
<ph type="x-smartling-placeholder"></ph>
Vous consultez la documentation Apigee Edge.
Accédez à la page
Documentation sur Apigee X. En savoir plus
Symptôme
Le déploiement des révisions de proxy d'API via l'interface utilisateur Edge ou l'appel d'API de gestion Edge échoue avec
erreur "Error while accessing datastore".
Messages d'erreur
Error in deployment for environment qa. The revision is deployed, but traffic cannot flow. Error while accessing datastore;Please retry later
Causes possibles :
Les causes courantes de ce problème sont les suivantes:
-
Cause Détails Pour Problème de connectivité réseau entre le processeur de messages et Cassandra Échec de la communication entre le processeur de messages et Cassandra en raison du réseau les problèmes de connectivité ou les règles de pare-feu. Utilisateurs de cloud privé Edge Erreurs de déploiement dues à Cassandra redémarrages Le ou les nœuds Cassandra n'étaient pas disponibles, car ils ont été redémarrés dans le cadre de la routine et la maintenance de l'infrastructure. Utilisateurs de cloud privé Edge Pic de latence des requêtes de lecture sur Cassandra Si le ou les nœuds Cassandra effectuent un grand nombre de lectures simultanées, il peut répondre lentement en raison du pic de latence des requêtes de lecture. Utilisateurs de cloud privé Edge Bundle de proxy d'API de plus de 15 Mo Cassandra a été configuré pour ne pas autoriser les groupes de proxys d'API de plus de 15 Mo dans la taille de l'image. Utilisateurs de cloud privé Edge Problème de connectivité réseau entre les messages Processeur et Cassandra
Diagnostic
Remarque:Seuls les utilisateurs de cloud privé Edge peuvent effectuer les étapes suivantes. Si vous utilisez Edge Public Cloud, contactez l'assistance Apigee Edge.
- Annulez le déploiement et redéployez le proxy d'API. Si un problème de connectivité temporaire est survenu
entre le processeur de messages et Cassandra, alors l'erreur pourrait disparaître.
AVERTISSEMENT:N'annulez pas le déploiement si les erreurs sont détectées dans l'environnement de production. environnement.
- Si le problème persiste, exécutez l'appel du point d'accès de gestion ci-dessous pour vérifier
l'état du déploiement et vérifiez si des erreurs se sont produites au niveau des composants:
curl -u sysadmin@email.com https://management:8080/v1/o/<org>/apis/<api>/deployments
Exemple de résultat d'état de déploiement indiquant une erreur lors de l'accès au datastore sur un des processeurs de messages
{ "environment" : [ { "aPIProxy" : [ { "name" : "simple-python", "revision" : [ { "configuration" : { "basePath" : "/", "steps" : [ ] }, "name" : "1", "server" : [ { "status" : "deployed", "type" : [ "message-processor" ], "uUID" : "2acdd9b2-17de-4fbb-8827-8a2d4f3d7ada" }, { "error" : "Error while accessing datastore;Please retry later", "errorCode" : "datastore.ErrorWhileAccessingDataStore", "status" : "error", "type" : [ "message-processor" ], "uUID" : "42772085-ca67-49bf-a9f1-c04f2dc1fce3" } "state" : "error" }
- Redémarrez le ou les processeurs de messages qui indiquent l'erreur de déploiement. S'il y avait un
un problème réseau temporaire, l'erreur devrait disparaître:
/opt/apigee/apigee-service/bin/apigee-service edge-message-processor restart
- Répétez l'étape 2 pour voir si le déploiement réussit sur le processeur de messages qui était redémarré. Si aucune erreur n'est détectée, cela signifie que le problème est résolu.
- Vérifier si le processeur de messages parvient à se connecter à chaque nœud Cassandra sur le port 9042
et 9160:
<ph type="x-smartling-placeholder">
- </ph>
- Si telnet est disponible, utilisez Telnet:
telnet <Cassandra_IP> 9042 telnet <Cassandra_IP> 9160
- Si telnet n'est pas disponible, utilisez netcat pour vérifier la connectivité comme suit:
nc -vz <Cassandra_IP> 9042 nc -vz <Cassandra_IP> 9160
- Si vous obtenez la réponse "Connexion refusée" ou "Expiration du délai de connexion", votre équipe chargée des opérations réseau.
- Si telnet est disponible, utilisez Telnet:
- Si le problème persiste, vérifiez si chacun des nœuds Cassandra écoute sur le
ports 9042 et 9160:
netstat -an | grep LISTEN | grep 9042 netstat -an | grep LISTEN | grep 9160
- Si les nœuds Cassandra n'écoutent pas sur le port 9042 ou 9160, redémarrez le
nœud(s) Cassandra spécifique(s):
/opt/apigee/apigee-service/bin/apigee-service apigee-cassandra restart
- Si le problème persiste, contactez l'équipe chargée des opérations réseau.
- Annulez le déploiement et redéployez le proxy d'API. Si un problème de connectivité temporaire est survenu
entre le processeur de messages et Cassandra, alors l'erreur pourrait disparaître.
Solution
Collaborez avec l'équipe chargée des opérations réseau pour résoudre le problème de connectivité réseau entre le processeur de messages et Cassandra.
Erreurs de déploiement dues aux redémarrages de Cassandra
Les nœuds Cassandra sont généralement redémarrés régulièrement dans le cadre d'une maintenance de routine. Si l'API proxys sont déployés pendant les tâches de maintenance de Cassandra, puis les déploiements échouent en raison inaccessibilité au magasin de données Cassandra.
Remarque:Seuls les utilisateurs de cloud privé Edge peuvent effectuer les étapes suivantes. Si vous sont sur Edge Public Cloud, contactez l'assistance Apigee Edge.
Diagnostic
- Vérifiez que les nœuds Cassandra ont bien été redémarrés pendant le déploiement.
en consultant le journal Cassandra ou les journaux de temps de démarrage les plus récents du nœud Cassandra:
grep"shutdown"/opt/apigee/var/log/apigee-cassandra/system.log
Solution
- Vérifiez que Cassandra est opérationnel.
- Vérifiez si les processeurs de messages peuvent se connecter au datastore Cassandra sur le port 9042 et 9160.
Pic de latence des requêtes de lecture sur Cassandra
Un nombre élevé de lectures sur Cassandra dépend de cas d'utilisation et de modèles de trafic individuels. sur les proxies qui contiennent des stratégies qui nécessitent un accès en lecture depuis Cassandra.
Par exemple, si un appel GET pour le type d'attribution refresh_token est appelé pour les stratégies OAuth et que le d'actualisation est associé à de nombreux jetons d'accès, cela peut entraîner une grande quantité les lectures de Cassandra. Cela peut entraîner une augmentation de la latence des requêtes de lecture sur Cassandra.
Diagnostic
Remarque:Seuls les utilisateurs de cloud privé Edge peuvent effectuer les étapes suivantes. Si vous sont sur Edge Public Cloud, contactez l'assistance Apigee Edge.
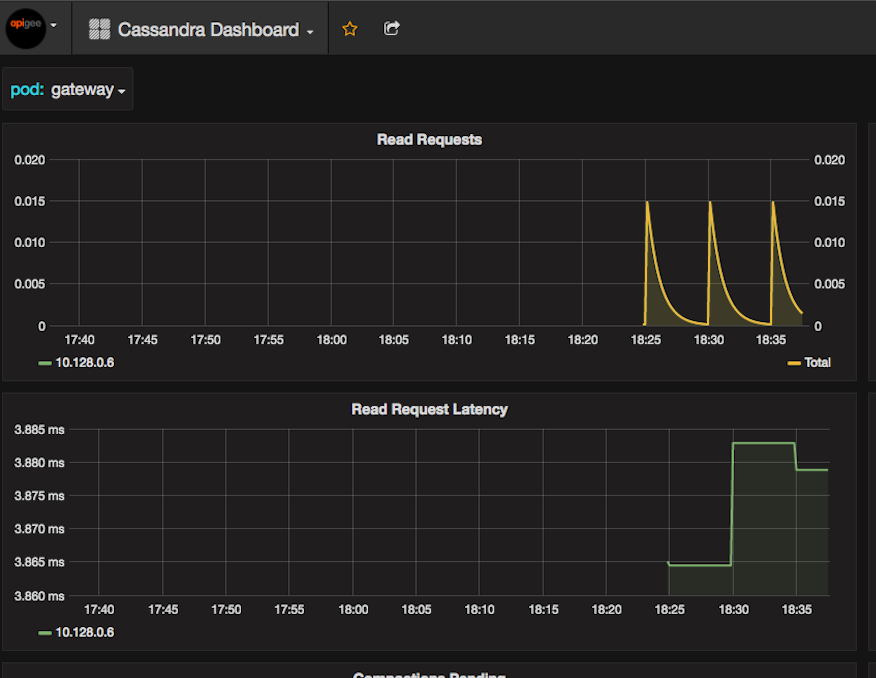
- Si vous avez installé le tableau de bord de surveillance bêta, consultez le tableau de bord Cassandra, et consultez la section "Demandes de lecture" graphique pour la période du problème. Consultez également le graphique pour "Lire "Request Latencies" (Latences des requêtes).
- Un autre outil permettant de vérifier les requêtes de lecture et les latences de lecture est la commande
nodetool cfstats. Voir Cassandra documentation pour en savoir plus sur l'utilisation de cette commande.
Solution
Remarque:Seuls les utilisateurs de cloud privé Edge peuvent effectuer les étapes suivantes. Si vous sont sur Edge Public Cloud, contactez l'assistance Apigee Edge.
- Réessayez d'effectuer le déploiement lorsque les performances de Cassandra seront revenues à la normale. Assurez-vous que l'intégralité L'anneau Cassandra est normal.
- (Facultatif) Effectuez un redémarrage progressif sur les processeurs de messages pour vous assurer que la connectivité établi.
- Pour une solution à long terme, examinez les modèles de trafic de l'API qui pourraient potentiellement contribuer les lectures supérieures dans le datastore Cassandra. Contactez l'assistance Apigee Edge pour résoudre ce problème.
- Si les nœuds Cassandra existants ne sont pas suffisants pour gérer le trafic entrant, alors augmenter la capacité matérielle ou le nombre de nœuds du datastore Cassandra en conséquence.
API Bundle de proxy de plus de 15 Mo
La taille des groupes de proxys d'API est limitée à 15 Mo sur Cassandra. Si la taille de l'API dépasse 15 Mo, le message "Erreur lors de l'accès au magasin de données" s'affiche. lorsque vous de déployer le proxy d'API.
Diagnostic
Remarque:Seuls les utilisateurs de cloud privé Edge peuvent effectuer les étapes suivantes. Si vous sont sur Edge Public Cloud, contactez l'assistance Apigee Edge.
- Vérifier les journaux du processeur de messages
(
/opt/apigee/var/log/edge-message-processor/logs/system.log) et voyez s'il y a des erreurs se sont produites lors du déploiement du proxy d'API spécifique. - Si vous voyez une erreur semblable à celle illustrée dans la figure ci-dessous, cela signifie que l'erreur de déploiement
est que la taille du groupe de proxys d'API est > 15 Mo.
2016-03-23 18:42:18,517 main ERROR DATASTORE.CASSANDRA - AstyanaxCassandraClient.fetchDynamicCompositeColumns() : Error while querying columnfamily : [api_proxy_revisions_r21, adevegowdat@v1-node-js] for rowkey:{} com.netflix.astyanax.connectionpool.exceptions.TransportException: TransportException: [host=None(0.0.0.0):0, latency=159(486), attempts=3]org.apache.thrift.transport.TTransportException: Frame size (20211500) larger than max length (16384000)! at com.netflix.astyanax.thrift.ThriftConverter.ToConnectionPoolException(ThriftConverter.java:197) ~[astyanax-thrift-1.56.43.jar:na] at com.netflix.astyanax.thrift.AbstractOperationImpl.execute(AbstractOperationImpl.java:65) ~[astyanax-thrift-1.56.43.jar:na] ...<snipped> Caused by: org.apache.thrift.transport.TTransportException: Frame size (20211500) larger than max length (16384000)! at org.apache.thrift.transport.TFramedTransport.readFrame(TFramedTransport.java:137) ~[libthrift-0.9.1.jar:0.9.1] at org.apache.thrift.transport.TFramedTransport.read(TFramedTransport.java:101) ~[libthrift-0.9.1.jar:0.9.1] at org.apache.thrift.transport.TTransport.readAll(TTransport.java:84) ~[libthrift-0.9.1.jar:0.9.1] ...<snipped>
Solution
Le groupe de proxys d'API sera volumineux s'il y a trop de fichiers de ressources. Utilisez les éléments suivants : solutions pour résoudre ce problème:
Solution n° 1: déplacer les fichiers de ressources au niveau de l'environnement ou de l'organisation
- Déplacez tous les fichiers de ressources, tels que les fichiers et modules de script NodeJS, les fichiers JavaScript, fichiers JAR au niveau de l'environnement ou de l'organisation. Pour en savoir plus sur les fichiers de ressources, consultez la documentation Edge.
- Déployez le proxy d'API et vérifiez si l'erreur disparaît.
Si le problème persiste ou si vous ne pouvez pas déplacer les fichiers de ressources vers l'environnement ou l'organisation pour une raison quelconque, puis appliquez la solution n°2.
Solution n° 2: Augmentez la taille du groupe de proxys d'API sur Cassandra
Remarque:Seuls les utilisateurs de cloud privé Edge peuvent effectuer les étapes suivantes. Si vous sont sur Edge Public Cloud, contactez l'assistance Apigee Edge.
Suivez ces étapes pour augmenter la taille de la propriété Cassandra thrift frame transport size, qui contrôle la taille maximale du bundle de proxy d'API autorisé dans Périphérie:
- S'il n'existe pas, créez le fichier suivant:
/opt/apigee/customer/application/cassandra.properties
- Ajoutez la ligne suivante au fichier, en remplaçant <size> avec le paramètre de taille requis
pour le groupe volumineux:
conf_cassandra_thrift_framed_transport_size_in_mb=<size>
- Redémarrez Cassandra :
/opt/apigee/apigee-service/bin/apigee-service edge-management-server restart
- Répétez les étapes 1 à 3 sur tous les nœuds Cassandra du cluster.
Si le problème persiste, contactez l'assistance Apigee Edge.