
Apigee Edge का दस्तावेज़ देखा जा रहा है.
Apigee X के दस्तावेज़ पर जाएं. जानकारी
Edge API Analytics, Apigee Edge की एक बेहतरीन सुविधा है. यह एपीआई के ज़रिए मिलने वाले डेटा को इकट्ठा करता है और उसका विश्लेषण करता है. कैप्चर किए गए आंकड़ों के डेटा से, बहुत काम की अहम जानकारी मिल सकती है. उदाहरण के लिए, समय के साथ एपीआई ट्रैफ़िक की संख्या में क्या बदलाव हो रहा है? सबसे ज़्यादा इस्तेमाल किया जाने वाला एपीआई कौनसा है? किन एपीआई में गड़बड़ी की दर ज़्यादा है?
इस डेटा और अहम जानकारी का नियमित तौर पर विश्लेषण करके, सही कार्रवाइयां की जा सकती हैं. जैसे, मौजूदा इस्तेमाल, कारोबार, और आने वाले समय में निवेश से जुड़े फ़ैसलों के आधार पर, एपीआई की क्षमता से जुड़ी प्लानिंग करना वगैरह.
Analytics डेटा और उसका स्टोरेज
एपीआई Analytics कई तरह का डेटा कैप्चर करता है, जैसे:
- किसी एपीआई के बारे में जानकारी - अनुरोध यूआरआई, क्लाइंट आईपी पता, रिस्पॉन्स स्टेटस कोड वगैरह
- एपीआई प्रॉक्सी की परफ़ॉर्मेंस - सफल/असफल होने की दर, अनुरोध और रिस्पॉन्स प्रोसेस करने में लगने वाला समय वगैरह
- टारगेट सर्वर की परफ़ॉर्मेंस - सफलता/असफलता दर, प्रोसेसिंग में लगने वाला समय
- गड़बड़ी की जानकारी - गड़बड़ियों की संख्या, गड़बड़ी का कोड, गड़बड़ी की नीति, Apigee और टारगेट के सर्वर की वजह से हुई गड़बड़ियों की संख्या.
- अन्य जानकारी - डेवलपर, डेवलपर ऐप्लिकेशन वगैरह से मिले अनुरोधों की संख्या
यह सारा डेटा, Apigee Edge के Postgres डेटाबेस में बनाए गए और मैनेज किए गए analytics स्कीमा में सेव होता है.
आम तौर पर, किसी सामान्य Edge इंस्टॉलेशन में, Postgres में ये स्कीमा होंगे:
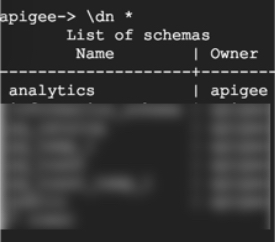
Edge, analytics नाम के स्कीमा का इस्तेमाल हर संगठन और एनवायरमेंट के लिए, सभी आंकड़ों का डेटा स्टोर करने के लिए करता है. अगर कमाई करने की सुविधा इंस्टॉल है, तो rkms
स्कीमा दिखेगा. अन्य स्कीमा, Postgres के इंटरनल के लिए हैं.
analytics स्कीमा में बदलाव होते रहेंगे, क्योंकि Apigee Edge रनटाइम के दौरान इसमें नई फ़ैक्ट टेबल को डाइनैमिक तौर पर जोड़ेगा. Postgres सर्वर कॉम्पोनेंट, फ़ैक्ट डेटा को एग्रीगेट टेबल में एग्रीगेट करेगा. ये टेबल, Edge यूज़र इंटरफ़ेस (यूआई) पर लोड और दिखाई जाती हैं.
एंटीपैटर्न
निजी क्लाउड एनवायरमेंट में, सीधे SQL क्वेरी का इस्तेमाल करके, Postgres डेटाबेस में Apigee के मालिकाना हक वाले किसी भी स्कीमा में कस्टम कॉलम, टेबल, और/या व्यू जोड़ने का सुझाव नहीं दिया जाता. ऐसा करने से, स्कीमा पर बुरा असर पड़ सकता है.
आइए, इस बारे में ज़्यादा जानकारी देने के लिए एक उदाहरण लेते हैं.
मान लें कि account नाम की कस्टम टेबल, नीचे दी गई टेबल के तौर पर, आंकड़ों के स्कीमा के तहत बनाई गई है:
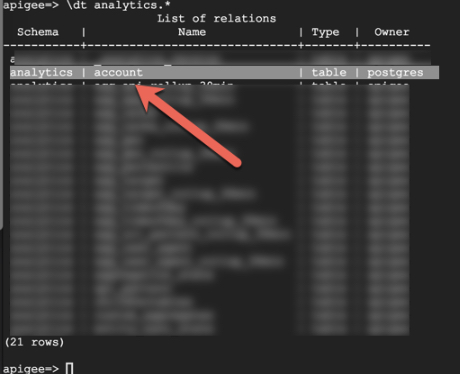
मान लें कि कुछ समय बाद, Apigee Edge को पुराने वर्शन से नए वर्शन पर अपग्रेड करना है. Private Cloud Apigee Edge को अपग्रेड करने के लिए, कई अन्य कॉम्पोनेंट के साथ-साथ Postgres को भी अपग्रेड करना पड़ता है. अगर Postgres डेटाबेस में कोई कस्टम कॉलम, टेबल या व्यू जोड़ा गया है, तो Postgres को अपग्रेड नहीं किया जा सकता. ऐसा, कस्टम ऑब्जेक्ट के रेफ़रंस वाली गड़बड़ियों की वजह से होता है, क्योंकि इन्हें Apigee Edge ने नहीं बनाया है. इसलिए, Apigee Edge का अपग्रेड भी पूरा नहीं हो पाता.
इसी तरह, Apigee Edge के रखरखाव से जुड़ी गतिविधियों के दौरान भी गड़बड़ियां हो सकती हैं. इन गतिविधियों में, Postgres डेटाबेस के साथ-साथ Edge के कॉम्पोनेंट का बैकअप लेना और उन्हें वापस लाना शामिल है.
असर
- Apigee Edge को अपग्रेड नहीं किया जा सकता, क्योंकि Postgres कॉम्पोनेंट अपग्रेड नहीं हो पा रहा है. ऐसा, Apigee Edge से बनाए गए कस्टम ऑब्जेक्ट के रेफ़रंस वाली गड़बड़ियों की वजह से हो रहा है.
- Apigee Analytics की सेवा के रखरखाव (बैकअप/बहाल करना) के दौरान, गड़बड़ियां और काम न करना.
सबसे सही तरीका
- कॉलम, टेबल, व्यू, फ़ंक्शन, और प्रोसेस के तौर पर कोई भी कस्टम जानकारी, सीधे तौर पर Apigee के मालिकाना हक वाले किसी भी स्कीमा में न जोड़ें. जैसे,
analyticsवगैरह - अगर आपको पसंद के मुताबिक जानकारी जोड़नी है, तो
analyticsस्कीमा में आंकड़ों को इकट्ठा करने की नीति का इस्तेमाल करके, उसे कॉलम (फ़ील्ड) के तौर पर जोड़ा जा सकता है.