
คุณกำลังดูเอกสารประกอบ Apigee Edge
ไปที่
เอกสารประกอบเกี่ยวกับ Apigee X. ข้อมูล
ลักษณะปัญหา
แอปพลิเคชันไคลเอ็นต์ได้รับข้อผิดพลาดการหมดเวลาสำหรับคำขอ API หรือคำขอถูกยกเลิก ทันทีขณะที่คำขอ API ยังคงดำเนินการใน Apigee
คุณจะเห็นรหัสสถานะ 499 สำหรับคำขอ API ดังกล่าวในการตรวจสอบ API และ
บันทึกการเข้าถึง NGINX บางครั้งคุณจะเห็นรหัสสถานะที่แตกต่างกันใน API Analytics
จะแสดงรหัสสถานะที่แสดงผลโดย Message Processor
ข้อความแสดงข้อผิดพลาด
แอปพลิเคชันไคลเอ็นต์อาจเห็นข้อผิดพลาด เช่น
curl: (28) Operation timed out after 6001 milliseconds with 0 out of -1 bytes received
สาเหตุของการหมดเวลาของไคลเอ็นต์คืออะไร
เส้นทางทั่วไปสำหรับคำขอ API บนแพลตฟอร์ม Edge คือ ไคลเอ็นต์ > เราเตอร์ > ตัวประมวลผลข้อความ > เซิร์ฟเวอร์แบ็กเอนด์ดังที่แสดงในรูปต่อไปนี้
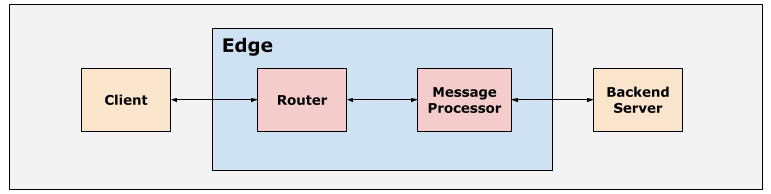
เราเตอร์และตัวประมวลผลข้อความภายในแพลตฟอร์ม Apigee Edge ได้รับการตั้งค่าด้วย ค่าระยะหมดเวลาเริ่มต้นเพื่อให้มั่นใจว่าคำขอ API จะใช้เวลาไม่นานเกินไป
หมดเวลาในไคลเอ็นต์
คุณสามารถกำหนดค่าแอปพลิเคชันไคลเอ็นต์ด้วยค่าระยะหมดเวลาที่เหมาะสมตามความต้องการของคุณ
ไคลเอ็นต์ เช่น เว็บเบราว์เซอร์และแอปบนอุปกรณ์เคลื่อนที่ หมดเวลาที่ระบบปฏิบัติการกำหนดไว้
ระยะหมดเวลาบนเราเตอร์
ระยะหมดเวลาเริ่มต้นที่กำหนดค่าไว้ในเราเตอร์คือ 57 วินาที นี่คือระยะเวลาสูงสุด พร็อกซี API จะทำงานได้ตั้งแต่เวลาที่ได้รับคำขอ API ใน Edge จนถึงช่วงการตอบสนอง ส่งกลับ ซึ่งรวมถึงการตอบกลับแบ็กเอนด์และนโยบายทั้งหมดที่ลงนาม ค่าเริ่มต้น สามารถลบล้างระยะหมดเวลาบนเราเตอร์และโฮสต์เสมือนได้ตามที่อธิบายไว้ใน การกำหนดค่าการหมดเวลา I/O บนเราเตอร์
หมดเวลาสำหรับตัวประมวลผลข้อความ
ระยะหมดเวลาเริ่มต้นที่กำหนดค่าไว้ในโปรแกรมประมวลผลข้อความคือ 55 วินาที นี่คือจำนวนสูงสุด เวลาที่เซิร์ฟเวอร์แบ็กเอนด์สามารถใช้ในการประมวลผลคำขอและตอบกลับข้อความ โปรเซสเซอร์ คุณสามารถลบล้างระยะหมดเวลาเริ่มต้นได้ในตัวประมวลผลข้อความหรือภายใน API พร็อกซีตามที่อธิบายไว้ใน การกำหนดค่าระยะหมดเวลา I/O ใน Message Processor
หากไคลเอ็นต์ปิดการเชื่อมต่อกับเราเตอร์ก่อนที่พร็อกซี API จะหมดเวลา
จะสังเกตเห็นข้อผิดพลาดการหมดเวลาของคำขอ API ที่ระบุ รหัสสถานะ 499 Client
Closed Connection จะบันทึกในเราเตอร์สำหรับคำขอดังกล่าว ซึ่งสังเกตได้ใน API
บันทึกการตรวจสอบและการเข้าถึง NGINX
สาเหตุที่เป็นไปได้
ใน Edge สาเหตุทั่วไปของข้อผิดพลาด 499 Client Closed Connection คือ
| สาเหตุ | คำอธิบาย | วิธีการแก้ปัญหาสำหรับ |
|---|---|---|
| ไคลเอ็นต์ปิดการเชื่อมต่อกะทันหัน | กรณีนี้จะเกิดขึ้นเมื่อไคลเอ็นต์ปิดการเชื่อมต่อเนื่องจากผู้ใช้ปลายทางยกเลิกการเชื่อมต่อ ก่อนที่จะเสร็จสมบูรณ์ | ผู้ใช้ระบบคลาวด์สาธารณะและ Private Cloud |
| แอปพลิเคชันไคลเอ็นต์หมดเวลา | กรณีนี้จะเกิดขึ้นเมื่อแอปพลิเคชันไคลเอ็นต์หมดเวลาก่อนที่พร็อกซี API จะมีเวลาดำเนินการ ประมวลผลและส่งการตอบกลับ กรณีนี้มักเกิดขึ้นเมื่อระยะหมดเวลาของไคลเอ็นต์สั้นลง มากกว่าระยะหมดเวลาของเราเตอร์ | ผู้ใช้ระบบคลาวด์สาธารณะและ Private Cloud |
ขั้นตอนการวินิจฉัยทั่วไป
ใช้เครื่องมือ/เทคนิคต่อไปนี้เพื่อวินิจฉัยข้อผิดพลาดนี้
- การตรวจสอบ API
- บันทึกการเข้าถึง NGINX
การตรวจสอบ API
วิธีวินิจฉัยข้อผิดพลาดโดยใช้การตรวจสอบ API
- ไปที่ วิเคราะห์ > การตรวจสอบ API > หน้าตรวจสอบ
- กรองหาข้อผิดพลาด
4xxรายการและเลือกกรอบเวลา - พล็อตรหัสสถานะเทียบกับเวลา
- เลือกเซลล์ที่มีข้อผิดพลาด
499รายการดังที่แสดงด้านล่าง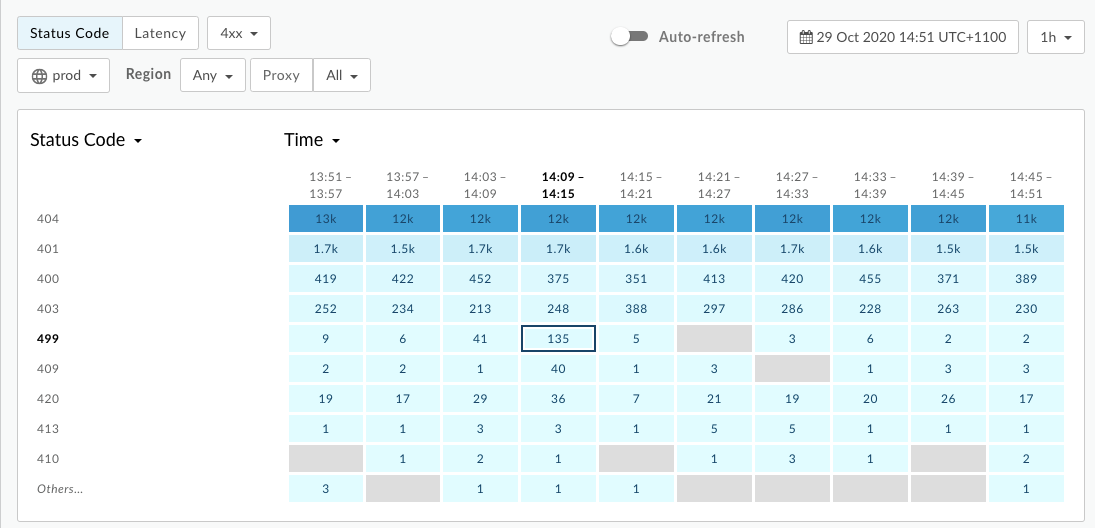
- คุณจะเห็นข้อมูลเกี่ยวกับข้อผิดพลาด
499ในแผงด้านขวามือในรูปแบบ แสดงอยู่ด้านล่าง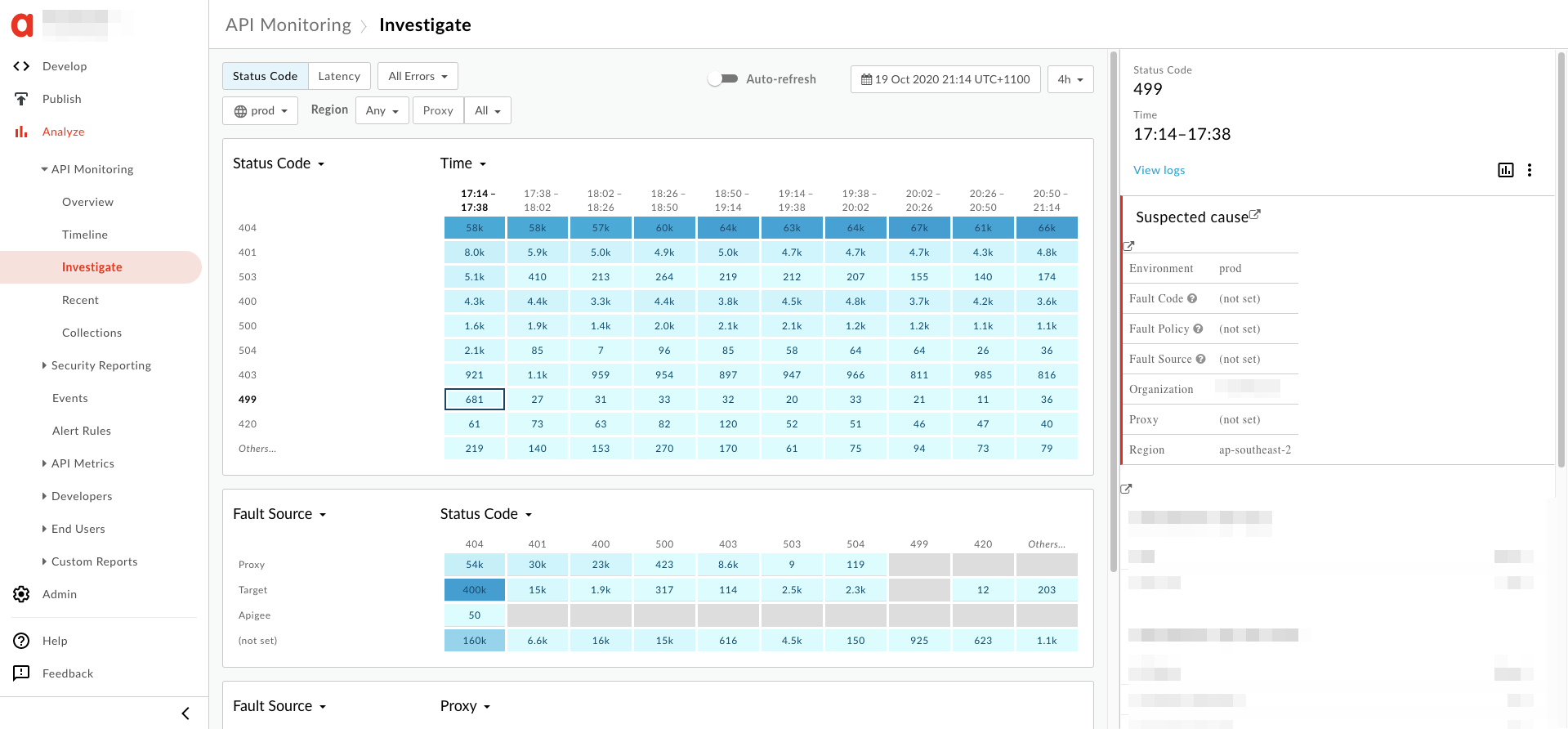
- คลิกดูบันทึกในแผงด้านขวามือ
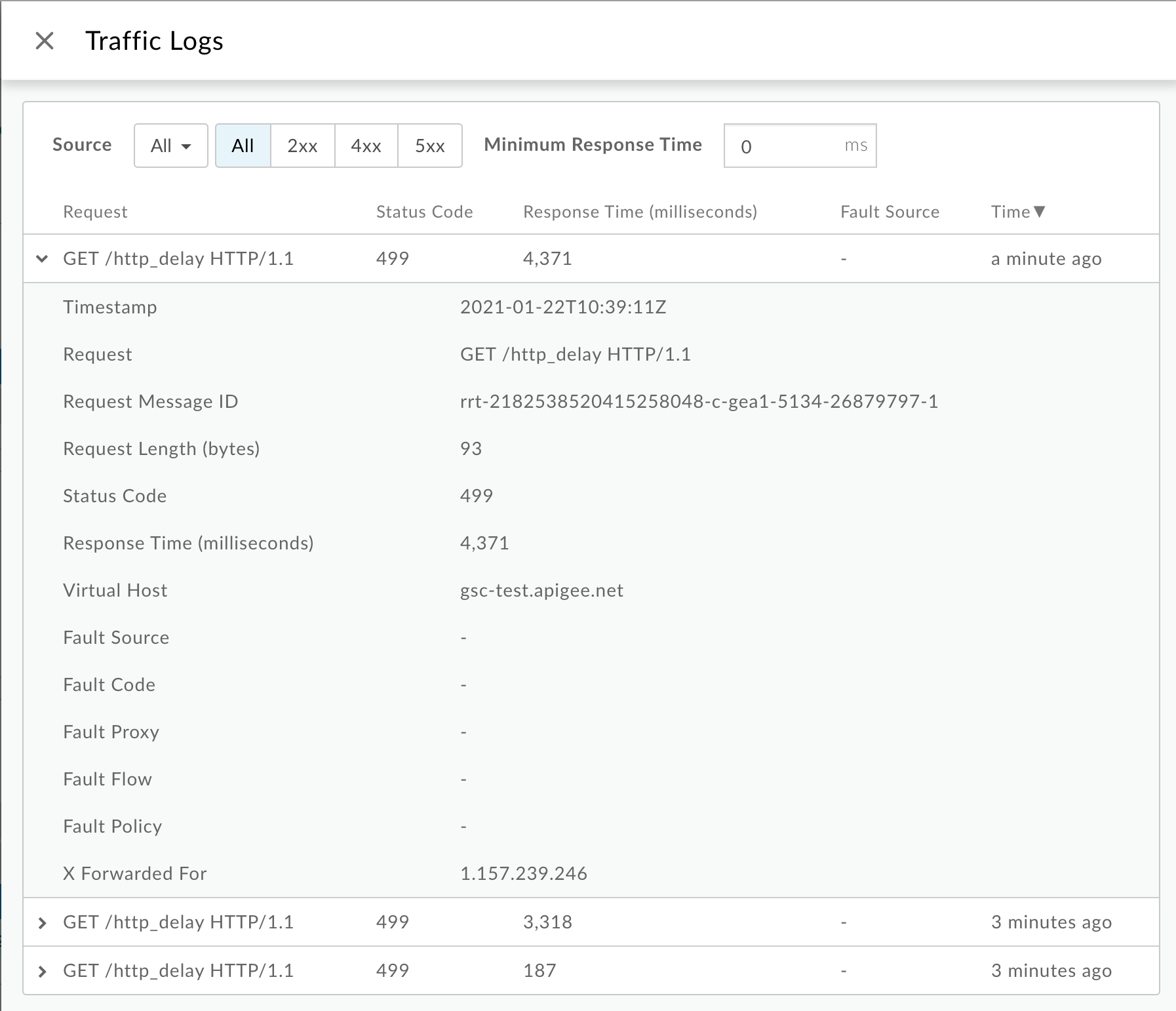
จากหน้าต่างบันทึกการรับส่งข้อมูล ให้สังเกตรายละเอียดต่อไปนี้สำหรับ
499บางรายการ ข้อผิดพลาด:- คำขอ:ระบุวิธีการส่งคำขอและ URI ที่ใช้สำหรับการเรียก
- เวลา การตอบกลับ:ค่านี้จะแสดงเวลาทั้งหมดที่ผ่านไปสำหรับคำขอ
นอกจากนี้ คุณยังรับบันทึกทั้งหมดโดยใช้การตรวจสอบ API ได้ด้วย API รับบันทึก สำหรับ ตัวอย่างเช่น จากการค้นหาบันทึกสำหรับ
org,envtimeRangeและstatusคุณจะสามารถดาวน์โหลด บันทึกธุรกรรมที่ไคลเอ็นต์หมดเวลาเนื่องจากการตรวจสอบ API ตั้งค่าพร็อกซีเป็น
-สำหรับ HTTP499คุณสามารถใช้ API (Logs API) เพื่อรับฟิลด์ พร็อกซีที่เกี่ยวข้องสำหรับโฮสต์และเส้นทางเสมือนFor example :
curl "https://apimonitoring.enterprise.apigee.com/logs/apiproxies?org=ORG&env=ENV&select=https://VIRTUAL_HOST/BASEBATH" -H "Authorization: Bearer $TOKEN"
- ตรวจสอบเวลาในการตอบสนองเพื่อหาข้อผิดพลาดเพิ่มเติม
499และตรวจสอบว่า เวลาในการตอบสนองมีความสม่ำเสมอ (สมมติว่า 30 วินาที) ในทุก ข้อผิดพลาด499รายการ
บันทึกการเข้าถึง NGINX
วิธีวินิจฉัยข้อผิดพลาดโดยใช้บันทึกการเข้าถึง NGINX
- หากคุณเป็นผู้ใช้ Private Cloud คุณสามารถใช้บันทึกการเข้าถึง NGINX ในการระบุ
ข้อมูลคีย์เกี่ยวกับข้อผิดพลาด HTTP
499 - ตรวจสอบบันทึกการเข้าถึง NGINX
วันที่/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - ค้นหาว่ามีข้อผิดพลาด
499รายการในช่วงระยะเวลาที่ระบุหรือไม่ (หากเคยมีปัญหาเกิดขึ้นในอดีต) หรือหากมีคำขอที่ยังคงดำเนินการไม่สำเร็จ499 - โปรดทราบข้อมูลต่อไปนี้สำหรับข้อผิดพลาด
499บางอย่าง- เวลาในการตอบกลับรวม
- URI คำขอ
- User Agent
ตัวอย่างข้อผิดพลาด 499 จากบันทึกการเข้าถึง NGINX
2019-08-23T06:50:07+00:00 rrt-03f69eb1091c4a886-c-sy 50.112.119.65:47756 10.10.53.154:8443 10.001 - - 499 - 422 0 GET /v1/products HTTP/1.1 - okhttp/3.9.1 api.acme.org rrt-03f69eb1091c4a886-c-sy-13001-6496714-1 50.112.119.65 - - - - - - - -1 - - dc-1 router-pod-1 rt-214-190301-0020137-latest-7d 36 TLSv1.2 gateway-1 dc-1 acme prod https -
สำหรับตัวอย่างนี้ เราจะเห็นข้อมูลต่อไปนี้
- เวลาในการตอบกลับรวม:
10.001วินาที สิ่งนี้หมายความว่า ไคลเอ็นต์หมดเวลาหลังจาก 10.001 วินาที - คำขอ:
GET /v1/products - โฮสต์:
api.acme.org - User Agent:
okhttp/3.9.1
- ตรวจสอบว่าเวลาในการตอบกลับทั้งหมดและ User Agent สอดคล้องกันหรือไม่
ในข้อผิดพลาดทั้ง
499รายการ
สาเหตุ: ไคลเอ็นต์ปิดการเชื่อมต่ออย่างกะทันหัน
การวินิจฉัย
- เมื่อมีการเรียก API จากแอปที่มีหน้าเดียวซึ่งทำงานในเบราว์เซอร์หรือแอปพลิเคชันบนอุปกรณ์เคลื่อนที่ เบราว์เซอร์จะล้มเลิกคำขอถ้าผู้ใช้ปลายทางปิดเบราว์เซอร์อย่างกะทันหัน ไปยังหน้าเว็บอื่นในแท็บเดียวกัน หรือหยุดการโหลดหน้าเว็บด้วยการคลิกหรือแตะ หยุดโหลด
- หากเกิดกรณีเช่นนี้ ธุรกรรมที่มีสถานะ HTTP
499มักจะแตกต่างกันไป ในเวลาในการประมวลผลคำขอ (เวลาตอบสนอง) สำหรับคำขอแต่ละรายการ -
คุณสามารถตรวจสอบว่านี่เป็นสาเหตุหรือไม่โดยการเปรียบเทียบเวลาในการตอบสนอง และตรวจสอบว่า
ข้อผิดพลาด
499แต่ละรายการแตกต่างกันเมื่อใช้การตรวจสอบ API หรือการเข้าถึง NGINX ตามที่อธิบายไว้ในขั้นตอนการวิเคราะห์ทั่วไป
ความละเอียด
- ซึ่งเป็นเรื่องปกติและมักจะไม่ใช่สาเหตุที่ต้องกังวลหากเกิดข้อผิดพลาด HTTP
499เกิดขึ้นในกลุ่มเล็กๆ เท่านั้น -
หากซึ่งมักเกิดขึ้นในเส้นทาง URL เดียวกัน อาจเป็นเพราะพร็อกซีเฉพาะ ที่เชื่อมโยงกับเส้นทางนั้นช้ามากและผู้ใช้ไม่ค่อยเต็มใจที่จะรอ
เมื่อทราบแล้วว่าพร็อกซีใดอาจได้รับผลกระทบ ให้ใช้ เวลาในการตอบสนอง หน้าแดชบอร์ดการวิเคราะห์เพื่อตรวจสอบเพิ่มเติมว่าอะไรคือสาเหตุที่ทำให้เวลาในการตอบสนองของพร็อกซี
- ในกรณีนี้ ให้ระบุพร็อกซีที่ได้รับผลกระทบโดยทำตามขั้นตอนใน ขั้นตอนการวิเคราะห์ทั่วไป
- ใช้ หน้าแดชบอร์ดการวิเคราะห์เวลาในการตอบสนองเพื่อตรวจสอบเพิ่มเติมถึงสิ่งที่ทําให้เกิดเวลาในการตอบสนองของพร็อกซี และ แก้ไขปัญหา
- หากคุณพบว่ามีเวลาในการตอบสนองที่คาดหมายไว้สำหรับพร็อกซีที่ระบุ คุณอาจได้รับ เพื่อแจ้งให้ผู้ใช้ทราบว่าพร็อกซีนี้จะใช้เวลาสักครู่ในการตอบสนอง
สาเหตุ: แอปพลิเคชันไคลเอ็นต์หมดเวลา
ซึ่งอาจเกิดขึ้นได้ในหลายสถานการณ์
-
คาดว่าคำขอจะใช้เวลาระยะหนึ่ง (สมมติว่า 10 วินาที) ในการดำเนินการ
ภายใต้สภาวะการทำงานปกติ แต่แอปพลิเคชันไคลเอ็นต์ได้รับการตั้งค่าด้วย
ค่าระยะหมดเวลา (สมมติว่า 5 วินาที) ซึ่งทำให้แอปพลิเคชันไคลเอ็นต์หมดเวลาก่อน
คำขอ API เสร็จสมบูรณ์แล้ว และนำไปสู่
499ในกรณีนี้ เราต้องตั้งฟิลด์ การหมดเวลาของไคลเอ็นต์เป็นค่าที่เหมาะสม - เซิร์ฟเวอร์เป้าหมายหรือข้อความไฮไลต์ใช้เวลานานกว่าที่คาดไว้ ในกรณีนี้ คุณจะต้องแก้ไข คอมโพเนนต์ที่เหมาะสม และปรับค่าระยะหมดเวลาอย่างเหมาะสม
- ไคลเอ็นต์ไม่ต้องการคำตอบแล้ว ดังนั้นจึงล้มเลิก กรณีนี้อาจเกิดขึ้นกับ ความถี่ API เช่น การเติมข้อความอัตโนมัติหรือการสำรวจสั้นๆ
การวินิจฉัย
การตรวจสอบ API หรือบันทึกการเข้าถึง NGINX
วินิจฉัยข้อผิดพลาดโดยใช้การตรวจสอบ API หรือบันทึกการเข้าถึง NGINX
- ตรวจสอบบันทึกการตรวจสอบ API หรือบันทึกการเข้าถึง NGINX สำหรับธุรกรรม HTTP
499ตามที่อธิบายไว้ใน ขั้นตอนการวิเคราะห์ทั่วไป - พิจารณาว่าเวลาในการตอบสนองของข้อผิดพลาด
499ทั้งหมดสอดคล้องกันหรือไม่ - หากใช่ อาจเป็นไปได้ว่าแอปพลิเคชันไคลเอ็นต์บางรายการได้กำหนดค่าระยะหมดเวลาคงที่
ในตอนท้าย หากพร็อกซีหรือเซิร์ฟเวอร์เป้าหมาย API ตอบสนองช้า ไคลเอ็นต์จะหมดเวลา
ก่อนที่พร็อกซีจะหมดเวลา ส่งผลให้มี HTTP
499sจำนวนมากสำหรับ เส้นทาง URI เดียวกัน ในกรณีนี้ ให้ระบุ User Agent จากบันทึกการเข้าถึง NGINX ซึ่ง จะช่วยคุณระบุแอปพลิเคชันไคลเอ็นต์เฉพาะ - อาจเป็นไปได้ว่ามีตัวจัดสรรภาระงานอยู่ด้านหน้า Apigee เช่น Akamai F5, AWS ELB และอื่นๆ หาก Apigee กำลังทำงานหลังตัวจัดสรรภาระงานที่กำหนดเอง คำขอ ต้องกำหนดค่าระยะหมดเวลาของตัวจัดสรรภาระงานให้มากกว่าระยะหมดเวลาของ Apigee API โดย ตามค่าเริ่มต้น เราเตอร์ Apigee จะหมดเวลาหลังจากผ่านไป 57 วินาที ดังนั้นจึงเหมาะกับการกำหนดค่าคำขอ ระยะหมดเวลา 60 วินาทีบนตัวจัดสรรภาระงาน
Trace
วินิจฉัยข้อผิดพลาดโดยใช้การติดตาม
หากยังพบปัญหาอยู่ (ยังคงมีข้อผิดพลาด 499 รายการ) ให้ดำเนินการ
ขั้นตอนต่อไปนี้
- เปิดใช้ เซสชันการติดตาม สำหรับ API ที่ได้รับผลกระทบใน Edge UI
- รอให้ข้อผิดพลาดเกิดขึ้น หรือหากคุณมีการเรียก API แล้ว ก็ให้เรียกใช้ API บางรายการ และทำให้เกิดข้อผิดพลาดซ้ำ
- ตรวจสอบเวลาที่ผ่านไปในแต่ละเฟส และจดบันทึกระยะที่เวลาใช้มากที่สุด ไป
- หากคุณสังเกตเห็นข้อผิดพลาดเกี่ยวกับเวลาที่ผ่านไปนานที่สุดทันทีหลังจาก
ดังต่อไปนี้ แสดงว่าเซิร์ฟเวอร์แบ็กเอนด์ทำงานช้าหรือใช้เวลานาน
เพื่อดำเนินการตามคำขอ
- ส่งคำขอไปยังเซิร์ฟเวอร์เป้าหมายแล้ว
- นโยบายคำขอราคาเสนอบริการ
ต่อไปนี้คือตัวอย่างการติดตาม UI ที่แสดงระยะหมดเวลาของเกตเวย์หลังจากที่คำขอ ที่ส่งไปยังเซิร์ฟเวอร์เป้าหมาย:
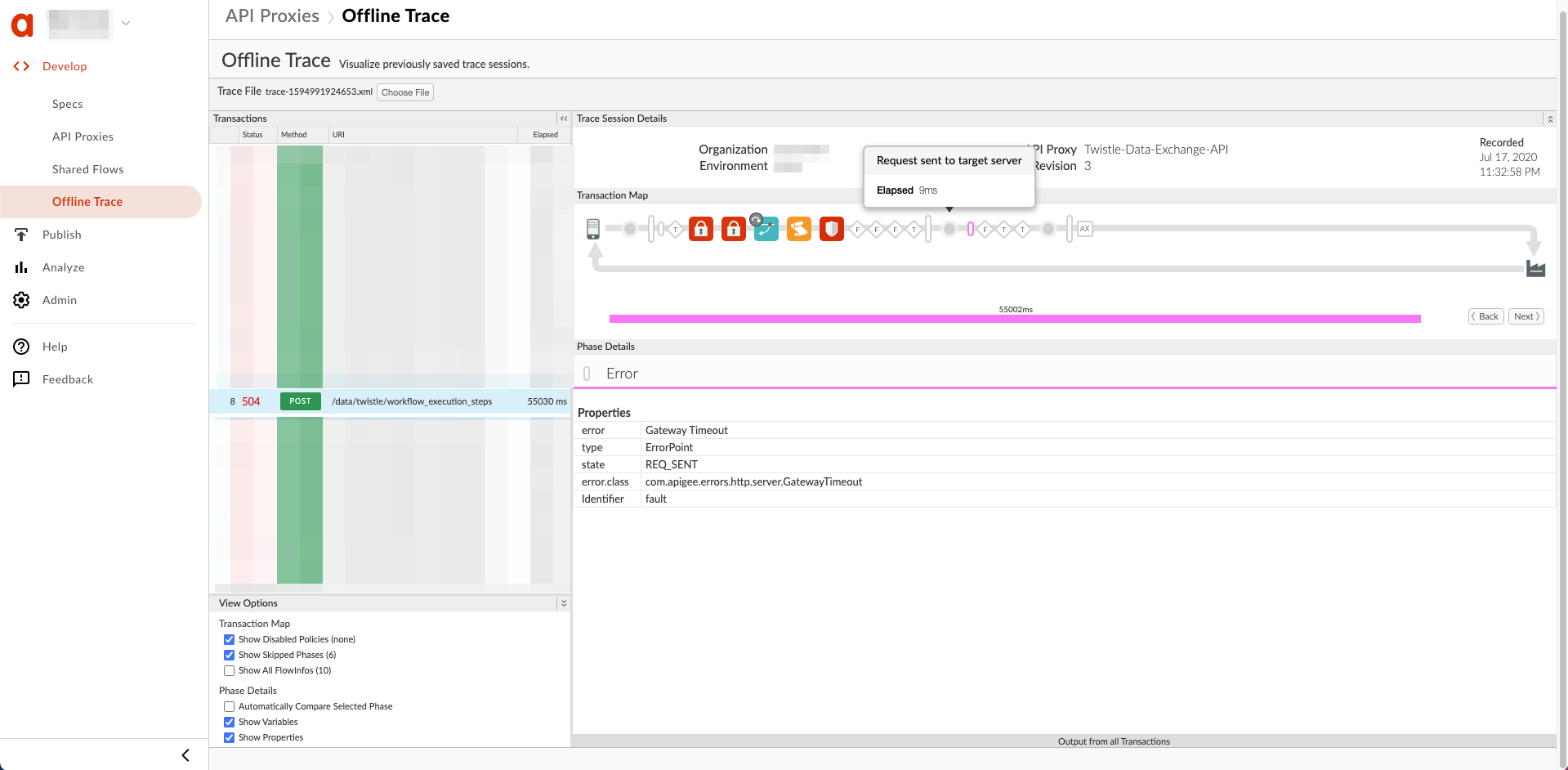
ความละเอียด
- โปรดดู แนวทางปฏิบัติแนะนำสำหรับการกำหนดค่าระยะหมดเวลาของ I/O เพื่อทำความเข้าใจว่าควรกำหนดค่าระยะหมดเวลาใด ของคอมโพเนนต์ต่างๆ ที่เกี่ยวข้องในขั้นตอนคําขอ API ผ่าน Apigee Edge
- ตรวจสอบว่าได้ตั้งค่าระยะหมดเวลาที่เหมาะสมในแอปพลิเคชันไคลเอ็นต์ตาม แนวทางปฏิบัติที่ดีที่สุด
หากยังพบปัญหาอยู่ ให้ไปที่ต้องรวบรวมข้อมูลการวินิจฉัย
ต้องรวบรวมข้อมูลการวินิจฉัย
หากปัญหายังคงอยู่ ให้รวบรวมข้อมูลการวินิจฉัยต่อไปนี้แล้วติดต่อทีมสนับสนุนของ Apigee Edge
หากคุณเป็นผู้ใช้ระบบคลาวด์สาธารณะ โปรดระบุข้อมูลต่อไปนี้
- ชื่อองค์กร
- ชื่อสภาพแวดล้อม
- ชื่อพร็อกซี API
- ทำตามคำสั่ง
curlในการสร้างข้อผิดพลาดการหมดเวลาซ้ำ - ไฟล์การติดตามสำหรับคำขอ API ที่คุณเห็นข้อผิดพลาดการหมดเวลาของไคลเอ็นต์
หากคุณเป็นผู้ใช้ Private Cloud ให้ระบุข้อมูลต่อไปนี้
- พบข้อความแสดงข้อผิดพลาดทั้งหมดสำหรับคำขอที่ล้มเหลว
- ชื่อสภาพแวดล้อม
- แพ็กเกจพร็อกซี API
- ไฟล์การติดตามสำหรับคำขอ API ที่คุณเห็นข้อผิดพลาดการหมดเวลาของไคลเอ็นต์
- บันทึกการเข้าถึง NGINX (
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - บันทึกของระบบประมวลผลข้อความ (
/opt/apigee/var/log/edge-message-processor/logs/system.log)