
<ph type="x-smartling-placeholder"></ph>
Sie sehen die Dokumentation zu Apigee Edge.
Gehen Sie zur
Apigee X-Dokumentation. Weitere Informationen
Symptom
Die Clientanwendung empfängt einen Zeitüberschreitungsfehler für API-Anfragen oder die Anfrage wird beendet. während die API-Anfrage noch auf Apigee ausgeführt wird.
Sie beobachten den Statuscode 499 für solche API-Anfragen im API-Monitoring und
NGINX-Zugriffsprotokolle. Manchmal sehen Sie in API Analytics unterschiedliche Statuscodes,
zeigt den vom Message Processor zurückgegebenen Statuscode an.
Fehlermeldung
Bei Clientanwendungen können folgende Fehler auftreten:
curl: (28) Operation timed out after 6001 milliseconds with 0 out of -1 bytes received
Was führt zu Zeitüberschreitungen beim Client?
Der typische Pfad für eine API-Anfrage auf der Edge-Plattform lautet Kunde > Router > Message Processor > Back-End-Server, wie in der folgenden Abbildung dargestellt:
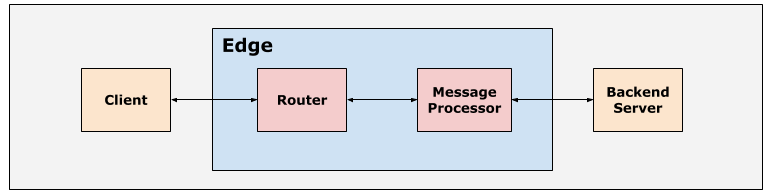
Die Router und Message Processor innerhalb der Apigee Edge-Plattform werden mit geeigneten Standardzeitüberschreitungswerte, um sicherzustellen, dass die API-Anfragen nicht zu lange dauern.
Zeitüberschreitung auf dem Client
Clientanwendungen können entsprechend Ihren Anforderungen mit einem geeigneten Zeitüberschreitungswert konfiguriert werden.
Bei Clients wie Webbrowsern und mobilen Apps sind vom Betriebssystem festgelegte Zeitüberschreitungen festgelegt.
Zeitüberschreitung auf dem Router
Das auf Routern konfigurierte Zeitlimit beträgt standardmäßig 57 Sekunden. Dies ist die maximale Zeitspanne, Der API-Proxy kann ab dem Zeitpunkt, an dem die API-Anfrage in Edge empfangen wird, bis zur Antwort ausgeführt werden: einschließlich der Back-End-Antwort und aller ausgeführten Richtlinien. Standardeinstellung kann das Zeitlimit auf den Routern und virtuellen Hosts überschrieben werden, wie in <ph type="x-smartling-placeholder"></ph> E/A-Zeitlimit auf Routern konfigurieren
Zeitüberschreitung bei Message Processor
Das Standardzeitlimit für Message Processors beträgt 55 Sekunden. Dies ist der maximale Betrag Zeit, die der Back-End-Server benötigt, um die Anfrage zu verarbeiten und auf die Nachricht zu antworten Prozessor. Das Standardzeitlimit kann im Message Processors oder in der API überschrieben werden. Proxy, wie unter <ph type="x-smartling-placeholder"></ph> E/A-Zeitüberschreitung bei Message Processors konfigurieren
Wenn der Client die Verbindung mit dem Router schließt, bevor das Zeitlimit für den API-Proxy überschritten wurde, haben Sie
den Zeitüberschreitungsfehler für die jeweilige API-Anfrage beobachtet. Der Statuscode 499 Client
Closed Connection wird für solche Anfragen im Router protokolliert. Dies ist in der API zu sehen.
Monitoring- und NGINX-Zugriffslogs.
Mögliche Ursachen
In Edge sind die typischen Ursachen für den Fehler 499 Client Closed Connection folgende:
| Ursache | Beschreibung | Anleitungen zur Fehlerbehebung gelten für |
|---|---|---|
| Der Client hat die Verbindung abrupt geschlossen | Dies geschieht, wenn der Client die Verbindung trennt, weil der Endnutzer den Vorgang abbricht. bevor sie abgeschlossen wird. | Nutzer von öffentlichen und privaten Clouds |
| Zeitüberschreitung für Clientanwendung | Dies geschieht, wenn die Clientanwendung das Zeitlimit überschreitet, bevor der API-Proxy Zeit hat, zu verarbeiten und die Antwort zu senden. In der Regel geschieht dies, wenn die Clientzeitüberschreitung kürzer ist. als die Zeitüberschreitung des Routers. | Nutzer von öffentlichen und privaten Clouds |
Allgemeine Diagnoseschritte
Verwenden Sie eines der folgenden Tools oder Techniken, um diesen Fehler zu diagnostizieren:
- API-Monitoring
- NGINX-Zugriffslogs
API-Monitoring
<ph type="x-smartling-placeholder">So diagnostizieren Sie den Fehler mithilfe von API-Monitoring:
- Wechseln Sie zum Bereich Analysieren > API-Monitoring > Untersuchen.
- Filtern Sie nach
4xxFehlern und wählen Sie den Zeitraum aus. - Stell den Statuscode in den Vergleich mit Time ein.
- Wählen Sie eine Zelle mit
499Fehlern aus, wie unten dargestellt: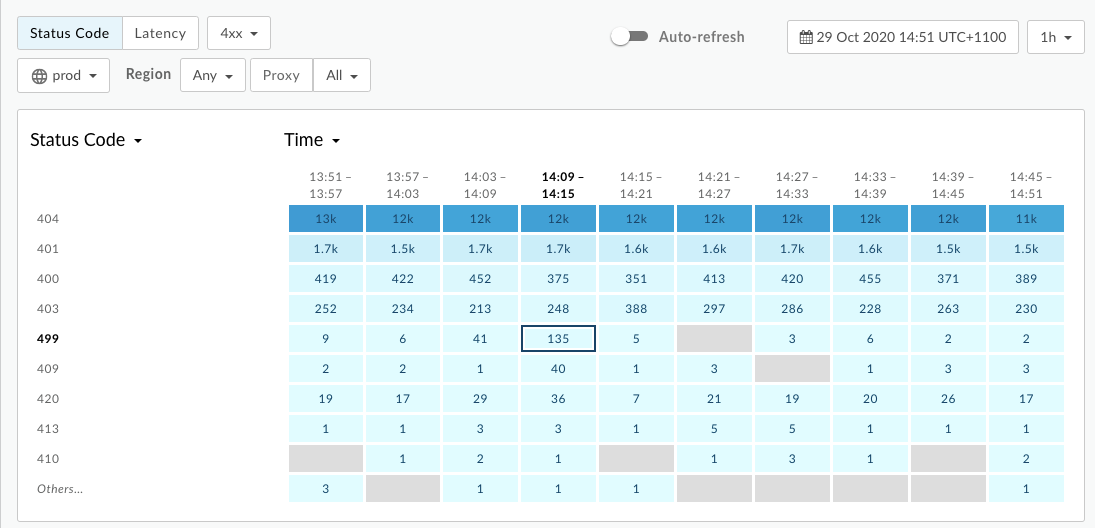
- Die Informationen zum Fehler
499werden im rechten Bereich (siehe unten):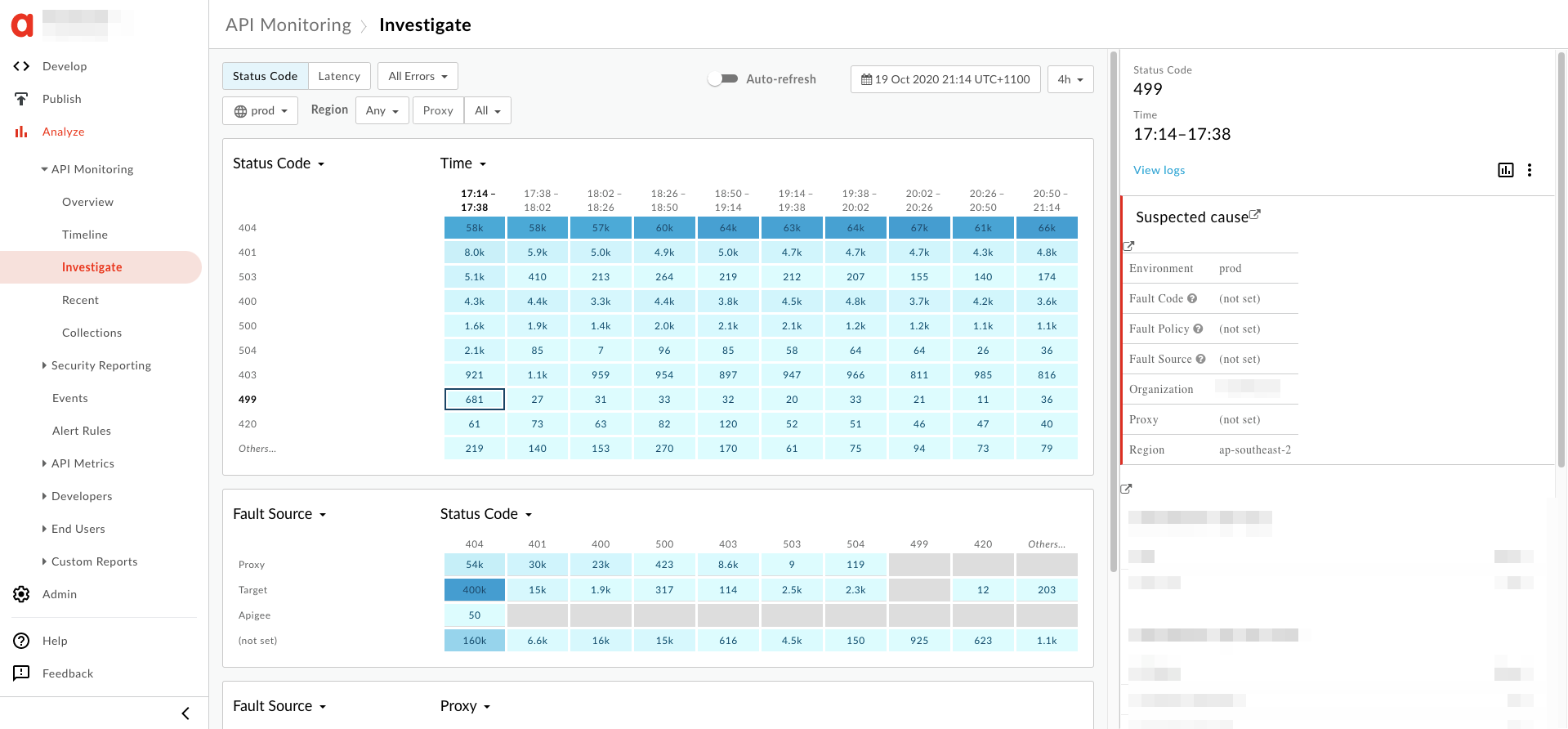
- Klicken Sie im rechten Bereich auf Logs ansehen.
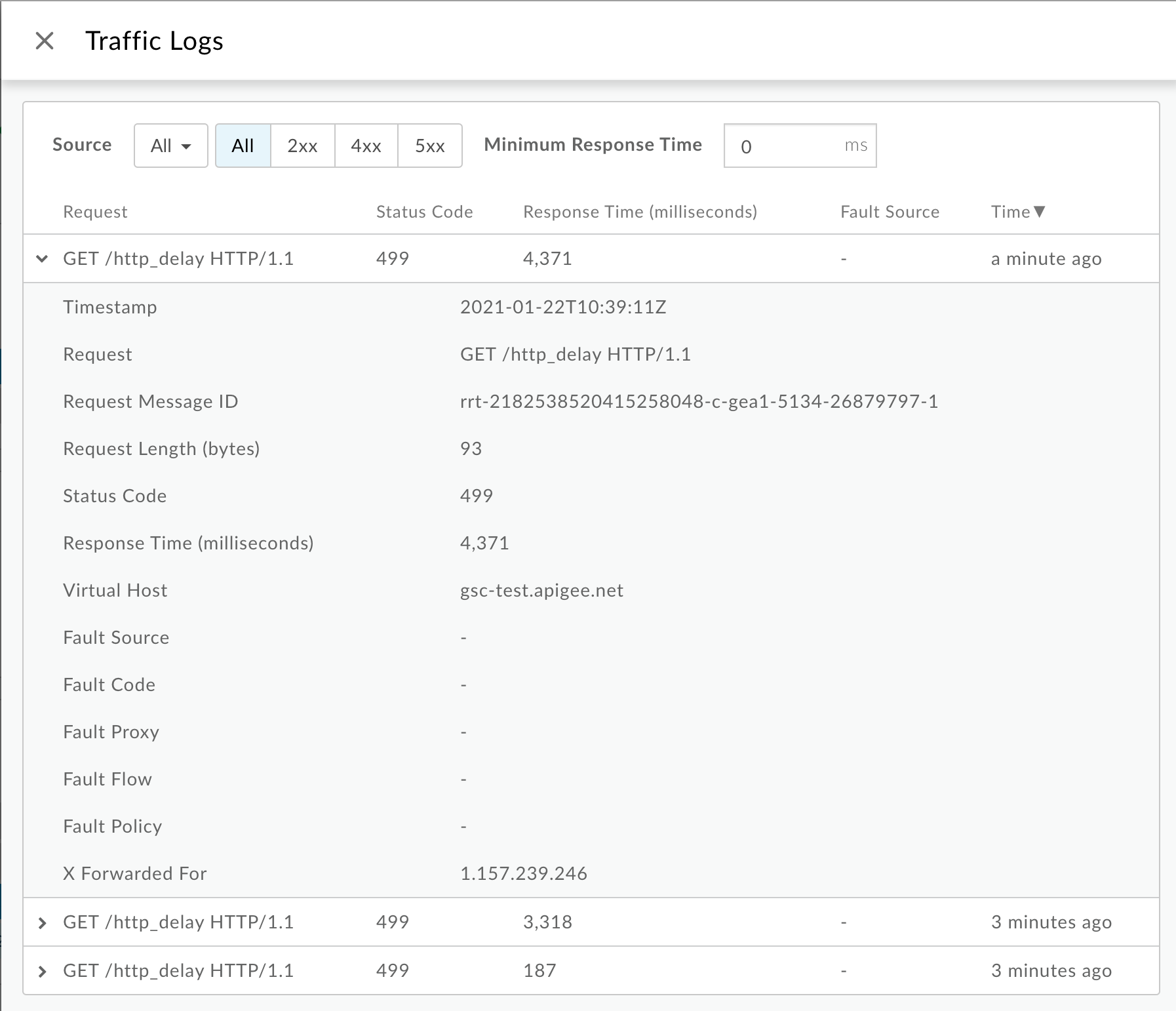
Beachten Sie im Fenster Traffic-Logs die folgenden Details für einige
499Fehler:- Anfrage:Stellt die Anfragemethode und den URI für die Aufrufe bereit.
- Response Time (Antwortzeit): Zeigt die insgesamt verstrichene Zeit für die Anfrage an.
Sie können alle Logs auch mithilfe der API-Überwachung abrufen. GET-Logs Für Durch Abfragen von Logs für
org,envtimeRangeundstatuskönnten Sie dann alle Logs für Transaktionen, bei denen das Zeitlimit des Clients überschritten wurde.Da API-Monitoring den Proxy für HTTP
499auf-setzt können Sie die API verwenden, (Logs API) zum Abrufen der zugehörigen Proxy für den virtuellen Host und den virtuellen Pfad.For example :
curl "https://apimonitoring.enterprise.apigee.com/logs/apiproxies?org=ORG&env=ENV&select=https://VIRTUAL_HOST/BASEBATH" -H "Authorization: Bearer $TOKEN"
- Überprüfen Sie die Reaktionszeit auf weitere
499-Fehler und prüfen Sie, ob die Response Time (Reaktionszeit) in allen Conversion-Spalten konstant ist, z. B. 30 Sekunden,499Fehler.
NGINX-Zugriffslogs
<ph type="x-smartling-placeholder">So diagnostizieren Sie den Fehler mithilfe von NGINX-Zugriffslogs:
- Wenn Sie ein Private Cloud-Nutzer sind, können Sie mithilfe von NGINX-Zugriffslogs ermitteln,
enthält die wichtigsten Informationen zu HTTP-
499-Fehlern. - Prüfen Sie die NGINX-Zugriffslogs:
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - Suchen, um zu sehen, ob es während eines bestimmten Zeitraums
499Fehler gibt (wenn das Problem in der Vergangenheit aufgetreten ist) oder wenn immer noch Anfragen mit499 - Beachten Sie zu einigen der
499-Fehler die folgenden Informationen: <ph type="x-smartling-placeholder">- </ph>
- Gesamtantwortzeit
- Anfrage-URI
- User-Agent
Beispiel 499 Fehler aus NGINX-Zugriffslog:
2019-08-23T06:50:07+00:00 rrt-03f69eb1091c4a886-c-sy 50.112.119.65:47756 10.10.53.154:8443 10.001 - - 499 - 422 0 GET /v1/products HTTP/1.1 - okhttp/3.9.1 api.acme.org rrt-03f69eb1091c4a886-c-sy-13001-6496714-1 50.112.119.65 - - - - - - - -1 - - dc-1 router-pod-1 rt-214-190301-0020137-latest-7d 36 TLSv1.2 gateway-1 dc-1 acme prod https -
Für dieses Beispiel sehen wir die folgenden Informationen:
- Gesamtantwortzeit:
10.001Sekunden. Dies bedeutet, dass der Zeitlimit des Clients nach 10.001 Sekunden überschritten - Anfrage:
GET /v1/products - Host:
api.acme.org - User-Agent:
okhttp/3.9.1
- Überprüfen Sie, ob die Gesamtantwortzeit und der User-Agent konsistent sind.
für alle
499Fehler.
Ursache: Client hat die Verbindung plötzlich getrennt
Diagnose
- Wenn eine API von einer Single-Page-Anwendung aufgerufen wird, die in einem Browser oder einer mobilen Anwendung ausgeführt wird, bricht der Browser die Anfrage ab, wenn der Endnutzer den Browser plötzlich schließt, zu einer anderen zu einer anderen Webseite im selben Tab wechseln oder das Laden der Seite durch Klicken oder Tippen wird nicht mehr geladen.
- In diesem Fall variieren die Transaktionen mit dem HTTP-Status
499in der Regel . -
Sie können die Ursache ermitteln, indem Sie die Antwortzeit vergleichen und prüfen, ob
Er unterscheidet sich für jeden der
499-Fehler bei Verwendung von API-Überwachung oder NGINX-Zugriff wie unter Allgemeine Diagnoseschritte erläutert.
Auflösung
- Das ist normal und kein Grund zur Sorge, wenn die HTTP-Fehler
499in kleinen Mengen. -
Wenn das Problem häufig bei demselben URL-Pfad auftritt, kann es daran liegen, dass der jeweilige Proxy ist sehr langsam und die Nutzer sind nicht bereit zu warten.
Sobald Sie wissen, welcher Proxy betroffen sein könnte, verwenden Sie die Methode Latenz Analyse-Dashboard, um die Ursache der Proxy-Latenz zu untersuchen.
- Ermitteln Sie in diesem Fall den betroffenen Proxy mithilfe der Schritte unter Häufige Diagnoseschritte:
- Verwenden Sie die Methode Latenzanalyse-Dashboard, um die Ursache der Proxy-Latenz zu untersuchen um das Problem zu beheben.
- Wenn Sie feststellen, dass die Latenz für den spezifischen Proxy erwartet wird, haben Sie möglicherweise um Ihre Nutzer darüber zu informieren, dass es einige Zeit dauern wird, bis der Proxy reagiert.
Ursache: Zeitüberschreitung bei Clientanwendung
Dies kann in verschiedenen Szenarien geschehen.
-
Es wird erwartet, dass die Verarbeitung der Anfrage eine bestimmte Zeit (z. B. 10 Sekunden) in Anspruch nimmt.
unter normalen Betriebsbedingungen. Die Client-Anwendung ist jedoch mit einer falschen
Zeitüberschreitungswert (etwa 5 Sekunden), der dazu führt, dass die Client-Anwendung vor dem
Die API-Anfrage ist abgeschlossen, was zu
499führt. In diesem Fall müssen wir Client-Zeitlimit auf einen geeigneten Wert festzulegen. - Ein Zielserver oder Callout dauert länger als erwartet. In diesem Fall müssen Sie Komponente und passen Sie auch die Timeout-Werte entsprechend an.
- Der Client benötigte die Antwort nicht mehr und wurde daher abgebrochen. Dies kann bei einer hohen APIs wie die automatische Vervollständigung oder „Short Polling“ verwendet werden.
Diagnose
API-Monitoring- oder NGINX-Zugriffslogs
Diagnostizieren Sie den Fehler mithilfe von API-Überwachungs- oder NGINX-Zugriffslogs:
- Prüfen Sie die API-Überwachungsprotokolle oder NGINX-Zugriffslogs für die HTTP-
499-Transaktionen, wie unter Häufige Diagnoseschritte. - Prüfen Sie, ob die Antwortzeit für alle
499-Fehler konsistent ist. - Wenn ja, kann es sein, dass eine bestimmte Clientanwendung ein festes Zeitlimit konfiguriert hat
zu verstehen. Wenn ein API-Proxy oder -Zielserver langsam reagiert, kommt es beim Client zu einer Zeitüberschreitung.
bevor der Proxy das Zeitlimit überschreitet. Dies führt zu einer großen Anzahl von HTTP-
499sfür den denselben URI-Pfad. Ermitteln Sie in diesem Fall den User-Agent aus den NGINX-Zugriffslogs, können Sie die spezifische Client-Anwendung ermitteln. - Es könnte auch sein, dass sich vor Apigee wie Akamai ein Load-Balancer befindet, F5, AWS ELB usw. Wenn Apigee hinter einem benutzerdefinierten Load-Balancer ausgeführt wird, wird die Anfrage Das Zeitlimit des Load-Balancers muss so konfiguriert sein, dass es größer als das Apigee API-Zeitlimit ist. Von hat der Apigee-Router eine Zeitüberschreitung nach 57 Sekunden, daher empfiehlt es sich, eine Anfrage zu konfigurieren, auf dem Load-Balancer eine Zeitüberschreitung von 60 Sekunden hat.
Trace
Fehler mit Trace diagnostizieren
Wenn das Problem weiterhin aktiv ist (499 Fehler treten weiterhin auf), führen Sie den
folgenden Schritten:
- Aktivieren Sie die Trace-Sitzung für die betroffene API in der Edge-Benutzeroberfläche.
- Warten Sie entweder, bis der Fehler auftritt, oder führen Sie, wenn Sie den API-Aufruf haben, einige API-Aufrufe aus und den Fehler zu reproduzieren.
- Überprüfen Sie die verstrichene Zeit in jeder Phase und notieren Sie sich die Phase, in der die meiste Zeit liegt. ausgegeben wird.
- Wenn Sie den Fehler mit der längsten verstrichenen Zeit sofort nach einer der
Phasen folgt, zeigt sie an, dass der Backend-Server langsam ist oder sehr lange
zur Bearbeitung des Antrags:
<ph type="x-smartling-placeholder">
- </ph>
- Anfrage an Zielserver gesendet
- ServiceCallout-Richtlinie
Hier ist ein Beispiel für ein UI-Trace, das eine Gateway-Zeitüberschreitung zeigt, nachdem die Anfrage an den Zielserver gesendet:
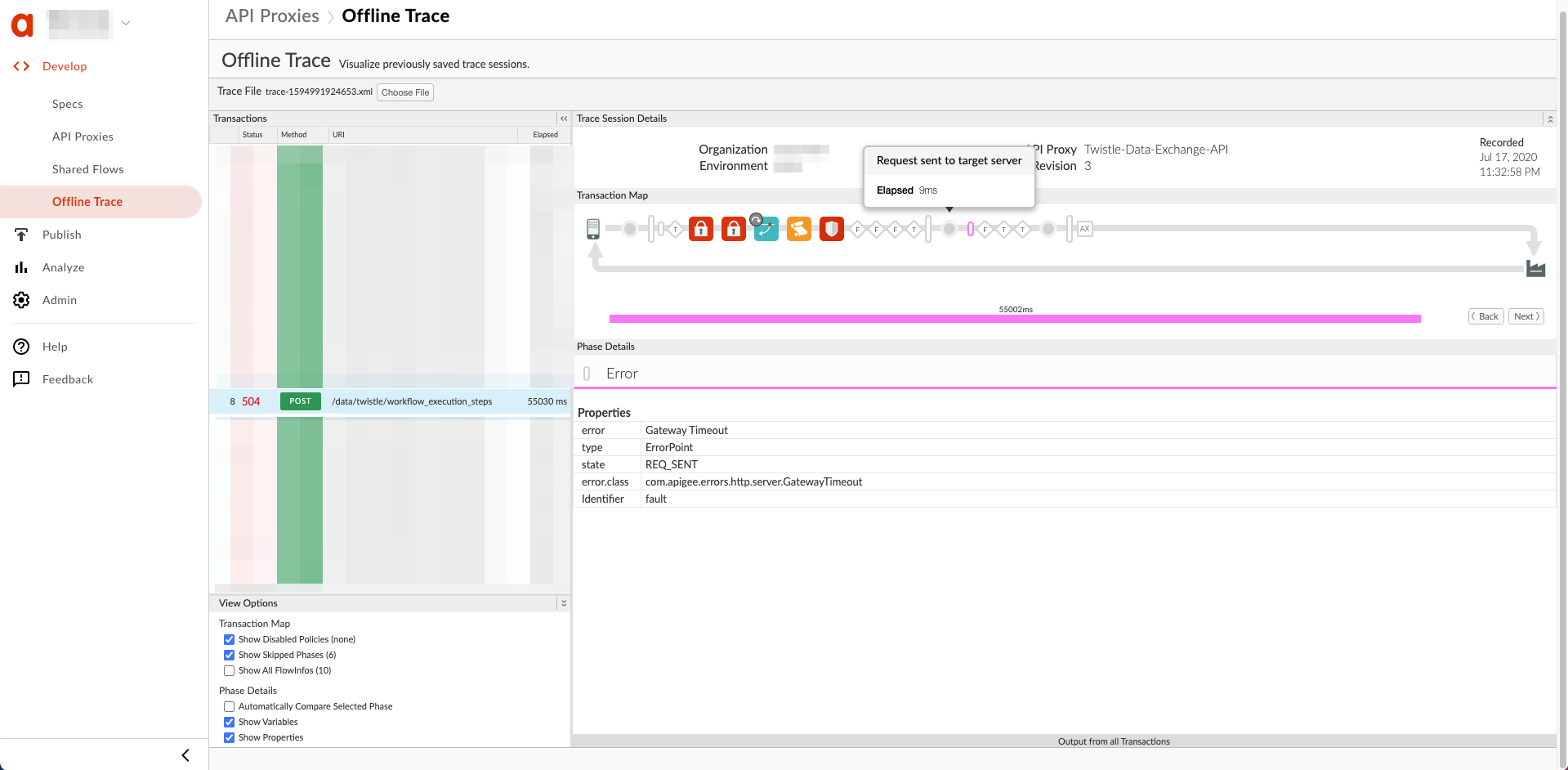
Auflösung
- Weitere Informationen finden Sie unter Best Practices für die Konfiguration des E/A-Zeitlimits, damit Sie verstehen, welche Werte für Zeitüberschreitungen festgelegt werden sollten zu verschiedenen Komponenten, die am API-Anfragefluss über Apigee Edge beteiligt sind.
- Legen Sie in der Clientanwendung einen geeigneten Zeitüberschreitungswert fest, der den die Best Practices an.
Wenn das Problem weiterhin besteht, gehen Sie zu Diagnoseinformationen müssen erfasst werden .
Erfassen von Diagnoseinformationen erforderlich
Wenn das Problem weiterhin besteht, erfassen Sie die folgenden Diagnoseinformationen und wenden Sie sich an den Apigee Edge-Support.
Wenn Sie ein Nutzer von Public Cloud sind, geben Sie die folgenden Informationen an:
- Name der Organisation
- Name der Umgebung
- API-Proxy-Name
- Vollständiger
curl-Befehl zum Reproduzieren des Zeitüberschreitungsfehlers - Ablaufverfolgungsdatei für die API-Anfragen, für die Client-Zeitüberschreitungsfehler auftreten
Wenn Sie ein Private Cloud-Nutzer sind, geben Sie die folgenden Informationen an:
- Vollständige Fehlermeldung für fehlgeschlagene Anfragen
- Name der Umgebung
- API-Proxy-Bundle
- Ablaufverfolgungsdatei für die API-Anfragen, für die Client-Zeitüberschreitungsfehler auftreten
- NGINX-Zugriffslogs (
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - Systemprotokolle für Message Processor (
/opt/apigee/var/log/edge-message-processor/logs/system.log)