
<ph type="x-smartling-placeholder"></ph>
Vous consultez la documentation Apigee Edge.
Accédez à la page
Documentation sur Apigee X. En savoir plus
Symptôme
L'application cliente reçoit une erreur de délai d'inactivité pour les requêtes API, ou la requête est interrompue. alors que la requête API est toujours en cours d'exécution sur Apigee.
Vous allez observer le code d'état 499 pour ces requêtes API dans API Monitoring et
Journaux d'accès NGINX Parfois, vous verrez des codes d'état
différents dans API Analytics car il
affiche le code d'état renvoyé par le processeur de messages.
Message d'erreur
Les applications clientes peuvent générer des erreurs de ce type:
curl: (28) Operation timed out after 6001 milliseconds with 0 out of -1 bytes received
Quelles sont les causes des délais d'inactivité du client ?
Le chemin typique pour une requête API sur la plate-forme Edge est Client > Routeur > Processeur de messages > Serveur backend, comme illustré dans la figure suivante:
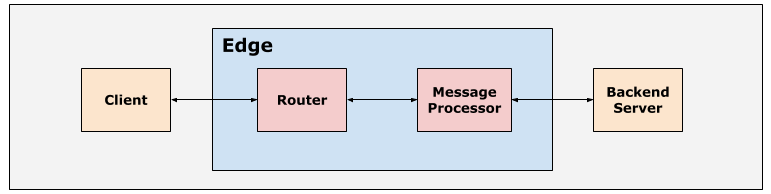
Les routeurs et processeurs de messages de la plate-forme Apigee Edge sont configurés avec des valeurs de délai avant expiration par défaut afin de garantir que les requêtes API ne prennent pas trop de temps.
Expiration du délai sur le client
Les applications clientes peuvent être configurées avec une valeur de délai d'expiration adaptée à vos besoins.
Les clients tels que les navigateurs Web et les applications mobiles ont des délais avant expiration définis par le système d'exploitation.
Délai d'inactivité sur le routeur
Le délai avant expiration par défaut configuré sur les routeurs est de 57 secondes. Il s'agit de la durée maximale pendant laquelle Le proxy d'API peut s'exécuter à partir du moment où la demande API est reçue sur Edge jusqu'à ce que la réponse soit y compris la réponse du backend et toutes les stratégies exécutées. La valeur par défaut le délai avant expiration peut être ignoré sur les routeurs et les hôtes virtuels, comme expliqué dans <ph type="x-smartling-placeholder"></ph> Configurer le délai avant expiration des E/S sur les routeurs
Délai d'inactivité sur les processeurs de messages
Le délai avant expiration par défaut configuré sur les processeurs de messages est de 55 secondes. Il s'agit du montant maximal de temps nécessaire au serveur backend pour traiter la requête et répondre au message Sous-traitant. Le délai avant expiration par défaut peut être ignoré dans les processeurs de messages ou dans l'API. comme expliqué dans la section <ph type="x-smartling-placeholder"></ph> Configurer le délai d'expiration des E/S sur les processeurs de messages
Si le client ferme la connexion au routeur avant l'expiration du délai d'attente du proxy API, vous
observe l'erreur d'expiration de délai
pour la requête API concernée. Le code d'état 499 Client
Closed Connection est enregistré dans le routeur pour ces requêtes, et peut être observé dans l'API.
Journaux Monitoring et NGINX Access Logs.
Causes possibles :
Dans Edge, les causes typiques de l'erreur 499 Client Closed Connection sont les suivantes:
| Cause | Description | Instructions de dépannage applicables |
|---|---|---|
| Le client a brusquement mis fin à la connexion | Cela se produit lorsque le client ferme la connexion parce que l'utilisateur final annule la avant qu'elle ne soit traitée. | Utilisateurs de cloud public et privé |
| Délai avant expiration de l'application cliente | Cela se produit lorsque l'application cliente expire avant que le proxy d'API n'ait le temps de traiter et envoyer la réponse. Cela se produit généralement lorsque le délai avant expiration du client est inférieur que le délai avant expiration du routeur. | Utilisateurs de cloud public et privé |
Étapes de diagnostic courantes
Utilisez l'une des techniques ou l'un des outils suivants pour diagnostiquer ce problème:
- Surveillance des API
- Journaux d'accès NGINX
Surveillance des API
<ph type="x-smartling-placeholder">Pour diagnostiquer l'erreur à l'aide de l'API Monitoring, procédez comme suit:
- Accédez à Analyser > Surveillance des API > Examiner.
- Filtrez les erreurs
4xxet sélectionnez la période. - Représentez le code d'état par rapport à l'heure.
- Sélectionnez une cellule contenant
499erreurs, comme indiqué ci-dessous: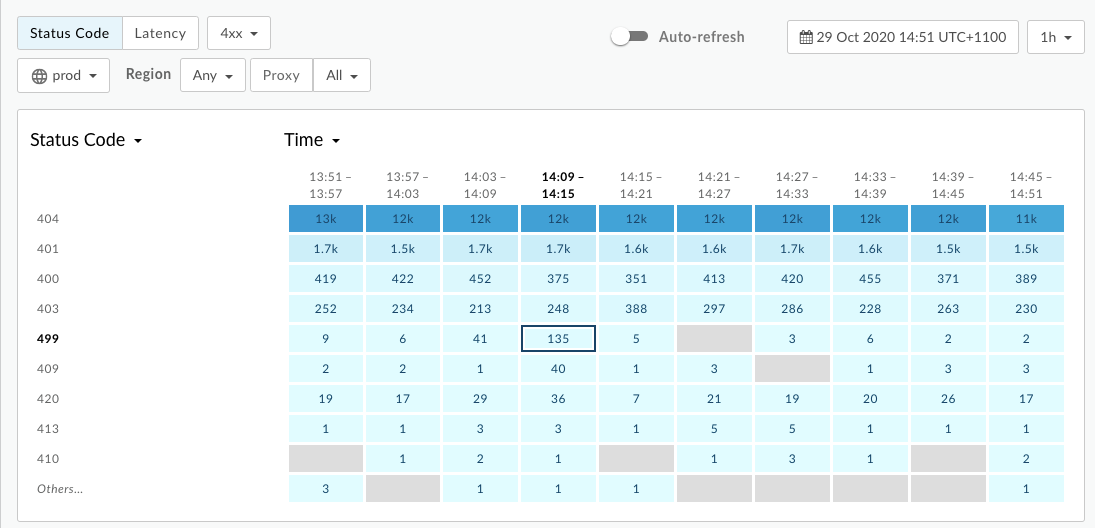
- Les informations sur l'erreur
499s'affichent dans le volet de droite sous la forme comme indiqué ci-dessous: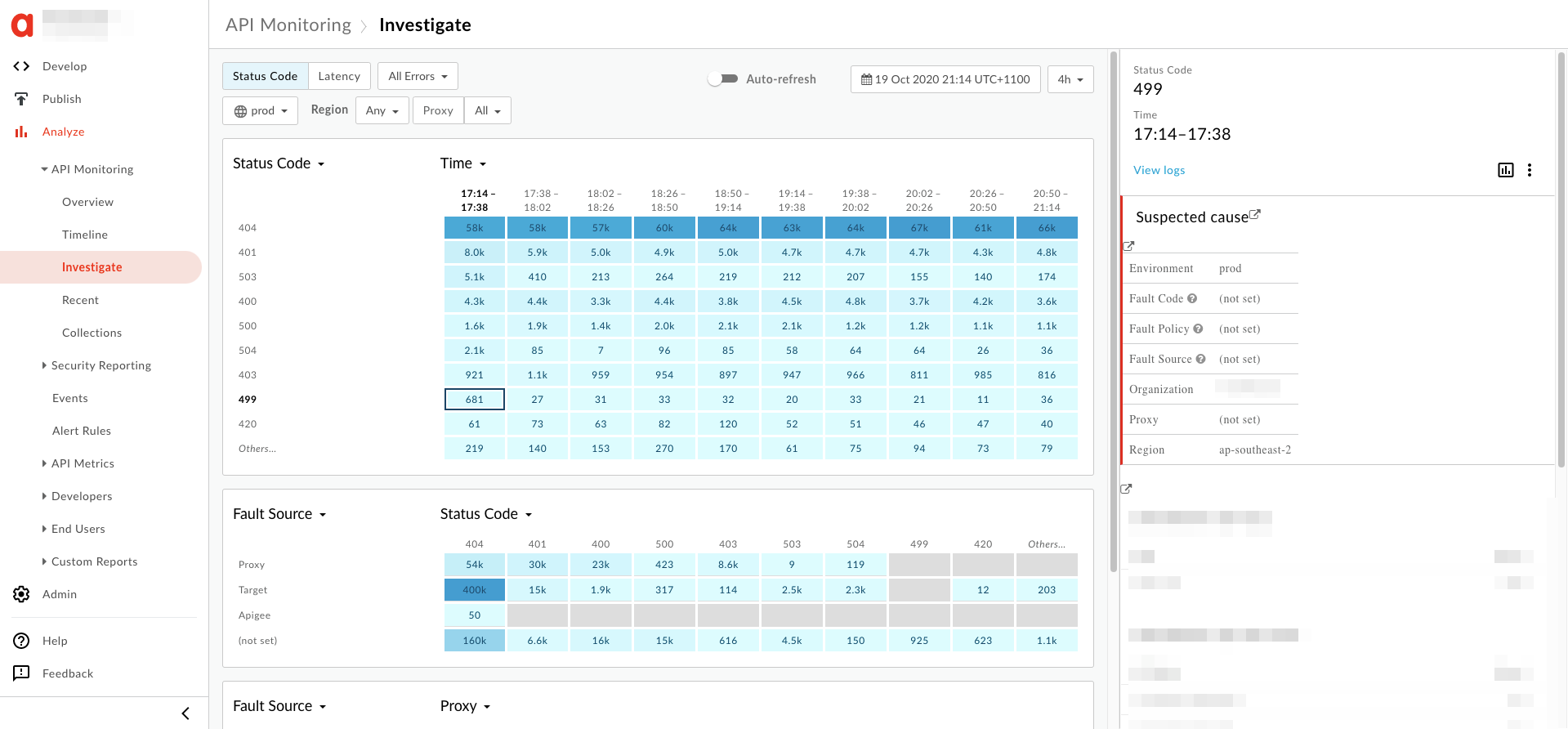
- Dans le volet de droite, cliquez sur Afficher les journaux.
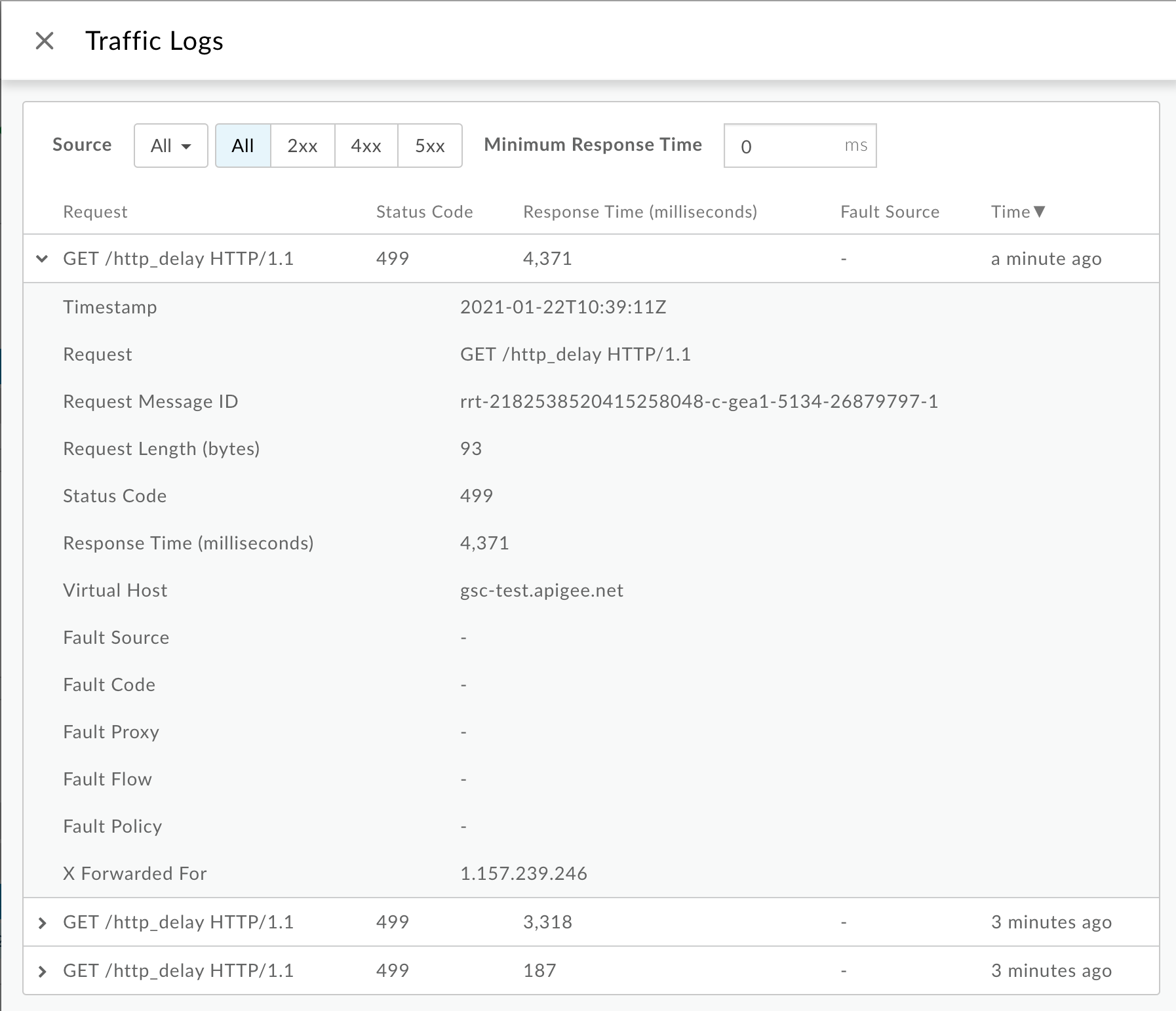
Dans la fenêtre Traffic Logs (Journaux de trafic), notez les détails suivants pour certains
499. erreurs:- Request:fournit la méthode de requête et l'URI utilisés pour effectuer les appels.
- Response Time (Temps de réponse) : indique le temps total écoulé pour la requête.
Vous pouvez également obtenir tous les journaux en utilisant l'API Monitoring GET logs. Pour par exemple, en interrogeant les journaux sur
org,env,timeRangeetstatus, vous pouvez télécharger les journaux des transactions pour lesquelles le client a expiré.Étant donné que API Monitoring définit le proxy sur
-pour HTTP499vous pouvez utiliser l'API (API Logs) pour obtenir associé à l'hôte virtuel et au chemin d'accès.For example :
curl "https://apimonitoring.enterprise.apigee.com/logs/apiproxies?org=ORG&env=ENV&select=https://VIRTUAL_HOST/BASEBATH" -H "Authorization: Bearer $TOKEN"
- Consultez le temps de réponse pour voir si d'autres erreurs
499s'affichent et vérifiez si Le temps de réponse doit rester le même (par exemple, 30 secondes) sur l'ensemble des499erreurs.
Journaux d'accès NGINX
<ph type="x-smartling-placeholder">Pour diagnostiquer l'erreur à l'aide des journaux d'accès NGINX:
- Si vous utilisez Private Cloud, vous pouvez utiliser les journaux d'accès NGINX pour déterminer
les informations clés sur les erreurs HTTP
499. - Vérifiez les journaux d'accès NGINX:
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - Effectuez une recherche pour voir s'il existe des erreurs
499pendant une durée spécifique (si le problème s'est produit dans le passé) ou si des requêtes échouent encore avec499 - Notez les informations suivantes pour certaines des erreurs
499: <ph type="x-smartling-placeholder">- </ph>
- Temps de réponse total
- URI de la demande
- User-agent
Exemple d'erreur 499 dans le journal d'accès NGINX:
2019-08-23T06:50:07+00:00 rrt-03f69eb1091c4a886-c-sy 50.112.119.65:47756 10.10.53.154:8443 10.001 - - 499 - 422 0 GET /v1/products HTTP/1.1 - okhttp/3.9.1 api.acme.org rrt-03f69eb1091c4a886-c-sy-13001-6496714-1 50.112.119.65 - - - - - - - -1 - - dc-1 router-pod-1 rt-214-190301-0020137-latest-7d 36 TLSv1.2 gateway-1 dc-1 acme prod https -
Pour cet exemple, nous voyons les informations suivantes:
- Temps de réponse total:
10.001secondes. Cela indique que le Le client a expiré au bout de 10 001 secondes - Requête:
GET /v1/products - Hôte:
api.acme.org - User-agent:
okhttp/3.9.1
- Vérifiez que le temps de réponse total et l'user-agent sont cohérents.
pour toutes les erreurs
499.
Cause: le client a brusquement fermé la connexion
Diagnostic
- Lorsqu'une API est appelée à partir d'une application monopage exécutée dans un navigateur ou une application mobile, le navigateur annule la requête si l'utilisateur final ferme soudainement le navigateur et navigue vers une autre page Web du même onglet, ou interrompt le chargement de la page en cliquant ou en appuyant arrêter le chargement.
- Dans ce cas, les transactions avec l'état HTTP
499varient généralement dans le temps de traitement de la requête (temps de réponse) pour chacune des demandes. -
Pour déterminer si c'est le cas, comparez le temps de réponse et vérifiez si
elle est différente pour chacune des erreurs
499à l'aide de l'API Monitoring ou de l'accès NGINX comme expliqué dans la section Étapes de diagnostic courantes.
Solution
- C'est normal et n'est généralement pas préoccupant si l'erreur HTTP
499se produisent en petites quantités. -
Si le problème se produit souvent pour le même chemin d'URL, il est possible que le proxy en question associées à ce chemin est très lent et les utilisateurs ne sont pas prêts à attendre.
Une fois que vous avez identifié le proxy susceptible d'être concerné, utilisez la Latence du tableau de bord d'analyse afin d'examiner plus en détail les causes de la latence du proxy.
- Dans ce cas, déterminez le proxy concerné en suivant les étapes décrites dans Étapes de diagnostic courantes.
- Utilisez le tableau de bord d'analyse de la latence pour examiner plus en détail les causes de la latence du proxy résoudre le problème.
- Si vous constatez que la latence est attendue pour le proxy spécifique, vous avez peut-être pour informer vos utilisateurs que ce proxy mettra un certain temps à répondre.
Cause: expiration de l'application cliente
Cela peut se produire dans de nombreux scénarios.
-
Le traitement de la requête prend généralement un certain temps (par exemple, 10 secondes)
dans des conditions normales de fonctionnement. Cependant, l'application cliente est définie avec un
de délai d'inactivité (par exemple, 5 secondes), ce qui entraîne le dépassement du délai avant expiration de l'application cliente
la requête API est terminée, ce qui conduit à
499. Dans ce cas, nous devons définir le délai avant expiration du client sur une valeur appropriée. - Un serveur cible ou un appel prend plus de temps que prévu. Dans ce cas, vous devez corriger le composant approprié et ajuster les valeurs de délai avant expiration de manière appropriée.
- Le client n'a plus besoin de la réponse et a donc annulé. Cela peut se produire pour des de fréquence, telles que la saisie semi-automatique ou les interrogations courtes.
Diagnostic
Journaux d'accès NGINX ou API Monitoring
Diagnostiquez l'erreur à l'aide des journaux d'accès de l'API Monitoring ou de NGINX:
- Consultez les journaux de surveillance de l'API ou les journaux d'accès NGINX pour les transactions HTTP
499, comme expliqué dans Étapes de diagnostic courantes. - Déterminez si le temps de réponse est cohérent pour toutes les erreurs
499. - Si oui, il se peut qu'une application cliente spécifique ait configuré un délai d'expiration fixe
de son côté. Si un proxy API ou un serveur cible répond lentement, le client expire
avant l'expiration du proxy, ce qui entraîne de grandes quantités de
499sHTTP pour le même chemin d'URI. Dans ce cas, identifiez l'user-agent dans les journaux d'accès NGINX qui peut vous aider à déterminer l'application cliente spécifique. - Il est également possible qu'il y ait un équilibreur de charge devant Apigee, comme Akamai, F5, AWS ELB, etc. Si Apigee s'exécute derrière un équilibreur de charge personnalisé, la requête le délai avant expiration de l'équilibreur de charge doit être configuré pour être supérieur à celui de l'API Apigee. Par par défaut, le routeur Apigee expire au bout de 57 secondes. Il convient donc à la configuration d'une requête et un délai avant expiration de 60 secondes sur l'équilibreur de charge.
Trace
Diagnostiquer l'erreur à l'aide de Trace
Si le problème est toujours actif (499 erreurs persistent), effectuez la
procédez comme suit:
- Activez le session Trace pour l'API concernée dans l'interface utilisateur Edge.
- Attendez que l'erreur se produise ou, si vous disposez de l'appel d'API, effectuez des appels d'API. et reproduire l'erreur.
- Vérifiez le temps écoulé à chaque phase et notez la phase au cours de laquelle est dépensé.
- Si vous observez l'erreur avec le temps écoulé le plus long immédiatement après l'une des
cela indique que le serveur backend est lent ou qu'il prend beaucoup de temps
pour traiter la demande:
<ph type="x-smartling-placeholder">
- </ph>
- Demande envoyée au serveur cible
- Règle ServiceCallout
Voici un exemple de trace d'interface utilisateur montrant un délai d'expiration de la passerelle après que la requête a été envoyées au serveur cible:
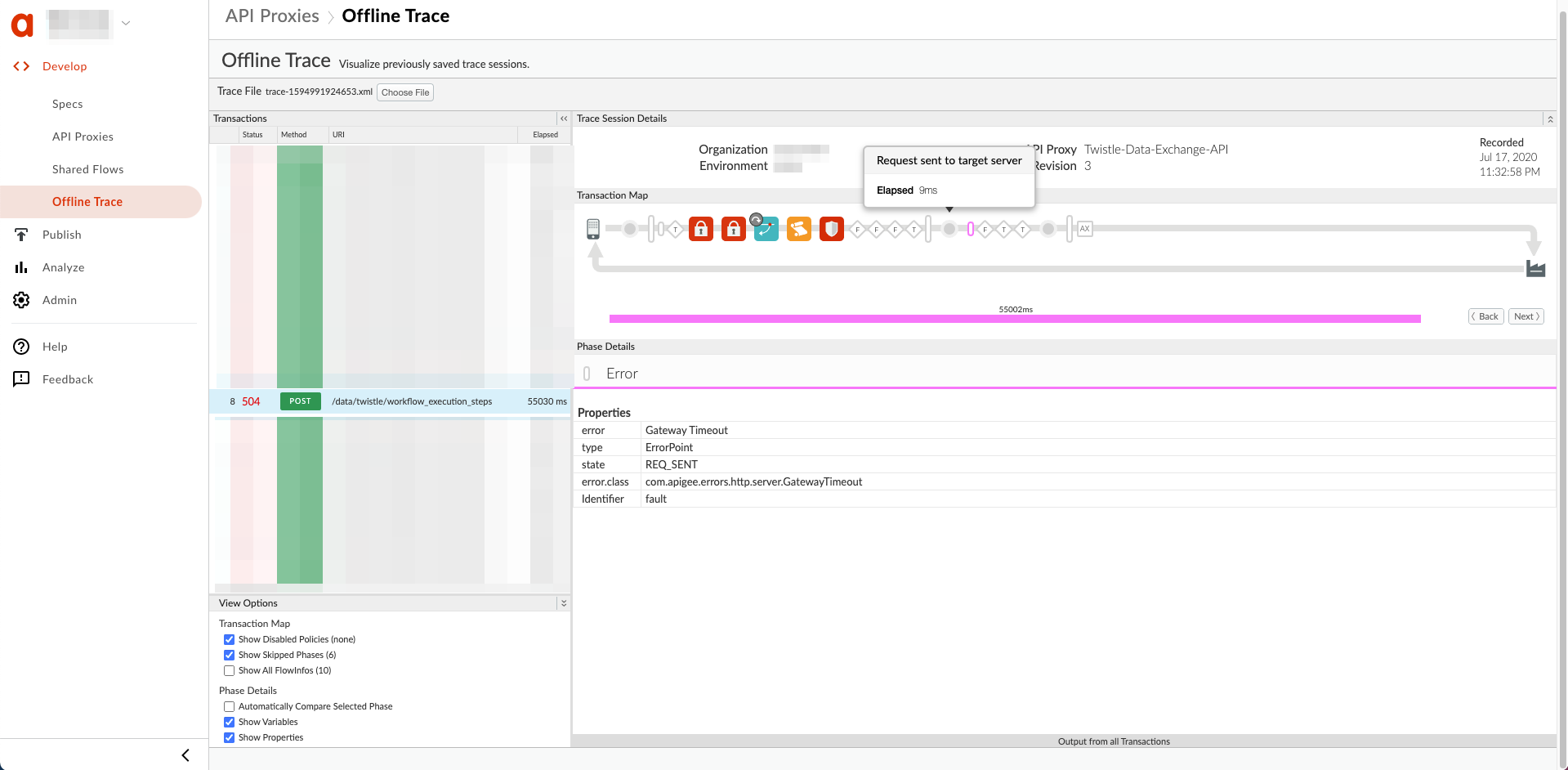
Solution
- Reportez-vous à Bonnes pratiques de configuration du délai d'expiration des E/S pour comprendre quelles valeurs de délai avant expiration doivent être définies sur les différents composants impliqués dans le flux de requête API dans Apigee Edge.
- Assurez-vous de définir un délai d'expiration approprié sur l'application cliente en fonction les bonnes pratiques.
Si le problème persiste, consultez Collecter des informations de diagnostic .
Vous devez collecter des informations de diagnostic
Si le problème persiste, rassemblez les informations de diagnostic suivantes, puis contactez l'assistance Apigee Edge.
Si vous êtes un utilisateur de Cloud public, fournissez les informations suivantes:
- Nom de l'organisation
- Nom de l'environnement
- Nom du proxy d'API
- Exécutez la commande
curlutilisée pour reproduire l'erreur de délai d'inactivité. - Fichier de suivi des requêtes API pour lesquelles vous constatez des erreurs d'expiration du délai client
Si vous êtes un utilisateur de Private Cloud, fournissez les informations suivantes:
- Message d'erreur complet observé pour les requêtes en échec
- Nom de l'environnement
- Groupe de proxys d'API
- Fichier de suivi des requêtes API pour lesquelles vous constatez des erreurs d'expiration du délai client
- Journaux d'accès NGINX (
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - Journaux système du processeur de messages (
/opt/apigee/var/log/edge-message-processor/logs/system.log)