
<ph type="x-smartling-placeholder"></ph>
您正在查看 Apigee Edge 文档。
转到
Apigee X 文档。 信息
问题
客户端应用将获取 HTTP 响应状态 503 以及消息
在 API 代理调用后返回 Service Unavailable。
错误消息
客户端应用将获得以下响应代码:
HTTP/1.1 503 Service Unavailable
此外,您可能还会看到以下错误消息:
{
"fault": {
"faultstring": "The Service is temporarily unavailable",
"detail": {
"errorcode": "messaging.adaptors.http.flow.ServiceUnavailable"
}
}
}可能的原因
| 原因 | 说明 | 适用的问题排查说明 |
|---|---|---|
| 目标服务器过早关闭连接 | 目标服务器提前终止连接,而消息处理器仍处于 发送请求载荷。 | Edge 公有云和私有云用户 |
常见诊断步骤
确定失败请求的消息 ID
跟踪工具
要使用跟踪工具确定失败请求的消息 ID,请执行以下操作:
- 如果问题仍未解决,请启用 跟踪会话。
- 进行 API 调用并重现问题 -
503 Service Unavailable错误代码为messaging.adaptors.http.flow.ServiceUnavailable. - 选择其中一个失败的请求。
- 前往 AX 阶段,并确定消息 ID
(
X-Apigee.Message-ID) 阶段详情部分,如下图所示。
NGINX 访问日志
如需使用 NGINX 访问日志确定失败请求的消息 ID,请执行以下操作:
您还可以参考 NGINX 访问日志来确定 503 错误的消息 ID。
如果问题在过去发生过或问题是间歇性的,那么该方法会特别有用
并且您无法在界面中捕获跟踪记录。请按照以下步骤从 NGINX 访问日志中确定此信息:
- 查看 NGINX 访问日志:(
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - 搜索以查看特定 API 代理在特定时间段内是否存在任何
503错误 (如果问题在过去发生过)或者是否有任何请求仍因503而失败。 - 如果 X-Apigee-fault-codemessaging.adaptors.http.flow.ServiceUnavailable 出现任何
503错误, 记下一个或多个此类请求的消息 ID,如以下示例所示:显示
503错误的示例条目
原因:目标服务器过早关闭连接
诊断
- 如果您是公有云或私有云用户:
<ph type="x-smartling-placeholder">
- </ph>
- 使用 Trace 工具(如常见诊断步骤中所述)
并验证您在 Google Analytics 数据记录窗格中是否设置了以下两项:
- X-Apigee.fault-code:
messaging.adaptors.http.flow.ServiceUnavailable - X-Apigee.fault-source:
target
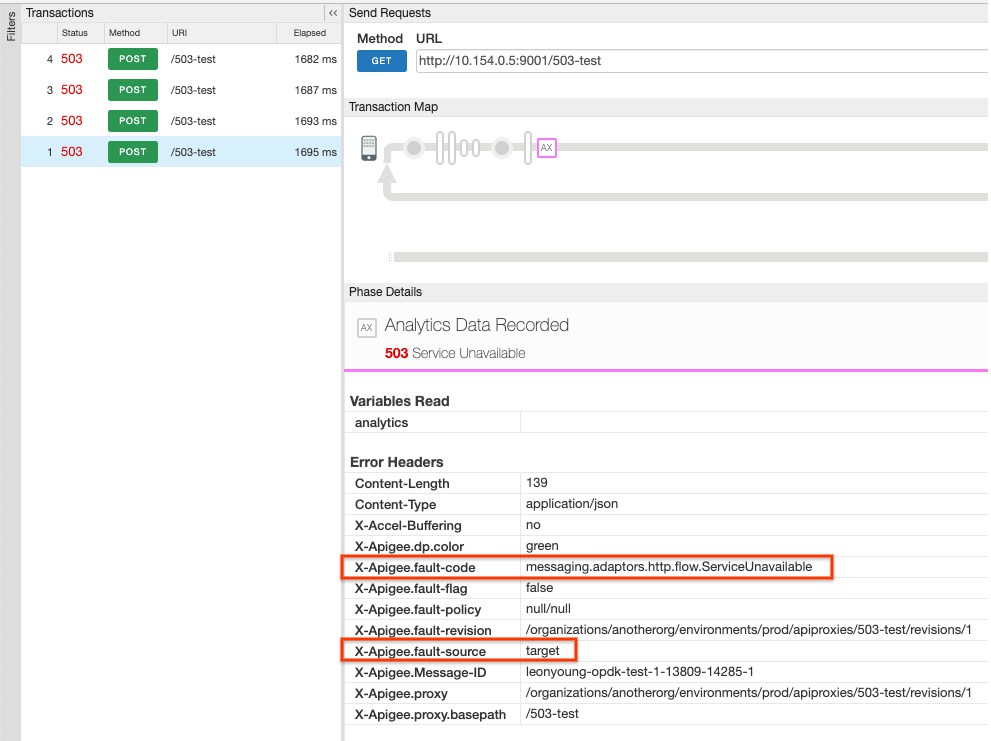
- X-Apigee.fault-code:
- 使用 Trace 工具(如常见诊断步骤中所述)
并确认在错误窗格中立即设置了以下两项
TARGET_REQ_FLOWstate 属性:- error.class::
com.apigee.errors.http.server.ServiceUnavailableException - error.cause::
Broken pipe
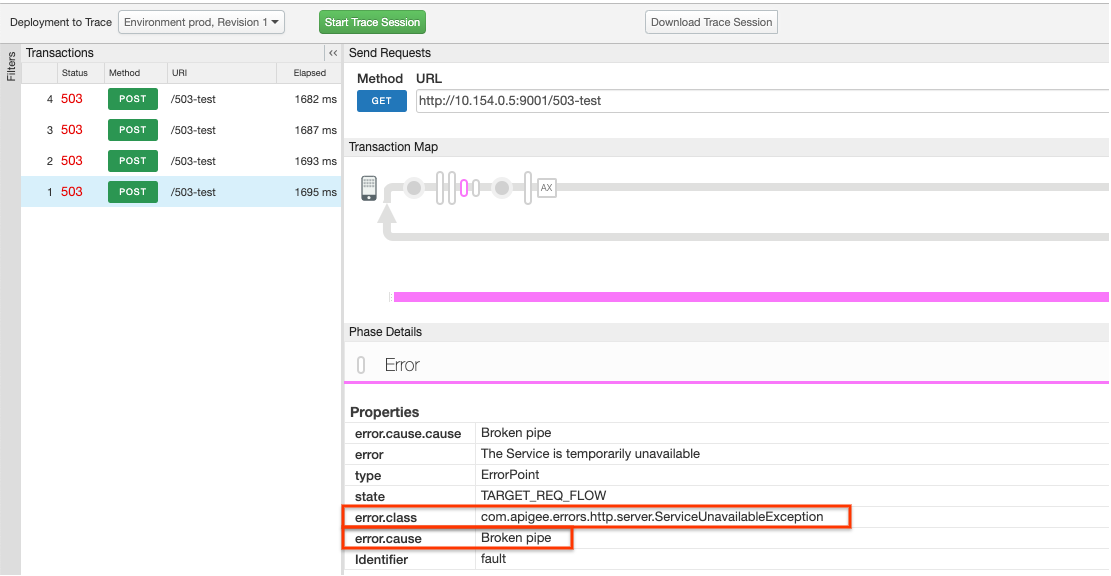
- error.class::
- 请参阅使用 tcpdump 以展开进一步调查。
- 使用 Trace 工具(如常见诊断步骤中所述)
并验证您在 Google Analytics 数据记录窗格中是否设置了以下两项:
- 如果您是 Private Cloud 用户:
<ph type="x-smartling-placeholder">
- </ph>
- <ph type="x-smartling-placeholder"></ph> 确定失败请求的消息 ID。
- 在消息处理器日志中搜索消息 ID
(
/opt/apigee/var/log/edge-message-processor/logs/system.log)。 - 您会看到以下例外情况之一:
异常 1:java.io.IOException:写入通道 ClientOutputChannel 时发生管道损坏
2021-01-30 15:31:14,693 org:anotherorg env:prod api:myproxy rev:1 messageid:myorg-opdk-test-1-30312-13747-1 NIOThread@1 INFO HTTP.SERVICE - ExceptionHandler.handleException() : Exception java.io.IOException: Broken pipe occurred while writing to channel ClientOutputChannel(ClientChannel[Connected: Remote:IP:PORT Local:0.0.0.0:42828]@8380 useCount=1 bytesRead=0 bytesWritten=76295 age=2012ms lastIO=2ms isOpen=false)
或
异常 #2:onExceptionWrite 异常 {}
java.io.IOException:管道损坏2021-01-31 15:29:37,438 org:anotherorg env:prod api:503-test rev:1 messageid:leonyoung-opdk-test-1-18604-13978-1 NIOThread@0 ERROR HTTP.CLIENT - HTTPClient$Context$2.onException() : ClientChannel[Connected: Remote:IP:PORT Local:0.0.0.0:57880]@8569 useCount=1 bytesRead=0 bytesWritten=76295 age=3180ms lastIO=2 ms isOpen=false.onExceptionWrite exception: {} java.io.IOException: Broken pipe
- 这两个异常都表明,虽然消息处理器仍在写入
请求有效负载,则连接会提前
后端服务器因此,消息处理器会抛出异常
java.io.IOException: Broken pipe。 Remote:IP:PORT表示已解析的后端服务器 IP 地址和端口号。- 上述错误消息中的属性
bytesWritten=76295表示 消息处理器已将76295字节的载荷发送到后端 服务器。 bytesRead=0属性表示消息处理器 从后端服务器收到任何数据(响应)。- 如需进一步调查此问题,请在后端收集
tcpdump并对其进行分析(如下所述)。
使用 tcpdump
-
使用以下命令在后端服务器或消息处理器上捕获
tcpdump: 以下命令:用于在后端服务器上收集
tcpdump的命令:tcpdump -i any -s 0 host MP_IP_ADDRESS -w FILE_NAME
用于在消息处理器上收集
tcpdump的命令:tcpdump -i any -s 0 host BACKEND_HOSTNAME -w FILE_NAME
- 分析捕获的
tcpdump:tcpdump 输出结果示例(收集在消息处理器上):

在上面的
tcpdump中,您可以看到以下内容:- 在数据包
4中,消息处理器将POST请求发送到 后端服务器 - 数据包
5、8、9、10、11,消息处理器会继续将请求载荷发送到 后端服务器 - 在数据包
6和7中,后端服务器以 对于从消息处理器接收的请求载荷的一部分,返回ACK。 - 但是,在数据包
12中,不要使用ACK进行响应 然后针对已接收的应用数据包进行响应 则后端服务器会改为响应FIN ACK,以启动 以及关闭连接。 - 这清楚地表明后端服务器正在过早关闭连接 当消息处理器仍在发送请求载荷时。
- 这会使消息处理器记录
IOException: Broken Pipe错误并向客户端返回503
- 在数据包
分辨率
- 与您的应用团队和网络团队中的任一团队合作,分析并解决 以及后端服务器端过早断开连接的问题
- 确保后端服务器应用不会超时或重置连接 然后才能接收整个请求载荷
- 如果在 Apigee 与后端服务器之间有任何中间网络设备或层, 则请确保在收到整个请求载荷之前,请求不会超时。
如果问题仍然存在,请转到必须收集诊断信息。
必须收集的诊断信息
按照上述说明操作后,如果问题依然存在,请收集以下内容 然后联系 Apigee Edge 支持团队:
如果您是公有云用户,请提供以下信息:
- 组织名称
- 环境名称
- API 代理名称
- 完成
curl命令以重现503错误 - 包含具有
503 Service Unavailable错误的请求的跟踪文件 - 如果
503错误目前未发生,请提供包含 过去发生503个错误时的时区信息。
如果您是 Private Cloud 用户,请提供以下信息:
- 观察到失败请求的完整错误消息
- 您要观察的组织、环境名称和 API 代理名称
503个错误 - API 代理软件包
- 包含具有
503 Service Unavailable错误的请求的跟踪文件 - NGINX 访问日志
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - 消息处理器日志
/opt/apigee/var/log/edge-message-processor/logs/system.log - 发生
503错误时包含时区信息的时间段 Tcpdumps将在发生以下情况时收集: 发生错误