer Richtlinie oder im Back-End-Server des API-Proxys aufgetreten ist. Sie können beispielsweise die Richtlinie "RaiseFault" verwenden, um zu signalisieren, dass erforderliche Eingabeparameter fehlen oder eine falsche Syntax haben.
Sie können RaiseFault auch in einer Fehlerregel verwenden, wenn Sie einen Fehler bei der Verarbeitung eines Fehlers erkennen möchten. Der Fehler-Handler selbst kann beispielsweise einen Fehler verursachen, den Sie mit "RaiseFault" signalisieren möchten.