
<ph type="x-smartling-placeholder"></ph>
Sie sehen die Dokumentation zu Apigee Edge.
Gehen Sie zur
Apigee X-Dokumentation. Weitere Informationen
Videos
Sehen Sie sich die folgenden Videos an, um mehr über das Beheben des Fehlers 500 (interner Serverfehler) zu erfahren.
| Video | Beschreibung |
|---|---|
| Einführung | Bietet eine Einführung in 500 interne Serverfehler und mögliche Ursachen. Zeigt außerdem Einen Echtzeitfehler vom Typ „500 Internal Server“ mit Schritten zur Fehlerbehebung. |
| Fehler vom Typ „Service Callout“ und „Variablen extrahieren“ | Zeigt zwei interne Serverfehler des Typs „500“, die durch die Richtlinien „Service Callout“ und „Variablen extrahieren“ verursacht wurden. und erfahren, wie Sie diese Fehler beheben können. |
| JavaScript-Richtlinienfehler beheben | Zeigt den durch eine JavaScript-Richtlinie verursachten internen Serverfehler 500 und die Schritte an um diesen Fehler zu beheben. |
| Fehler auf Back-End-Servern verarbeiten | Zeigt Beispiel für interne Serverfehler 500, die durch einen Fehler im Backend-Server verursacht wurden, mit Schritten um die Fehler zu beheben. |
Symptom
Die Clientanwendung erhält den HTTP-Statuscode 500 zusammen mit der Meldung "Internal Server Error" als Antwort auf API-Aufrufe zurückgegeben. Der interne 500-Server Fehler kann durch einen Fehler während der Ausführung einer Richtlinie in Edge oder durch einen Fehler auf dem Ziel-/Back-End-Server.
Der HTTP-Statuscode 500 ist eine allgemeine Fehlerantwort. Es bedeutet, dass der Server unerwartete Bedingung, die verhindert hat, dass die Anfrage ausgeführt werden konnte. Dieser Fehler tritt in der Regel wenn kein anderer Fehlercode geeignet ist.
Fehlermeldungen
Möglicherweise wird die folgende Fehlermeldung angezeigt:
HTTP/1.1 500 Internal Server Error
In einigen Fällen wird eine weitere Fehlermeldung mit weiteren Details angezeigt. Hier ist ein Beispiel Fehlermeldung:
{
"fault":{
"detail":{
"errorcode":"steps.servicecallout.ExecutionFailed"
},
"faultstring":"Execution of ServiceCallout callWCSAuthServiceCallout failed. Reason: ResponseCode 400 is treated as error"
}
}Mögliche Ursachen
Der interne Serverfehler 500 kann aufgrund verschiedener Ursachen ausgegeben werden. In Edge können die Ursachen je nachdem, wo der Fehler aufgetreten ist, in zwei Hauptkategorien unterteilt werden:
| Ursache | Details | Detaillierte Schritte zur Fehlerbehebung |
| Ausführungsfehler in einer Edge-Richtlinie | Eine Richtlinie im API-Proxy aus irgendeinem Grund fehlschlägt. | Private und öffentliche Edge-Cloud-Nutzer |
| Fehler im Backend-Server | Der Backend-Server kann aus irgendeinem Grund ausfallen. | Private und öffentliche Edge-Cloud-Nutzer |
Ausführungsfehler in einer Edge-Richtlinie
Eine Policy innerhalb kann der API-Proxy aus irgendeinem Grund fehlschlagen. In diesem Abschnitt wird erläutert, wie Sie das Problem beheben können, wenn Der interne Serverfehler 500 tritt während der Ausführung einer Richtlinie auf.
Diagnose
Diagnoseschritte für Nutzer der privaten und öffentlichen Cloud
Wenn Ihnen die Trace-UI-Sitzung für den Fehler vorliegt, gehen Sie so vor:
- Prüfen Sie, ob der Fehler durch die Ausführung einer Richtlinie verursacht wurde. Weitere Informationen finden Sie unter Problemursache ermitteln.
- Wenn der Fehler bei der Ausführung der Richtlinie aufgetreten ist, fahren Sie fort. Wenn der Fehler durch das zu Fehler im Backend-Server.
- Wählen Sie die API-Anfrage aus, die mit dem Fehler 500 (Interner Serverfehler) im Trace fehlschlägt.
- Prüfen Sie die Anfrage und wählen Sie die spezifische Richtlinie aus, die fehlgeschlagen ist, oder den benannten Ablauf „Fehler“ die direkt auf die fehlgeschlagene Richtlinie im Trace folgt.
- Weitere Details zum Fehler erhalten Sie, indem Sie in der Spalte „Fehler“ unter den Eigenschaften oder den Fehlerinhalt.
- Versuchen Sie, die Ursache des Fehlers mithilfe der Details zu ermitteln, die Sie zum Fehler erfasst haben.
Diagnoseschritte nur für Private Cloud-Nutzer
Wenn Sie die UI-Trace-Sitzung nicht haben, gehen Sie so vor:
- Prüfen Sie, ob der Fehler beim Ausführen einer Richtlinie aufgetreten ist. Weitere Informationen finden Sie unter Problemursache ermitteln.
- Wenn der Fehler durch die Ausführung einer Richtlinie verursacht wurde, fahren Sie fort. Wenn der Fehler während der Richtlinie aufgetreten ist ausgeführt haben, fahren Sie fort. Wenn der Fehler vom Back-End-Server verursacht wurde, wechseln Sie zu Fehler im Back-End-Server.
- Verwenden Sie die NGINX-Zugriffs-Logs, wie unter Ermitteln von die Ursache des Problems, um die fehlerhafte Richtlinie im API-Proxy sowie den eindeutige ID der Anfragenachricht
- Message Processor-Logs prüfen
(
/opt/apigee/var/log/edge-message-processor/logs/system.log) und suche nach eindeutige ID der Anfragenachricht. - Wenn Sie die eindeutige ID der Anfragenachricht finden, versuchen Sie, weitere Informationen zur Fehlerursache anzeigen.
Auflösung
Wenn Sie die Ursache des Problems mit der Richtlinie ermittelt haben, versuchen Sie, das Problem zu beheben, indem Sie Korrigieren der Richtlinie und erneutes Bereitstellen des Proxys.
Die folgenden Beispiele veranschaulichen, wie Sie die Ursache und Lösung für verschiedene Arten von Problemen.
Wenn Sie weitere Unterstützung bei der Behebung des Fehlers „500 Internal Server Error“ benötigen oder dass es ein Problem in Edge ist, wenden Sie sich an Apigee Support.
Beispiel 1: Fehler in der Service-Callout-Richtlinie aufgrund eines Fehlers im Backend Server
Wenn der Aufruf an den Back-End-Server innerhalb der Service Callout-Richtlinie mit einem Fehler wie als 4XX oder 5XX, wird er als 500 interner Serverfehler behandelt.
- Hier ist ein Beispiel, bei dem der Back-End-Dienst mit einem 404-Fehler innerhalb des Dienstes fehlschlägt.
Callout-Richtlinie. Die folgende Fehlermeldung wird an den Endnutzer gesendet:
{ "fault": { "detail": { "errorcode":"steps.servicecallout.ExecutionFailed" },"faultstring":"Execution of ServiceCallout service_callout_v3_store_by_lat_lon failed. Reason: ResponseCode 404 is treated as error" } } } - In der folgenden Trace-UI-Sitzung wird der Statuscode 500 aufgrund eines Fehlers im Dienst angezeigt
Callout-Richtlinie:
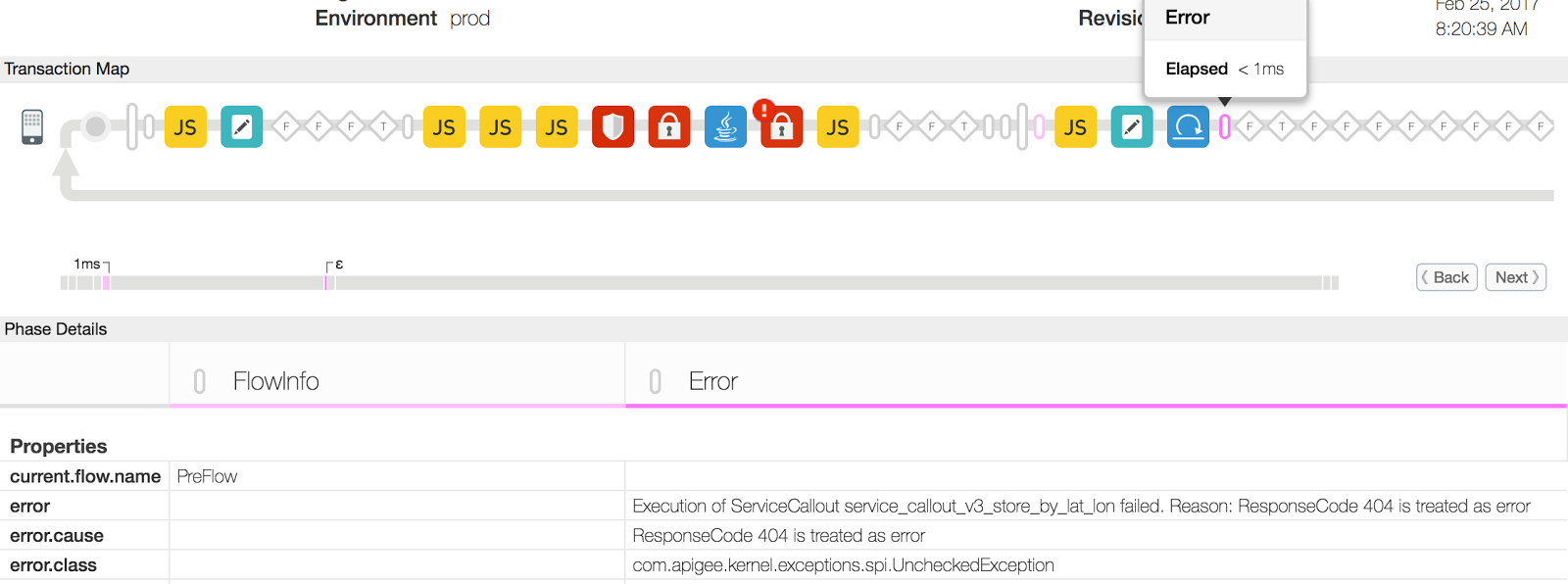
- In diesem Beispiel hat „error“ enthält den Grund für die Service Callout-Richtlinie. Fehler als "ResponseCode 404 isTreatment as error". Dieser Fehler kann auftreten, wenn Die Ressource, auf die über die Backend-Server-URL in der Service Callout-Richtlinie zugegriffen wird, ist nicht verfügbar.
- Prüfe die Verfügbarkeit der Ressource auf dem Back-End-Server. Sie ist möglicherweise nicht verfügbar vorübergehend/dauerhaft oder an einen anderen Standort verlegt worden ist.
Lösungsbeispiel 1
- Prüfe die Verfügbarkeit der Ressource auf dem Back-End-Server. Sie ist möglicherweise nicht verfügbar vorübergehend/dauerhaft oder an einen anderen Standort verlegt worden ist.
- Korrigieren Sie die Backend-Server-URL in der Service Callout-Richtlinie so, dass sie auf eine gültige und vorhandene .
- Ist die Ressource nur vorübergehend nicht verfügbar, versuchen Sie, die API-Anfrage zu senden, sobald der Ressource verfügbar ist.
Beispiel 2: Fehler in der Richtlinie zum Extrahieren von Variablen
Sehen wir uns nun ein weiteres Beispiel an, bei dem „500 Internal Server Error“ in der Richtlinie „Variablen extrahieren“ an und beheben Sie das Problem.
- Der folgende Trace in der UI-Sitzung zeigt den Statuscode 500 aufgrund eines Fehlers in der Extrahierung an
Variablenrichtlinie:
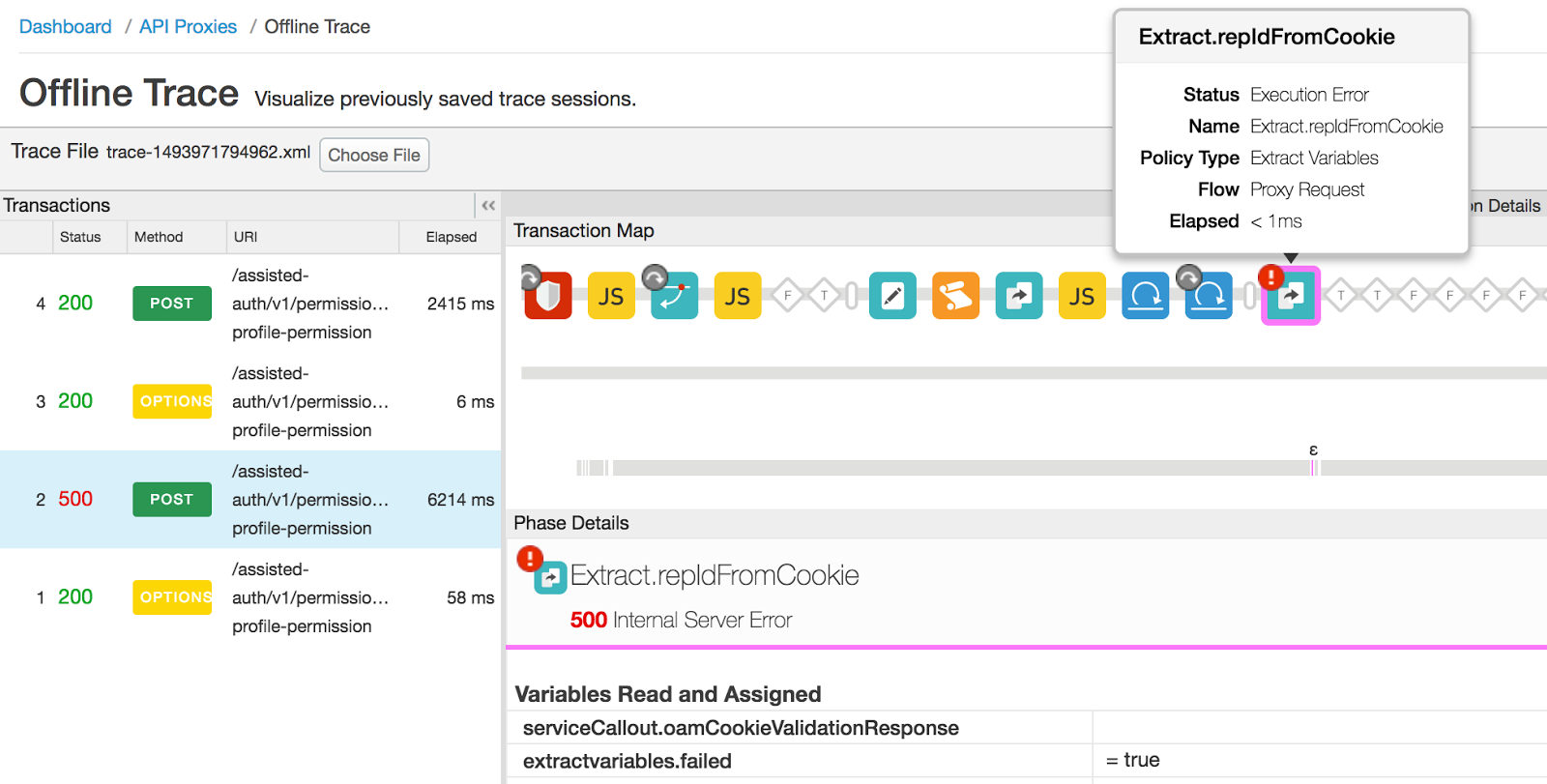
- Wählen Sie die fehlerhafte Richtlinie zum Extrahieren von Variablen aus, scrollen Sie nach unten und sehen Sie sich die Fehlermeldung "Fehler
„Inhalt“ finden Sie weitere Informationen:

- Der Fehlerinhalt gibt an, dass Die Variable "serviceCallout.oamCookieValidationResponse" ist in die Richtlinie „Variablen extrahieren“. Wie der Name der Variablen aussagt, sollte sie den Parameter Antwort der vorherigen Service Callout-Richtlinie.
- Wenn Sie die Service Callout-Richtlinie im Trace auswählen, stellen Sie möglicherweise fest, dass das "serviceCallout.oamCookieValidationResponse" Variable wurde nicht festgelegt. Dieses zeigt an, dass der Aufruf an den Back-End-Dienst fehlgeschlagen ist, was zu einer leeren Antwort führt .
- Obwohl die Service-Callout-Richtlinie fehlgeschlagen ist, wird die Ausführung der Richtlinien nach dem Service
Die Richtlinie für Zusatzinformationen wird fortgesetzt, weil „continueOnError“ in der Service Callout-Richtlinie gesetzt ist.
auf „true“, wie unten gezeigt:
<ServiceCallout async="false" continueOnError="true" enabled="true" name="Callout.OamCookieValidation"> <DisplayName>Callout.OamCookieValidation</DisplayName> <Properties /> <Request clearPayload="true" variable="serviceCallout.oamCookieValidationRequest"> <IgnoreUnresolvedVariables>false</IgnoreUnresolvedVariables> </Request> <Response>serviceCallout.oamCookieValidationResponse</Response> <HTTPTargetConnection> <Properties /> <URL>http://{Url}</URL> </HTTPTargetConnection> </ServiceCallout>
- Notieren Sie sich die eindeutige Nachrichten-ID "X-Apigee.Message-ID" für diese spezifische API.
aus dem Trace anfordern:
<ph type="x-smartling-placeholder">
- </ph>
- Wählen Sie die Option "Aufgezeichnete Analytics-Daten" aus. Phase aus der Anfrage.
- Scrollen Sie nach unten und notieren Sie sich den Wert von X-Apigee.Message-ID.
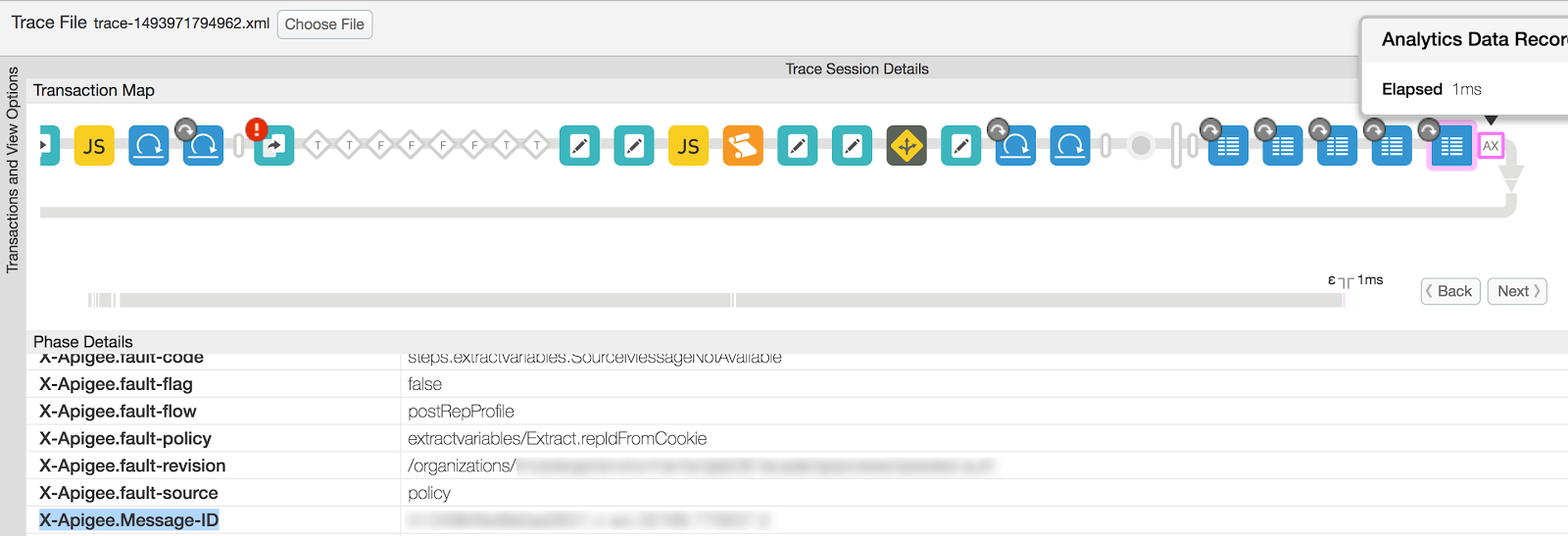
- Message Processor-Protokoll aufrufen
(
/opt/apigee/var/log/edge-message-processor/system.log) und suchen Sie nach dem eindeutigen die in Schritt 6 notierte Nachrichten-ID erhalten haben. Für die jeweilige API wurde die folgende Fehlermeldung angezeigt Anfrage:2017-05-05 07:48:18,653 org:myorg env:prod api:myapi rev:834 messageid:rrt-04984fed9e5ad3551-c-wo-32168-77563 NIOThread@5 ERROR HTTP.CLIENT - HTTPClient$Context.onTimeout() : ClientChannel[C:]@149081 useCount=1 bytesRead=0 bytesWritten=0 age=3002ms lastIO=3002ms .onConnectTimeout connectAddress=mybackend.domain.com/XX.XX.XX.XX:443 resolvedAddress=mybackend.domain.com/XX.XX.XX.XX
Der obige Fehler gibt an, dass die Service Callout-Richtlinie aufgrund einer Verbindung fehlgeschlagen ist. Zeitüberschreitungsfehler beim Herstellen der Verbindung zum Backend-Server.
- Um die Ursache für den Verbindungszeitüberschreitungsfehler zu ermitteln, haben Sie den
telnet-Befehl von den Message Processor(s) an den Back-End-Server. Das Telnet
Befehl „Connection timed out“ wie unten dargestellt:
telnet mybackend.domain.com 443 Trying XX.XX.XX.XX... telnet: connect to address XX.XX.XX.XX: Connection timed out
Dieser Fehler tritt normalerweise unter folgenden Umständen auf:
- Wenn der Backend-Server nicht so konfiguriert ist, dass Traffic von der Edge-Nachricht zugelassen wird Prozessoren.
- Wenn der Backend-Server den bestimmten Port nicht überwacht.
Im obigen Beispiel schlug die Richtlinie zum Extrahieren von Variablen fehl, die eigentliche Ursache war, dass Edge im Service-Callout keine Verbindung zum Backend-Server herstellen konnte. . Der Grund für diesen Fehler war, dass der Back-End-Endserver nicht so konfiguriert wurde, Traffic von den Edge Message Processors zulassen.
Ihre eigene Richtlinie zum Extrahieren von Variablen verhält sich anders und schlägt möglicherweise für eine andere Grund. Je nach Fehlerursache können Sie das Problem Überprüfen Sie dazu die Meldung im Feld error. Property.
Lösungsbeispiel 2
- Beheben Sie die Fehlerursache bzw. den Fehler in der Richtlinie zum Extrahieren von Variablen entsprechend.
- Im obigen Beispiel bestand die Lösung darin, die Netzwerkkonfiguration so zu ändern, den Traffic von Edge Message Processors zu Ihrem Back-End-Server zulassen. Dies wurde vorgenommen von der Message Processors IP-Adressen auf dem jeweiligen Back-End-Server. Beispiel: iptables, um den Traffic von IP-Adressen des Message Processor auf dem Backend-Server.
Beispiel 3: Fehler in der JavaCallout-Richtlinie
Sehen wir uns nun ein weiteres Beispiel an, bei dem „500 Internal Server Error“ in der Java-Richtlinie für Callouts und erfahren, wie Sie das Problem beheben können.
- Im folgenden UI-Trace wird der Statuscode 500 aufgrund eines Fehlers in der Java-Callout-Richtlinie angezeigt:
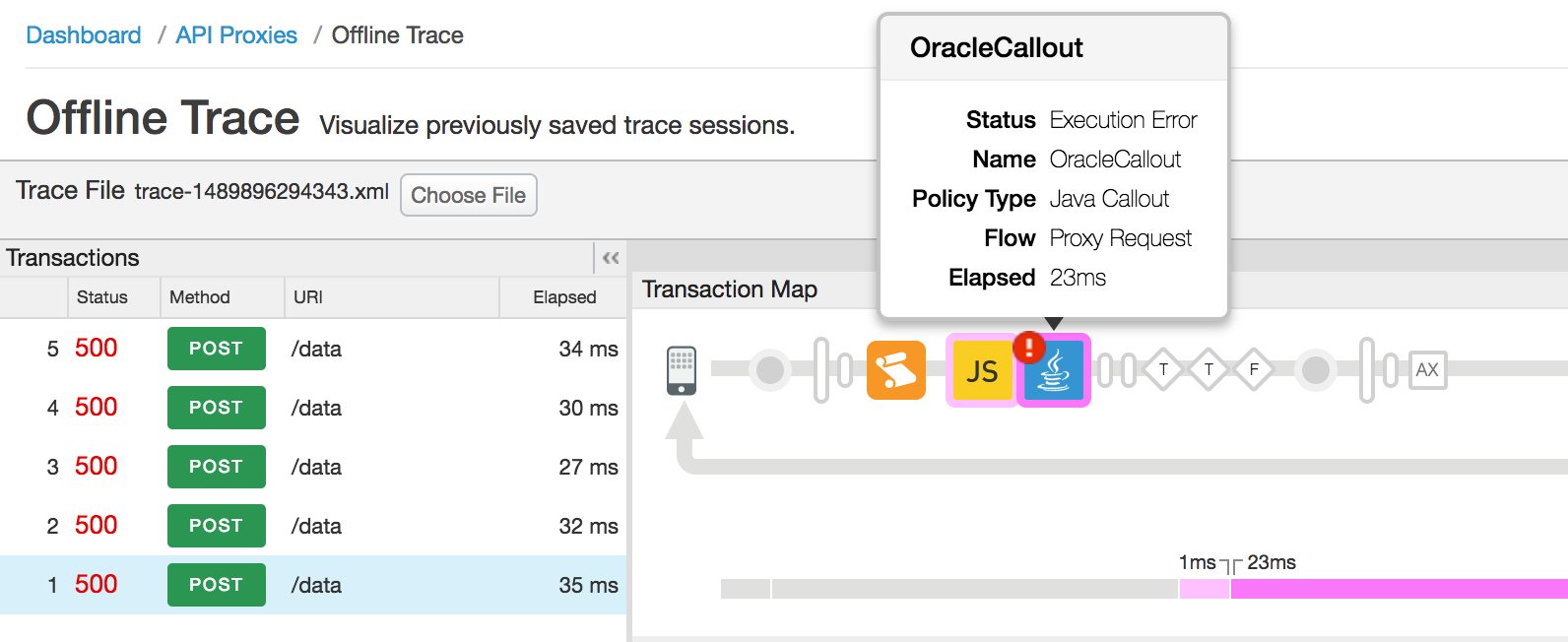
- Wählen Sie den Ablauf mit dem Namen "Error", gefolgt von der fehlgeschlagenen Java-Callout-Richtlinie aus.
um die Fehlerdetails abzurufen, wie in der folgenden Abbildung dargestellt:
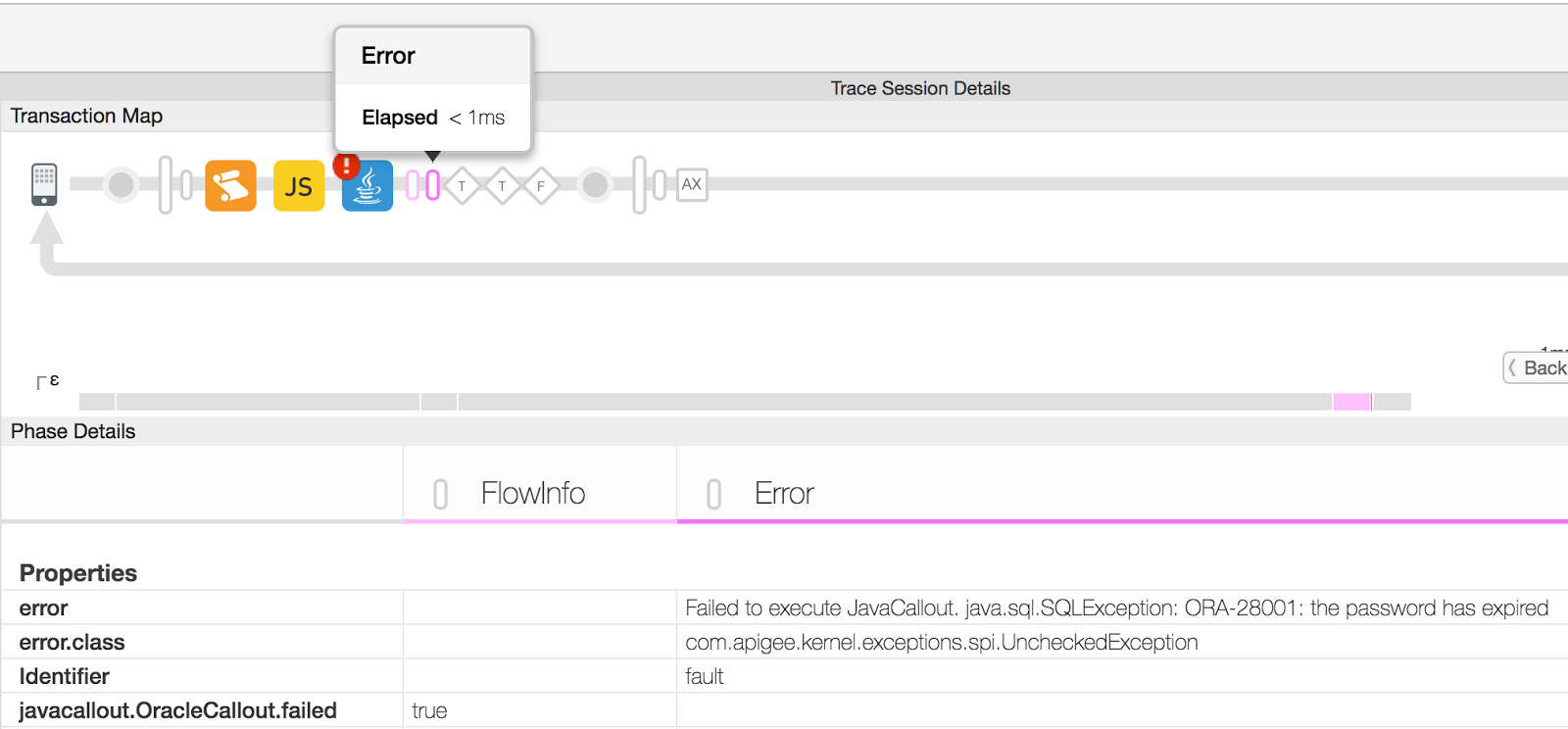
- In diesem Beispiel zeigt die Eigenschaft "error" im Bereich "Eigenschaften" Der Fehler ist darauf zurückzuführen, dass beim Herstellen einer Verbindung zur Oracle-Datenbank ein abgelaufenes Passwort verwendet wurde. in der JavaCallout-Richtlinie. Ihr eigenes Java-Callout verhält sich anders und wird im Attribut error eine andere Meldung angezeigt.
- Überprüfen Sie den JavaCallout-Richtliniencode und bestätigen Sie die korrekte Konfiguration, verwendet.
Lösungsbeispiel 3
Korrigieren Sie den Java-Callout-Code oder die Konfiguration entsprechend, um die Laufzeitausnahme zu vermeiden. In dem oben dargestellten Beispiel für einen Java-Callout-Fehler, muss das richtige Passwort verwendet werden. um eine Verbindung zur Oracle-Datenbank herzustellen, um das Problem zu beheben.
Fehler im Backend-Server
Der Fehler 500 (Interner Serverfehler) könnte auch vom Back-End-Server stammen. Dieser Abschnitt wird erläutert, wie Sie das Problem beheben, wenn der Fehler vom Back-End-Server verursacht wird.
Diagnose
Diagnoseschritte für alle Nutzer
Die Ursachen anderer Back-End-Fehler können sehr unterschiedlich sein. Sie müssen jede Situation diagnostizieren unabhängig voneinander unterscheiden.
- Überprüfen Sie, ob der Fehler vom Back-End-Server verursacht wurde. Weitere Informationen finden Sie unter Problemursache ermitteln.
- Wenn der Fehler vom Backend-Server verursacht wurde, fahren Sie fort. Wenn der Fehler während Richtlinienausführung finden Sie unter Ausführungsfehler in Edge Richtlinien:
- Führen Sie die folgenden Schritte aus, je nachdem, ob Sie Zugriff auf eine Trace-Sitzung für die fehlgeschlagene API oder wenn das Back-End ein Node.js-Server ist:
Wenn Sie keine Trace-Sitzung für den fehlgeschlagenen API-Aufruf haben:
- Wenn das UI-Trace für die fehlgeschlagene Anfrage nicht verfügbar ist, prüfen Sie den Backend-Server. Logs, um Details zum Fehler zu erhalten.
- Aktivieren Sie nach Möglichkeit den Debug-Modus auf dem Backend-Server, um weitere Details zum Fehler und die Ursache ermitteln.
Wenn Sie eine Trace-Sitzung für den fehlgeschlagenen API-Aufruf haben:
Wenn Sie eine Trace-Sitzung haben, helfen Ihnen die folgenden Schritte bei der Diagnose des Problems.
- Wählen Sie im Trace-Tool die API-Anfrage aus, die mit „500 Internal Server“ fehlgeschlagen ist. Fehler.
- Wählen Sie die Phase Antwort vom Zielserver erhalten aus.
API-Anfrage wie in der folgenden Abbildung gezeigt:
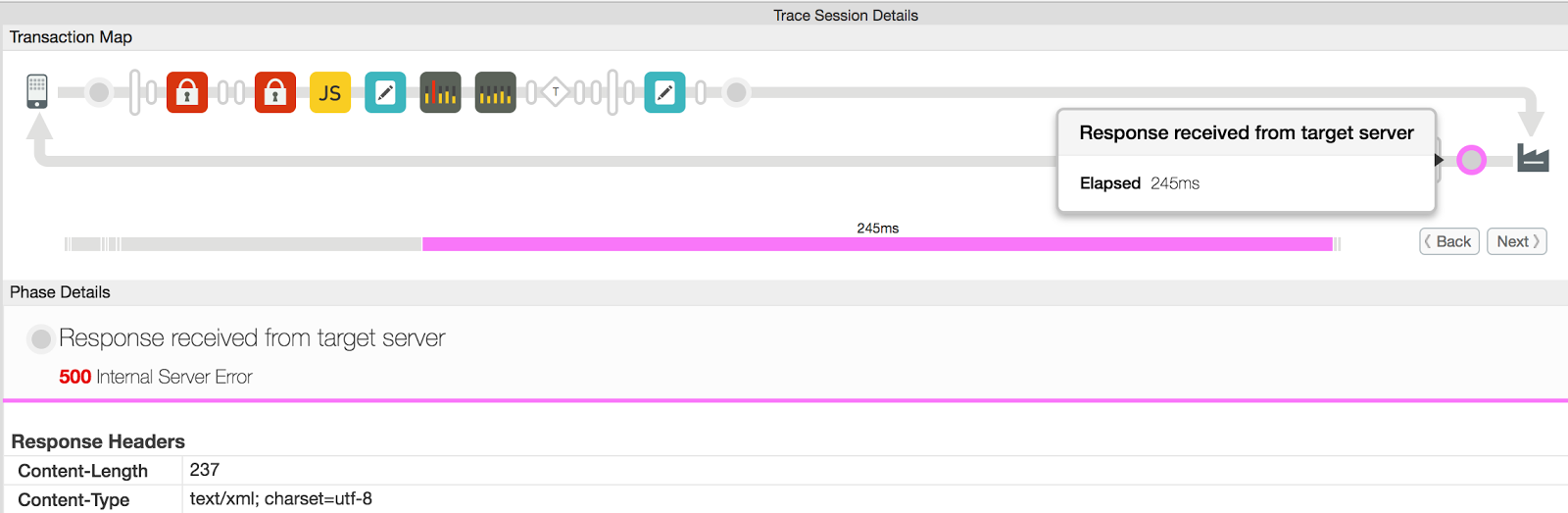
- Im Abschnitt "Response Content" (Antwortinhalt) finden Sie Details zum Fehler.
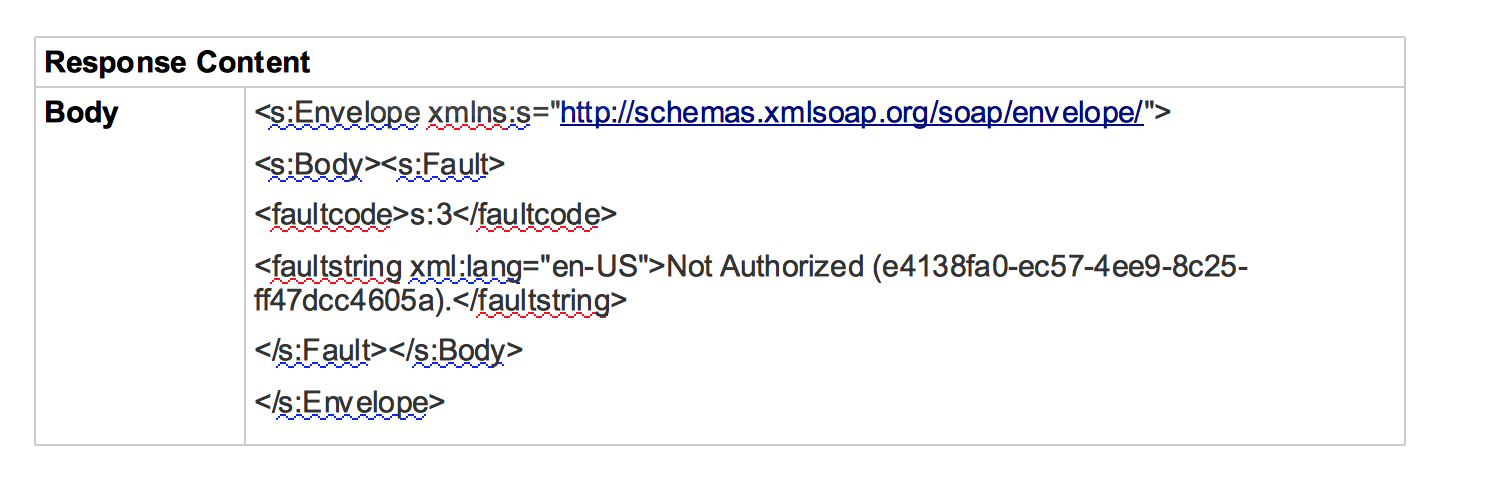
- In diesem Beispiel zeigt der Response Content, bei dem es sich um einen SOAP-Umschlag handelt, die Fehlerzeichenfolge als Meldung Nicht autorisiert. Die wahrscheinlichste Ursache dafür dass die richtigen Anmeldedaten (Nutzername/Passwort, Zugriffstoken usw.) nicht an durch den Nutzer an den Back-End-Server. Sie können dieses Problem beheben, indem Sie die richtigen Anmeldedaten an auf dem Back-End-Server.
Wenn das Back-End ein Node.js-Server ist:
- Wenn das Back-End ein Node.js-Back-End-Server ist, prüfen Sie die Node.js-Logs.
für den spezifischen API-Proxy in der Edge-Benutzeroberfläche (Nutzer von öffentlichen und privaten Clouds können
Prüfen Sie die Node.js-Logs. Wenn Sie Edge Private Cloud-Nutzer sind:
können Sie auch Ihre Message Processor-Protokolle überprüfen
(
/opt/apigee/var/log/edge-message-processor/logs/system.log) für weitere Details über den Fehler.
Option NodeJS-Protokolle in der Edge-Benutzeroberfläche - Übersichts-Tab des API-Proxys

Lösung
- Sobald Sie die Ursache des Fehlers gefunden haben, beheben Sie das Problem in Ihrem Backend-Server.
- Bei einem Node.js-Back-End-Server:
<ph type="x-smartling-placeholder">
- </ph>
- Prüfen Sie, ob der Fehler von Ihrem benutzerdefinierten Code zurückgegeben wird, und beheben Sie das Problem nach Möglichkeit.
- Wenn der Fehler nicht von Ihrem benutzerdefinierten Code zurückgegeben wird oder wenn Sie Hilfe benötigen, wenden Sie sich Apigee-Support
Wenn Sie weitere Unterstützung bei der Behebung des Fehlers „500 Internal Server Error“ benötigen oder dass es ein Problem in Edge ist, wenden Sie sich an Apigee Support.
Problemursache ermitteln
Verwenden Sie eines der folgenden Verfahren, um festzustellen, ob der Fehler 500 (Interner Serverfehler) ausgelöst wurde. während der Ausführung einer Richtlinie innerhalb des API-Proxys oder durch den Back-End-Server.
Trace in der UI verwenden
Hinweis: Die Schritte in diesem Abschnitt können sowohl vom öffentlichen als auch vom Private Cloud-Nutzer.
- Wenn das Problem weiterhin besteht, aktivieren Sie das Trace in der Benutzeroberfläche für die betroffene API.
- Nachdem Sie den Trace erfasst haben, wählen Sie die API-Anfrage aus, in der der Antwortcode als 500.
- Durch alle Phasen der fehlgeschlagenen API-Anfrage gehen und prüfen, welche Phase wiederkehrt
der Fehler 500 (Interner Serverfehler):
<ph type="x-smartling-placeholder">
- </ph>
- Wenn der Fehler beim Ausführen einer Richtlinie ausgegeben wird, fahren Sie mit Ausführungsfehler in einer Edge-Richtlinie fort.
- Wenn der Backend-Server mit 500 Interner Server geantwortet hat, fahre mit Fehler im Backend-Server fort.
API-Monitoring verwenden
Hinweis:Die Schritte in diesem Abschnitt können nur von Nutzern der öffentlichen Cloud ausgeführt werden.
Mit der API-Überwachung können Sie Problembereiche schnell isolieren, um Fehler-, Leistungs- und Latenzprobleme sowie deren Ursache zu diagnostizieren. wie z. B. Entwickler-Apps, API-Proxys, Back-End-Ziele oder die API-Plattform.
Schritt durch ein Beispielszenario, das zeigt, wie Sie 5xx-Probleme mit Ihren APIs mithilfe von API-Monitoring beheben.
Beispielsweise können Sie eine Warnung einrichten, die informiert wird, wenn die Anzahl der 500 Statuscodes oder steps.servicecallout.ExecutionFailed-Fehler einen bestimmten Schwellenwert überschreitet.
NGINX Access verwenden Protokolle
Hinweis: Die Schritte in diesem Abschnitt gelten für Edge Private Cloud-Nutzer. .
Sie können auch anhand der NGINX-Zugriffsprotokolle feststellen, ob der Statuscode 500 ausgegeben wurde. während der Ausführung einer Richtlinie innerhalb des API-Proxys oder durch den Back-End-Server. Dies ist besonders nützlich, wenn das Problem in der Vergangenheit aufgetreten ist oder zeitweise auftritt und Sie den Trace in der UI nicht erfassen können. Führen Sie die folgenden Schritte aus, um diese Informationen von NGINX-Zugriffslogs:
- Prüfen Sie die NGINX-Zugriffslogs (
/opt/apigee/var/log/edge-router/nginx/ <org>~ <env>.<port#>_access_log). - Suchen Sie nach 500-Fehlern für den spezifischen API-Proxy am Dauer
- Falls 500-Fehler vorliegen, prüfen Sie, ob es sich um einen Richtlinien- oder Zielserverfehler handelt.
wie unten dargestellt:
Beispieleintrag mit einem Richtlinienfehler
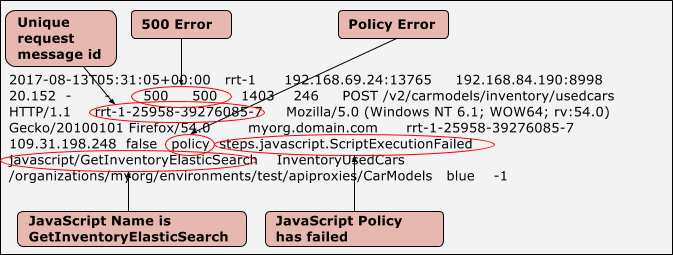
Beispieleintrag mit einem Zielserverfehler
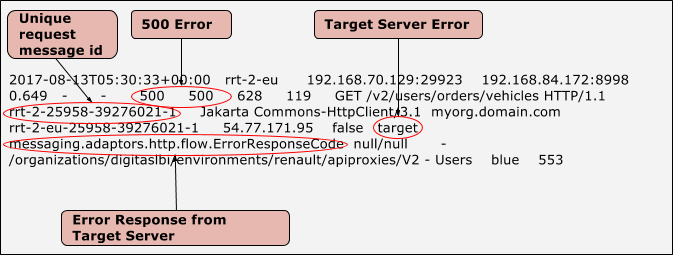
- Nachdem Sie festgestellt haben, ob es sich um einen Richtlinien- oder Zielserverfehler handelt, gehen Sie so vor:
<ph type="x-smartling-placeholder">
- </ph>
- Fahren Sie mit Ausführungsfehler in einer Edge-Richtlinie fort, wenn Es handelt sich um einen Richtlinienfehler.
- Weiter mit Fehler im Backend-Server, wenn es ein Ziel ist Serverfehler.