
<ph type="x-smartling-placeholder"></ph>
您正在查看 Apigee Edge 文档。
转到
Apigee X 文档。 信息
问题
客户端应用收到 API 请求的超时错误,或请求被终止 当 API 请求仍在 Apigee 上执行时突然生效。
您会在 API 监控中看到此类 API 请求的状态代码 499;并且
NGINX 访问日志。有时,您会在 API Analytics 中看到不同的状态代码
显示消息处理器返回的状态代码。
错误消息
客户端应用可能会出现如下错误:
curl: (28) Operation timed out after 6001 milliseconds with 0 out of -1 bytes received
哪些原因会导致客户端超时?
Edge 平台上的 API 请求的典型路径是 客户 >路由器 >消息处理器 >后端服务器,如下图所示:
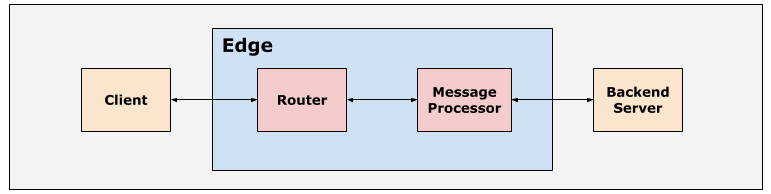
Apigee Edge 平台中的路由器和消息处理器通过合适的 默认的超时值,以确保 API 请求不会花费太长时间完成。
客户端超时
您可以根据需要为客户端应用配置合适的超时值。
网络浏览器和移动应用等客户端设有由操作系统定义的超时。
路由器超时
路由器上配置的默认超时时间为 57 秒。这是指 API 代理从在 Edge 上收到 API 请求开始执行,直到收到响应 包括后端响应和执行的所有政策。默认 可以覆盖路由器和虚拟主机上的超时值, <ph type="x-smartling-placeholder"></ph> 在路由器上配置 I/O 超时。
消息处理器超时
消息处理器上配置的默认超时时间为 55 秒。这是 后端服务器处理请求并响应消息所花费的时间 处理方。可以在消息处理器或 API 内替换默认超时 代理(如 <ph type="x-smartling-placeholder"></ph> 配置消息处理器的 I/O 超时。
如果客户端在 API 代理超时之前关闭了与路由器的连接,则
会观察特定 API 请求的超时错误。对于此类请求,系统会在路由器中记录状态代码 499 Client
Closed Connection,这可以在 API 中观察
Monitoring 和 NGINX 访问日志。
可能的原因
在 Edge 中,499 Client Closed Connection 错误的常见原因如下:
| 原因 | 说明 | 适用的问题排查说明 |
|---|---|---|
| 客户端突然关闭了连接 | 当客户端因最终用户取消会话而关闭连接时, 然后再完成请求 | 公有云和私有云用户 |
| 客户端应用超时 | 如果客户端应用在 API 代理还没来得及 处理并发送响应。这通常发生在客户端超时时长较短时 超过路由器超时限制。 | 公有云和私有云用户 |
常见诊断步骤
使用以下工具/技术之一来诊断此错误:
- API 监控
- NGINX 访问日志
API 监控
<ph type="x-smartling-placeholder">如需使用 API Monitoring 诊断错误,请执行以下操作:
- 导航至分析 >API 监控 >调查页面。
- 过滤出
4xx个错误,然后选择时间范围。 - 对照时间绘制状态代码。
- 选择一个包含
499个错误的单元格,如下所示: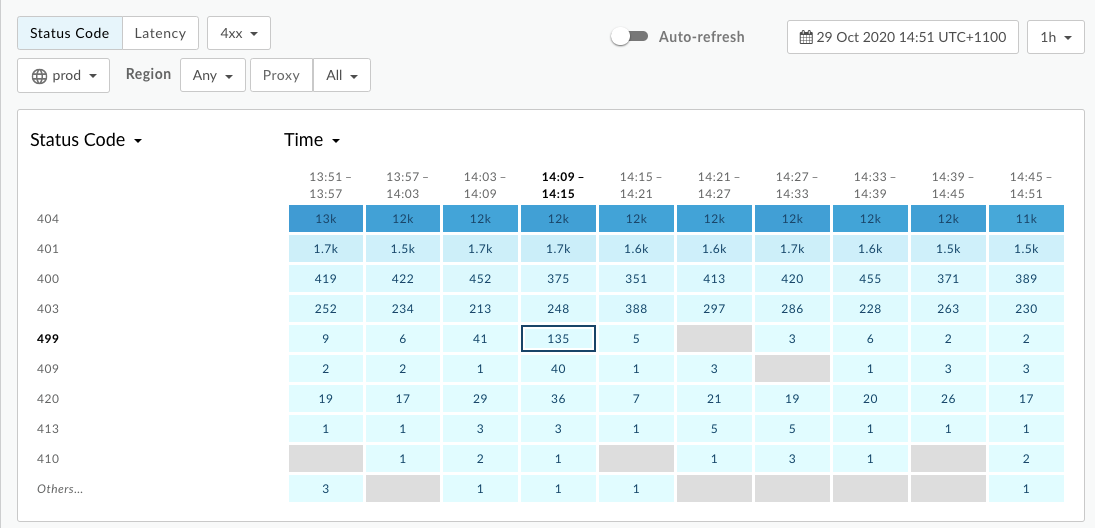
- 您会在右侧窗格中看到
499错误的相关信息,如下所示: 如下所示: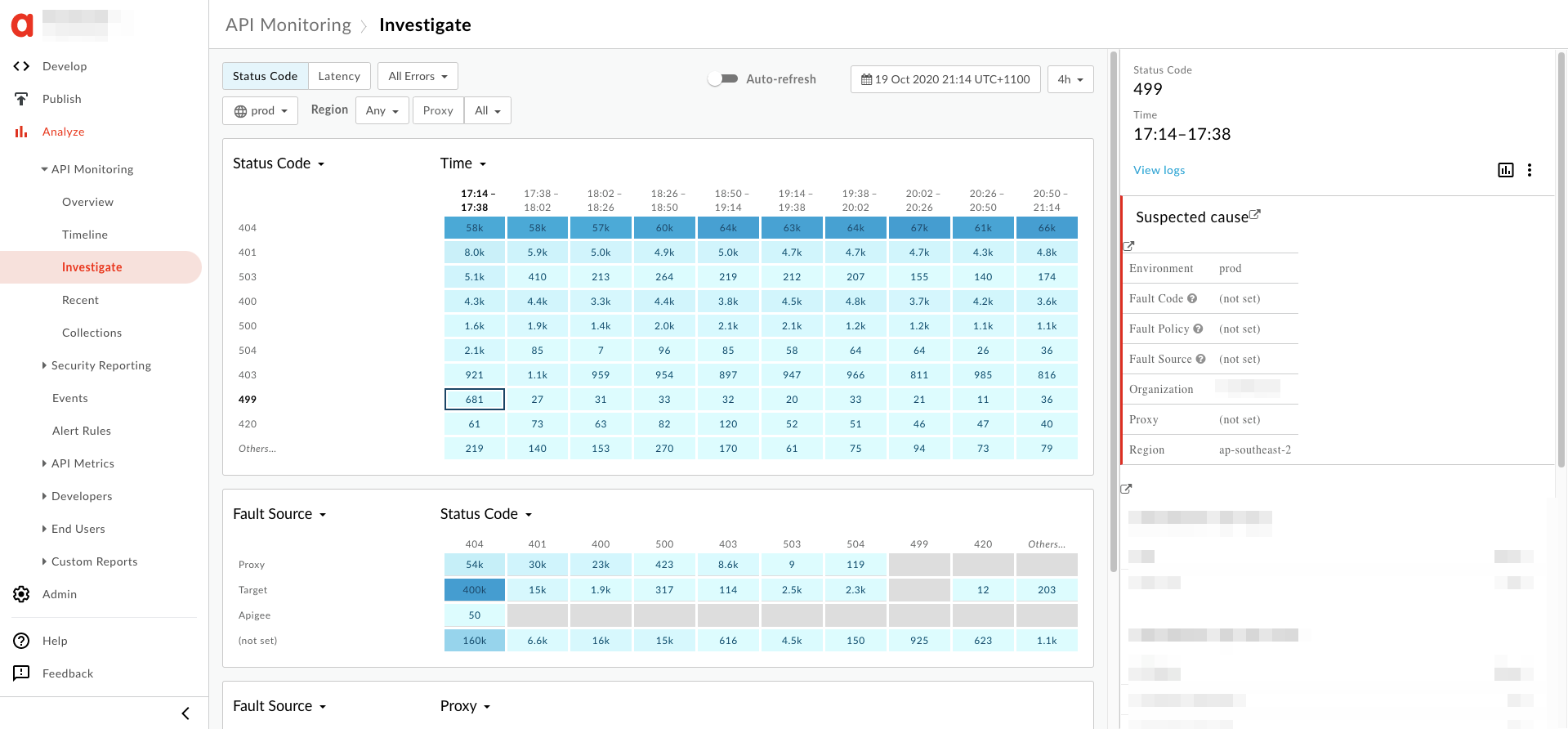
- 在右侧窗格中,点击查看日志。
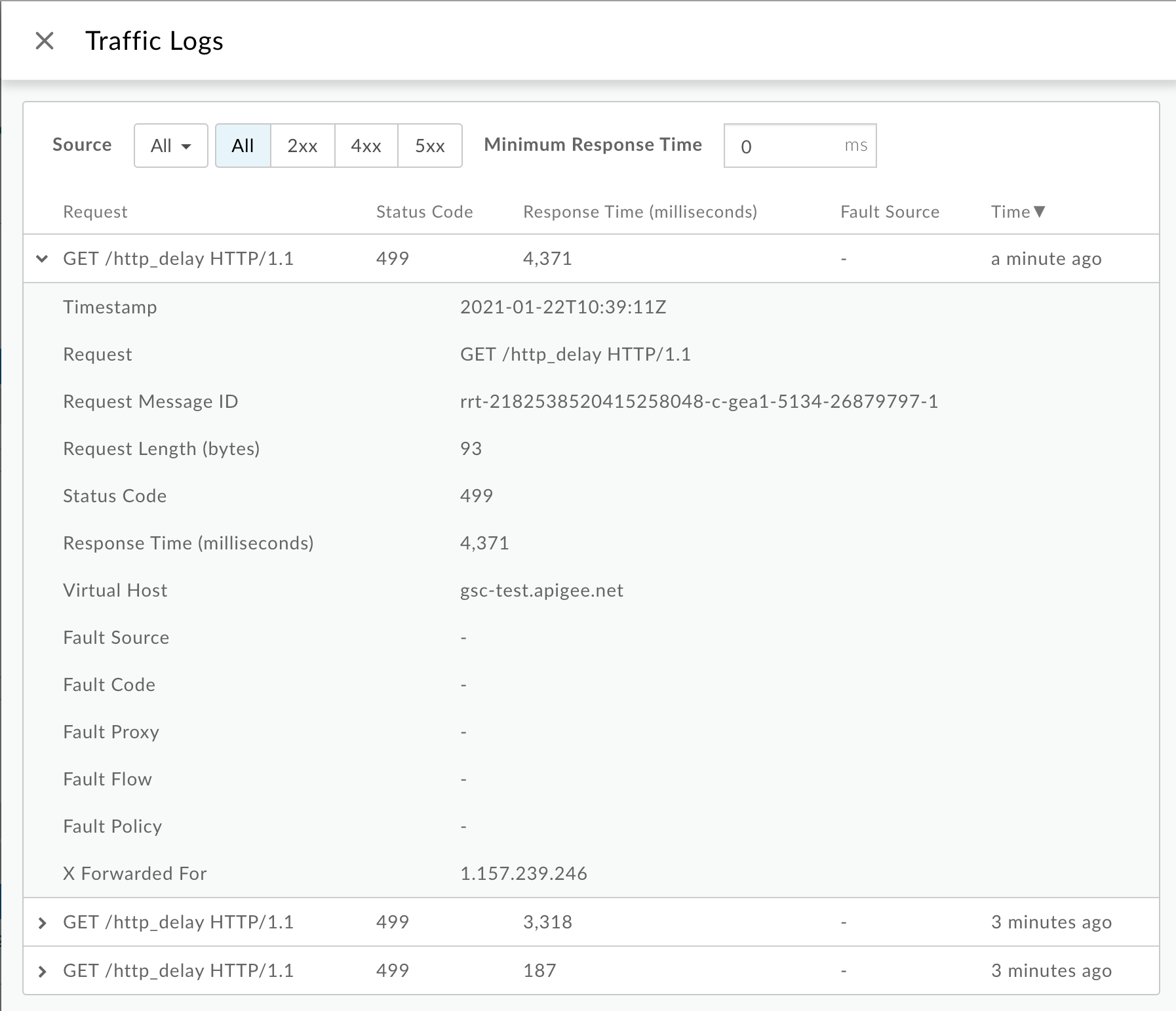
在流量日志窗口中,请注意部分
499的以下详细信息 错误:- Request:提供用于进行调用的请求方法和 URI
- 响应 时间:提供请求所用的总时间。
您还可以使用 API Monitoring GET logs API。对于 例如,通过查询
org、env的日志,timeRange和status,您可以下载 记录客户端超时事务的日志。由于 API Monitoring 将 HTTP
499的代理设置为-您可以使用 API (Logs API) 以获取 关联代理。例如:
curl "https://apimonitoring.enterprise.apigee.com/logs/apiproxies?org=ORG&env=ENV&select=https://VIRTUAL_HOST/BASEBATH" -H "Authorization: Bearer $TOKEN"
- 查看响应时间中是否存在其他
499错误,并检查是否 在测试期间,499个错误。
NGINX 访问日志
<ph type="x-smartling-placeholder">如需使用 NGINX 访问日志诊断错误,请执行以下操作:
- 如果您是 Private Cloud 用户,可使用 NGINX 访问日志来确定
有关 HTTP
499错误的关键信息。 - 查看 NGINX 访问日志:
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - 搜索以查看在特定时间段内是否存在任何
499错误 (如果问题在过去发生过)或者是否还有任何请求仍失败,499。 - 对于部分
499错误,请注意以下信息: <ph type="x-smartling-placeholder">- </ph>
- 总响应时间
- 请求 URI
- 用户代理
NGINX 访问日志中的 499 错误示例:
2019-08-23T06:50:07+00:00 rrt-03f69eb1091c4a886-c-sy 50.112.119.65:47756 10.10.53.154:8443 10.001 - - 499 - 422 0 GET /v1/products HTTP/1.1 - okhttp/3.9.1 api.acme.org rrt-03f69eb1091c4a886-c-sy-13001-6496714-1 50.112.119.65 - - - - - - - -1 - - dc-1 router-pod-1 rt-214-190301-0020137-latest-7d 36 TLSv1.2 gateway-1 dc-1 acme prod https -
对于此示例,我们可以看到以下信息:
- 总响应时间:
10.001秒。这表示 客户端在 10.001 秒后超时 - 请求:
GET /v1/products - 主机:
api.acme.org - 用户代理:
okhttp/3.9.1
- 检查总响应时间和用户代理是否一致
全部
499错误。
原因:客户端突然关闭了连接
诊断
- 从浏览器或移动应用中运行的单页应用调用 API 时, 如果最终用户突然关闭浏览器, 链接到同一标签页中的另一个网页,或通过点击或点按 停止加载。
- 如果发生这种情况,具有 HTTP
499状态的事务通常可能会有所不同 。 -
您可以通过比较响应时间并验证是否是导致这种情况的原因
使用 API Monitoring 或 NGINX Access 对每个
499错误执行的操作是不同的 如常见诊断步骤中所述。
分辨率
- 这是正常现象,如果发生 HTTP
499错误,通常无需担心。 但数量较少 -
如果同一网址路径上经常出现此错误,可能是因为特定代理 速度很慢,用户不愿等待。
知道哪个代理可能会受到影响后,请使用 延迟时间 分析信息中心,以进一步调查导致代理延迟的原因。
- 在这种情况下,请按照下列步骤确定受影响的代理: 常见的诊断步骤。
- 使用 延迟时间分析信息中心,进一步调查导致代理延迟时间的原因并 解决问题。
- 如果您发现特定代理的延迟时间符合预期, 以告知用户此代理将需要一些时间作出响应。
原因:客户端应用超时
这种情况可能发生在多种情况下。
-
该请求预计需要一段时间(比如 10 秒)才能完成
在正常操作条件下使用。但是,为客户端应用设置的值不正确
超时值(假设为 5 秒),这会导致客户端应用在
API 请求已完成,转到
499。在本示例中,我们需要设置 设置为适当的值。 - 目标服务器或调用程序所用的时间超出预期。在这种情况下,您需要修复 相应组件,并相应地调整超时值。
- 客户端不再需要响应,因此已中止。发生这类情况 频率 API,例如自动完成或短轮询。
诊断
API Monitoring 或 NGINX 访问日志
使用 API Monitoring 或 NGINX 访问日志诊断错误:
- 查看 API 监控日志或 NGINX 访问日志中是否存在 HTTP
499事务,具体如 常见的诊断步骤。 - 确定所有
499错误的响应时间是否一致。 - 如果是,则可能是因为某个特定客户端应用配置了固定的超时
。如果 API 代理或目标服务器响应缓慢,客户端就会超时
导致出现大量 HTTP
499s。 相同的 URI 路径。在这种情况下,请从 NGINX 访问日志中确定用户代理, 可帮助您确定具体的客户端应用。 - Apigee 前端也可能设有负载平衡器,例如 Akamai, F5、AWS ELB 等。如果 Apigee 在自定义负载平衡器的后面运行,则请求 负载平衡器的超时值必须配置为超过 Apigee API 超时值。修改者 默认情况下,Apigee Router 会在 57 秒后超时,因此适合配置请求 设置为 60 秒
Trace
使用 Trace 诊断错误
如果问题仍未解决(仍然出现 499 个错误),请执行
操作步骤:
- 启用 跟踪会话 。
- 请等待错误发生,或者如果您已进行 API 调用,则进行一些 API 调用 并重现错误。
- 检查每个阶段所用的时间,并记下使用时间最多的阶段 。
- 如果您发现最长耗时的错误,
则表示后端服务器运行缓慢或用时很长
处理请求:
<ph type="x-smartling-placeholder">
- </ph>
- 请求已发送到目标服务器
- ServiceCallout 政策
下面是一个示例界面跟踪记录,显示了 Request 被触发后出现 Gateway Timeout 发送到目标服务器:
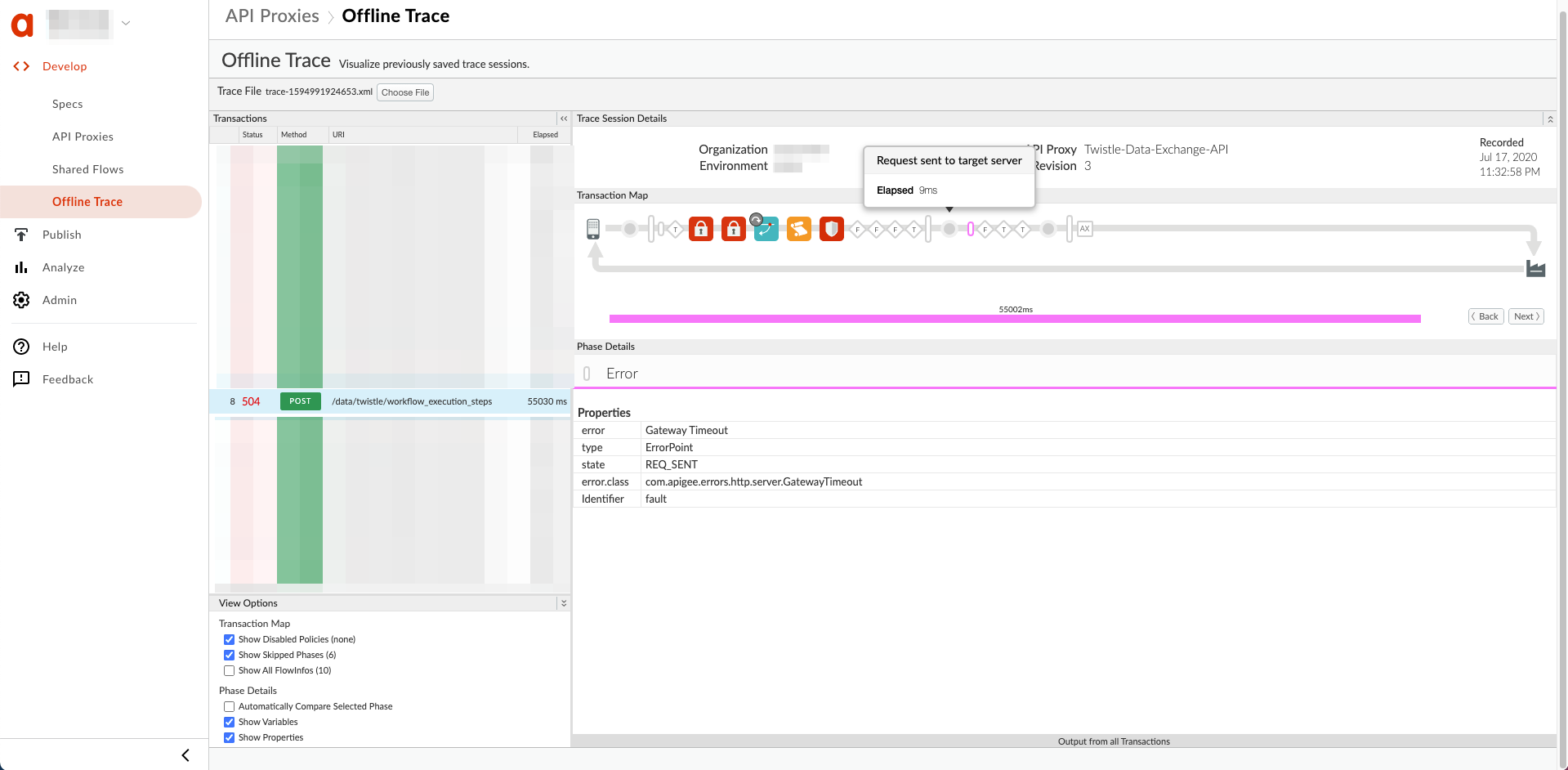
分辨率
- 请参阅 配置 I/O 超时的最佳做法,以了解应该设置什么超时值 。
- 请确保您根据 最佳做法
如果问题仍然存在,请参阅必须收集诊断信息。
必须收集的诊断信息
如果问题仍然存在,请收集以下诊断信息,然后联系 Apigee Edge 支持团队。
如果您是公有云用户,请提供以下信息:
- 组织名称
- 环境名称
- API 代理名称
- 完成用于重现超时错误的
curl命令 - 您看到客户端超时错误的 API 请求的跟踪文件
如果您是 Private Cloud 用户,请提供以下信息:
- 观察到失败请求的完整错误消息
- 环境名称
- API 代理软件包
- 您看到客户端超时错误的 API 请求的跟踪文件
- NGINX 访问日志 (
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - 消息处理器系统日志 (
/opt/apigee/var/log/edge-message-processor/logs/system.log)