
<ph type="x-smartling-placeholder"></ph>
Vous consultez la documentation Apigee Edge.
Accédez à la page
Documentation sur Apigee X. En savoir plus
Vidéos
Regardez les vidéos suivantes pour en savoir plus sur la résolution de 500 erreurs de serveur internes.
| Vidéo | Description |
|---|---|
| Introduction | Présente le message 500 Erreurs internes du serveur et les causes possibles. Montre également une erreur interne du serveur 500 en temps réel, ainsi que les étapes à suivre pour dépanner et résoudre l’erreur. |
| Gérer les erreurs d'appel de service et d'extraction de variable | Cet exemple illustre deux erreurs internes 500 du serveur causées par les stratégies "Appel de service" et "Extraire une variable". et montre comment dépanner et résoudre ces erreurs. |
| Gérer les erreurs de stratégie JavaScript | Affiche une erreur interne du serveur 500 causée par une règle JavaScript et la procédure à suivre pour résoudre ce problème. |
| Gérer les échecs des serveurs backend | Affiche un exemple de 500 erreurs internes au serveur causées par une défaillance du serveur backend, ainsi que la procédure à suivre pour résoudre les erreurs. |
Symptôme
L'application cliente reçoit un code d'état HTTP de 500 avec le message Erreur interne du serveur comme réponse aux appels d'API. Le serveur interne 500 erreur peut être causée par une erreur lors de l'exécution d'une stratégie dans Edge ou par une erreur sur le serveur cible/backend.
Le code d'état HTTP 500 est une réponse d'erreur générique. Cela signifie que le serveur a rencontré une condition inattendue qui l'empêchait de répondre à la requête. Cette erreur se produit généralement renvoyé par le serveur lorsqu'aucun autre code d'erreur ne convient.
Messages d'erreur
Le message d'erreur suivant peut s'afficher:
HTTP/1.1 500 Internal Server Error
Dans certains cas, un autre message d'erreur contenant des informations plus détaillées peut s'afficher. Voici un exemple message d'erreur:
{
"fault":{
"detail":{
"errorcode":"steps.servicecallout.ExecutionFailed"
},
"faultstring":"Execution of ServiceCallout callWCSAuthServiceCallout failed. Reason: ResponseCode 400 is treated as error"
}
}Causes possibles :
L'erreur interne du serveur 500 peut être générée pour différentes causes. Dans Edge, les causes peuvent être classées dans deux catégories principales selon l'endroit où l'erreur s'est produite:
| Cause | Détails | Procédure de dépannage détaillée |
| Erreur d'exécution dans une stratégie périphérique | Une Policy dans le proxy d'API peuvent échouer pour une raison quelconque. | Utilisateurs de cloud privé et public Edge |
| Erreur sur le serveur backend | Le serveur backend peut tomber en panne pour une raison quelconque. | Utilisateurs de cloud privé et public Edge |
Erreur d'exécution dans une stratégie périphérique
Une Policy dans le proxy d'API peut échouer pour une raison quelconque. Cette section explique comment résoudre le problème l’erreur interne 500 du serveur se produit pendant l’exécution d’une stratégie.
Diagnostic
Étapes de diagnostic pour les utilisateurs de cloud privé et public
Si vous disposez de la session de trace dans l'UI pour l'erreur, procédez comme suit:
- Vérifiez que l'erreur a été causée par l'exécution d'une stratégie. Pour en savoir plus, consultez l'article Déterminer la source du problème.
- Si l'erreur s'est produite lors de l'exécution de la stratégie, continuez. Si l'erreur est causée par accédez à la section Erreur sur le serveur backend.
- Sélectionnez la requête API qui échoue avec 500 erreur interne du serveur dans la trace.
- Examinez la requête et sélectionnez la stratégie qui a échoué ou le flux nommé "Erreur" qui suit immédiatement la stratégie ayant échoué dans la trace.
- Pour en savoir plus sur l'erreur, cochez la case "Erreur". sous le champ "Propriétés" ou le contenu d'erreur.
- À l'aide des informations que vous avez collectées sur l'erreur, essayez d'en déterminer la cause.
Étapes de diagnostic pour les utilisateurs de cloud privé uniquement
Si vous ne disposez pas de la session Trace UI, procédez comme suit:
- Vérifiez que l'erreur s'est produite lors de l'exécution d'une stratégie. Pour en savoir plus, consultez l'article Déterminer la source du problème.
- Si l'erreur a été causée par l'exécution de la règle, continuez. Si l'erreur s'est produite pendant l'exécution, continuez. Si l'erreur provient du serveur backend, consultez Erreur sur le serveur backend.
- Utilisez les journaux d'accès NGINX comme expliqué dans la section Déterminer la source du problème pour déterminer la stratégie défaillante dans le proxy d'API, ainsi que la ID de message de demande unique
- Vérifier les journaux du processeur de messages
(
/opt/apigee/var/log/edge-message-processor/logs/system.log) et recherchez un identifiant de message de requête unique. - Si vous trouvez l'ID du message de demande unique, essayez d'obtenir plus d'informations sur le la cause de l'échec.
Solution
Si vous avez déterminé la cause du problème concernant les règles, essayez de le résoudre en la correction de la stratégie et le redéploiement du proxy.
Les exemples suivants montrent comment déterminer la cause et la résolution de différentes types de problèmes.
Si vous avez besoin d'une aide supplémentaire pour résoudre une erreur 500 (Erreur interne du serveur) ou qu'il s'agit d'un problème dans Edge, contactez Apigee Assistance.
Exemple 1: Échec de la règle d'appel de service en raison d'une erreur dans le backend serveur
Si l'appel au serveur backend échoue dans le cadre de la règle d'appel de service avec une erreur telle que comme 4XX ou 5XX, il est traité comme une erreur de serveur interne 500.
- Voici un exemple de défaillance du service de backend avec une erreur 404 dans l'objet
Règle concernant les appels. Le message d'erreur suivant est envoyé à l'utilisateur final:
{ "fault": { "detail": { "errorcode":"steps.servicecallout.ExecutionFailed" },"faultstring":"Execution of ServiceCallout service_callout_v3_store_by_lat_lon failed. Reason: ResponseCode 404 is treated as error" } } } - La session d'UI de trace suivante affiche le code d'état 500 causé par une erreur dans le service
Règle concernant les appels:
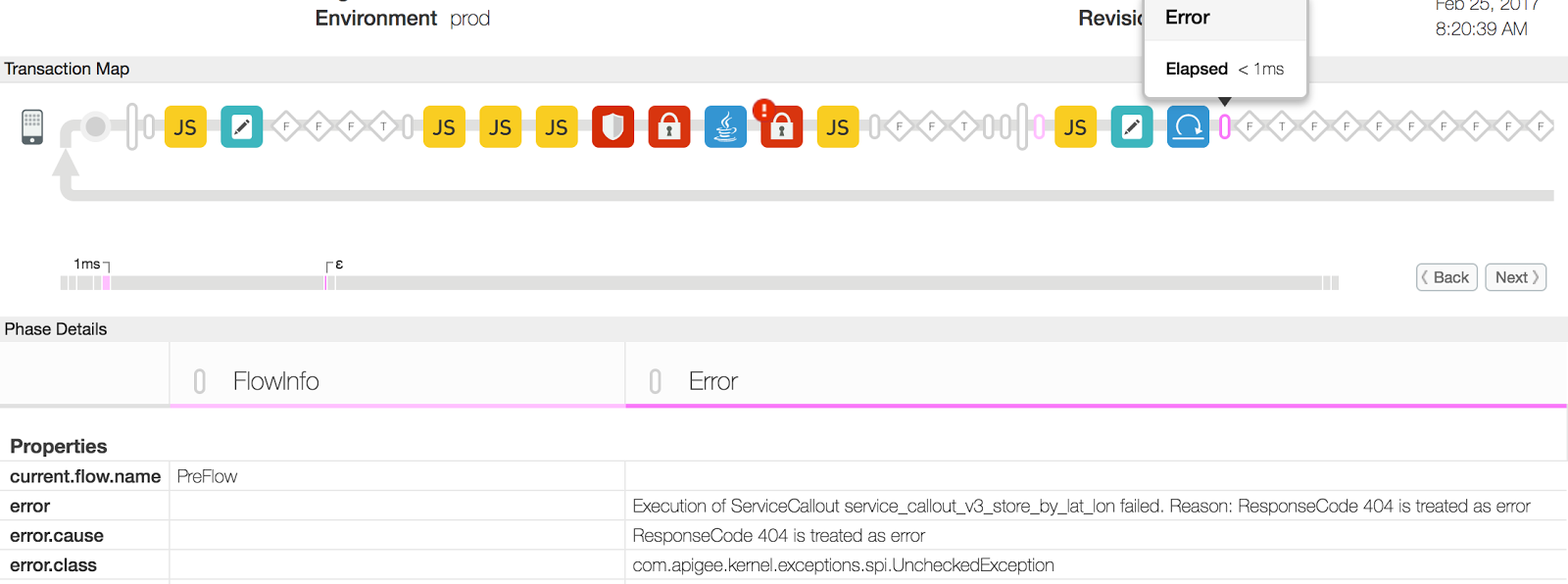
- Dans cet exemple, le texte "erreur" indique le motif de la règle "Appel de service" d'erreur de la manière suivante : "ResponseCode 404 is supported as error". Cette erreur peut se produire si la ressource accessible via l'URL du serveur backend dans la stratégie d'appel de service n'est pas disponibles.
- Vérifiez la disponibilité de la ressource sur le serveur backend. Il se peut qu'elle ne soit pas disponible temporairement/définitivement, ou il peut avoir été déplacé vers un autre emplacement.
Résolution de l'exemple 1
- Vérifiez la disponibilité de la ressource sur le serveur backend. Il se peut qu'elle ne soit pas disponible temporairement/définitivement, ou il peut avoir été déplacé vers un autre emplacement.
- Corrigez l'URL du serveur backend dans la règle d'appel de service pour qu'elle pointe vers une URL valide et existante ressource.
- Si la ressource n'est que temporairement indisponible, essayez d'envoyer la requête API une fois que le ressource est disponible.
Exemple 2: Échec de la règle d'extraction de variables
Examinons maintenant un autre exemple dans lequel l'erreur interne du serveur 500 est causée par une erreur. dans la stratégie Extract Variables et voir comment dépanner et résoudre le problème.
- La trace suivante dans la session d'UI affiche le code d'état 500 en raison d'une erreur dans l'extraction
Règle des variables:
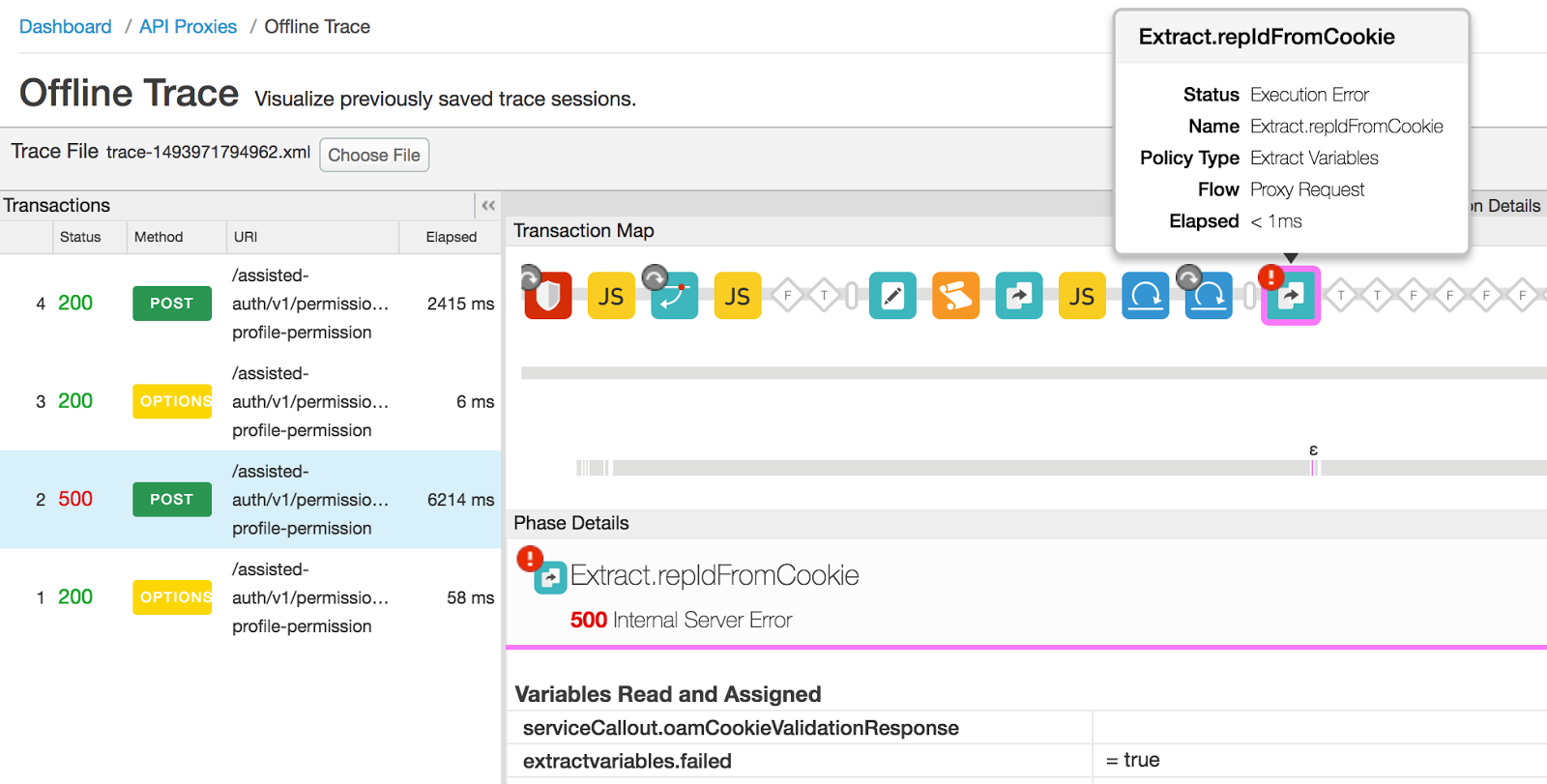
- Sélectionnez la stratégie d'extraction de variables défaillante, faites défiler vers le bas et regardez le message "Erreur
"Contenus" pour en savoir plus:

- Le contenu d'erreur indique que la variable "serviceCallout.oamCookieValidationResponse" n'est pas disponible dans la règle Extract Variables. Comme son nom l'indique, la variable doit contenir la variable de la stratégie d'appel de service précédente.
- Sélectionnez la règle d'appel de service dans la trace. Vous constaterez peut-être que "serviceCallout.oamCookieValidationResponse" n'a pas été définie. Ce indique que l'appel au service de backend a échoué, entraînant une réponse vide. .
- Bien que la règle d'appel de service échoue, leur exécution après l'exécution de la règle
La règle d'accroche continue, car "continueOnError" dans la règle "Appel de service" est défini
sur "true", comme indiqué ci-dessous:
<ServiceCallout async="false" continueOnError="true" enabled="true" name="Callout.OamCookieValidation"> <DisplayName>Callout.OamCookieValidation</DisplayName> <Properties /> <Request clearPayload="true" variable="serviceCallout.oamCookieValidationRequest"> <IgnoreUnresolvedVariables>false</IgnoreUnresolvedVariables> </Request> <Response>serviceCallout.oamCookieValidationResponse</Response> <HTTPTargetConnection> <Properties /> <URL>http://{Url}</URL> </HTTPTargetConnection> </ServiceCallout>
- Notez l'identifiant de message unique "X-Apigee.Message-ID" pour cette API spécifique.
à partir de la trace, comme suit:
<ph type="x-smartling-placeholder">
- </ph>
- Sélectionnez "Analytics Data Recorded" (Données Analytics enregistrées). de la demande.
- Faites défiler vers le bas et notez la valeur de X-Apigee.Message-ID.
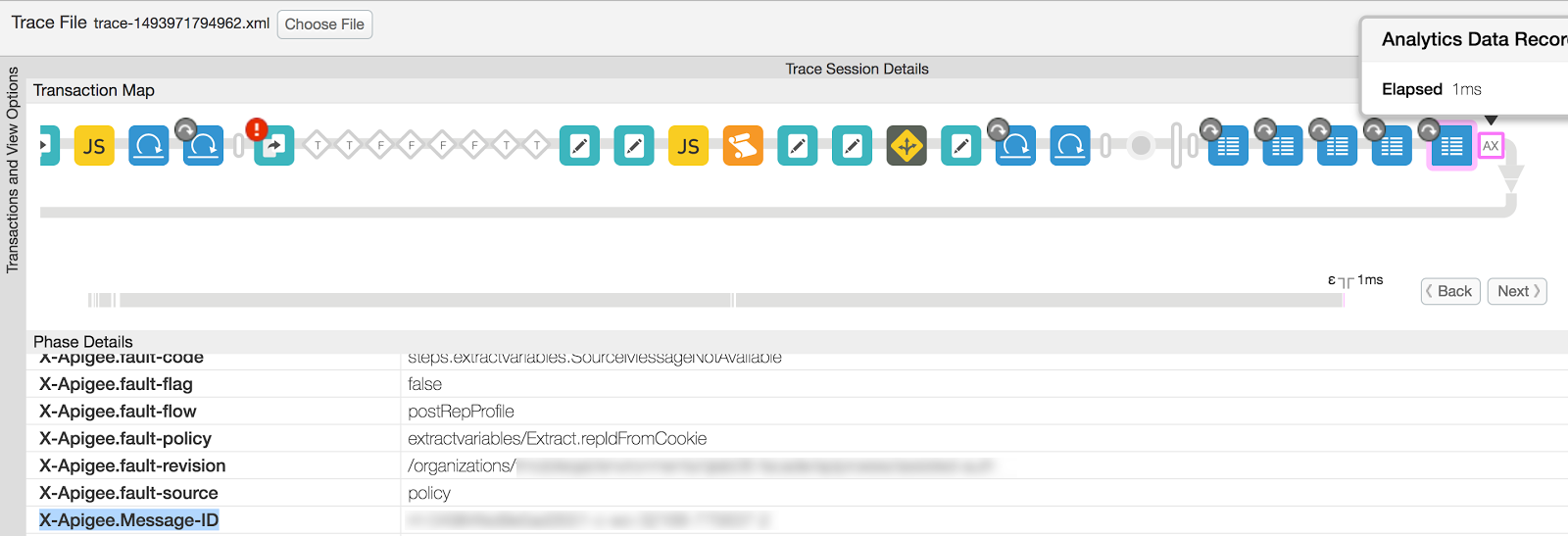
- Afficher le journal du processeur de messages
(
/opt/apigee/var/log/edge-message-processor/system.log), puis recherchez l'unique que vous avez noté à l'étape 6. Le message d'erreur suivant a été observé pour l'API spécifique requête:2017-05-05 07:48:18,653 org:myorg env:prod api:myapi rev:834 messageid:rrt-04984fed9e5ad3551-c-wo-32168-77563 NIOThread@5 ERROR HTTP.CLIENT - HTTPClient$Context.onTimeout() : ClientChannel[C:]@149081 useCount=1 bytesRead=0 bytesWritten=0 age=3002ms lastIO=3002ms .onConnectTimeout connectAddress=mybackend.domain.com/XX.XX.XX.XX:443 resolvedAddress=mybackend.domain.com/XX.XX.XX.XX
L'erreur ci-dessus indique que la règle d'appel de service a échoué en raison d'une connexion de délai avant expiration lors de la connexion au serveur backend.
- Pour déterminer la cause de l'erreur d'expiration du délai de connexion, exécutez la commande
telnet au serveur backend à partir du ou des processeurs de messages. Le Telnet
a donné "Connection timed out" (Expiration de la connexion) comme indiqué ci-dessous:
telnet mybackend.domain.com 443 Trying XX.XX.XX.XX... telnet: connect to address XX.XX.XX.XX: Connection timed out
En règle générale, cette erreur se produit dans les cas suivants:
- Lorsque le serveur backend n'est pas configuré pour autoriser le trafic provenant du message Edge Processeurs.
- Si le serveur backend n'écoute pas sur le port spécifique
Dans l'exemple illustré ci-dessus, même si la stratégie Extract Variables a échoué, cause était que Edge n'était pas en mesure de se connecter au serveur backend dans l'appel de service . La cause de cet échec était que le serveur final backend n'était pas configuré pour autoriser le trafic provenant des processeurs de messages périphériques.
Votre propre règle d'extraction de variables se comportera différemment et pourra échouer pour une autre ou motif. Vous pouvez résoudre le problème de manière appropriée, en fonction de la cause de l'échec de votre stratégie Extract Variables en vérifiant le message dans l'error .
Résolution de l'exemple 2
- Corrigez la cause de l'erreur ou de l'échec dans la règle Extraire les variables de manière appropriée.
- Dans l'exemple illustré ci-dessus, la solution consistait à rectifier la configuration réseau autoriser le trafic des processeurs de messages Edge vers votre serveur backend. Cela a été fait par à la liste d'autorisation des processeurs de messages sur le serveur backend spécifique. Par exemple : Sous Linux, vous pouvez utiliser iptables pour autoriser le trafic provenant Adresses IP du processeur de messages sur le serveur backend.
Exemple 3: Échec de la règle JavaAccroche
Étudions maintenant un autre exemple dans lequel l'erreur interne du serveur 500 est causée par une erreur. dans la stratégie d'appel de Java, et découvrez comment dépanner et résoudre le problème.
- La trace d'interface utilisateur suivante affiche le code d'état 500 en raison d'une erreur dans la stratégie d'appel Java:
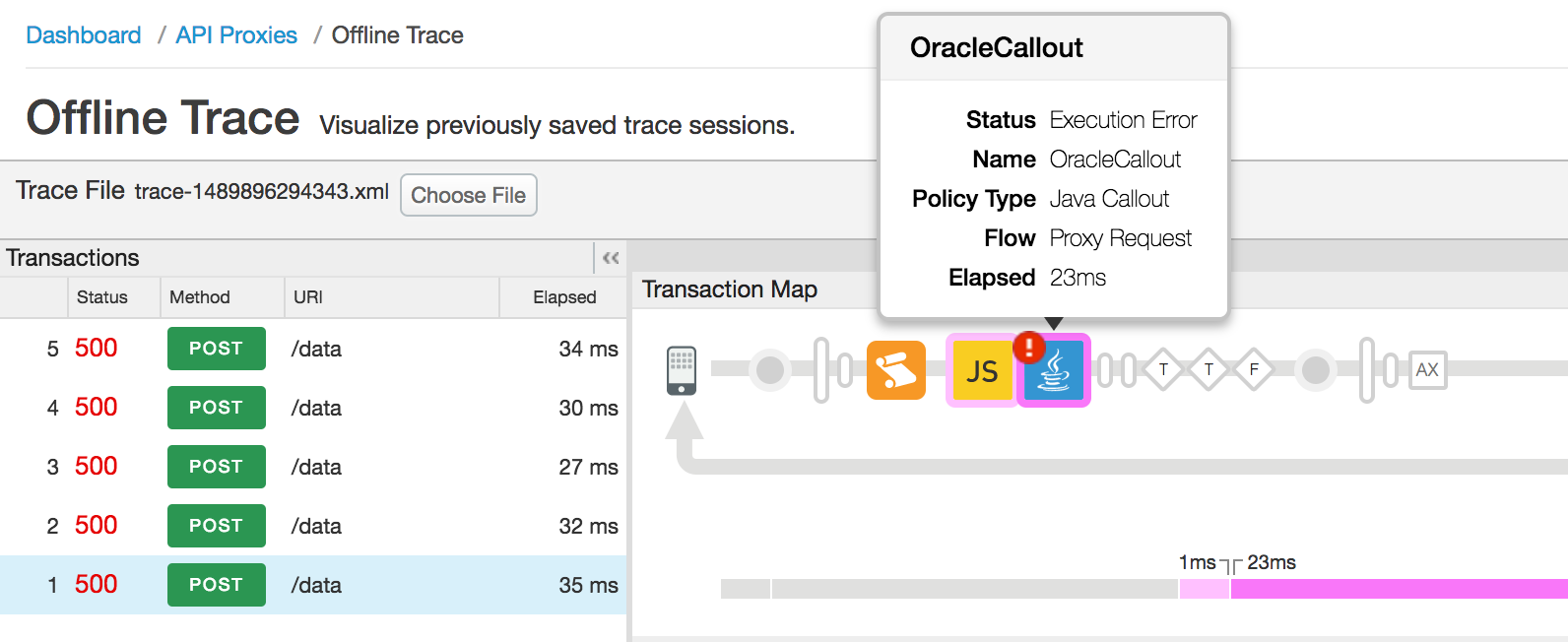
- Sélectionnez le flux nommé "Error", suivi de la stratégie d'appel Java ayant échoué.
pour obtenir les détails de l'erreur, comme illustré dans la figure ci-dessous:
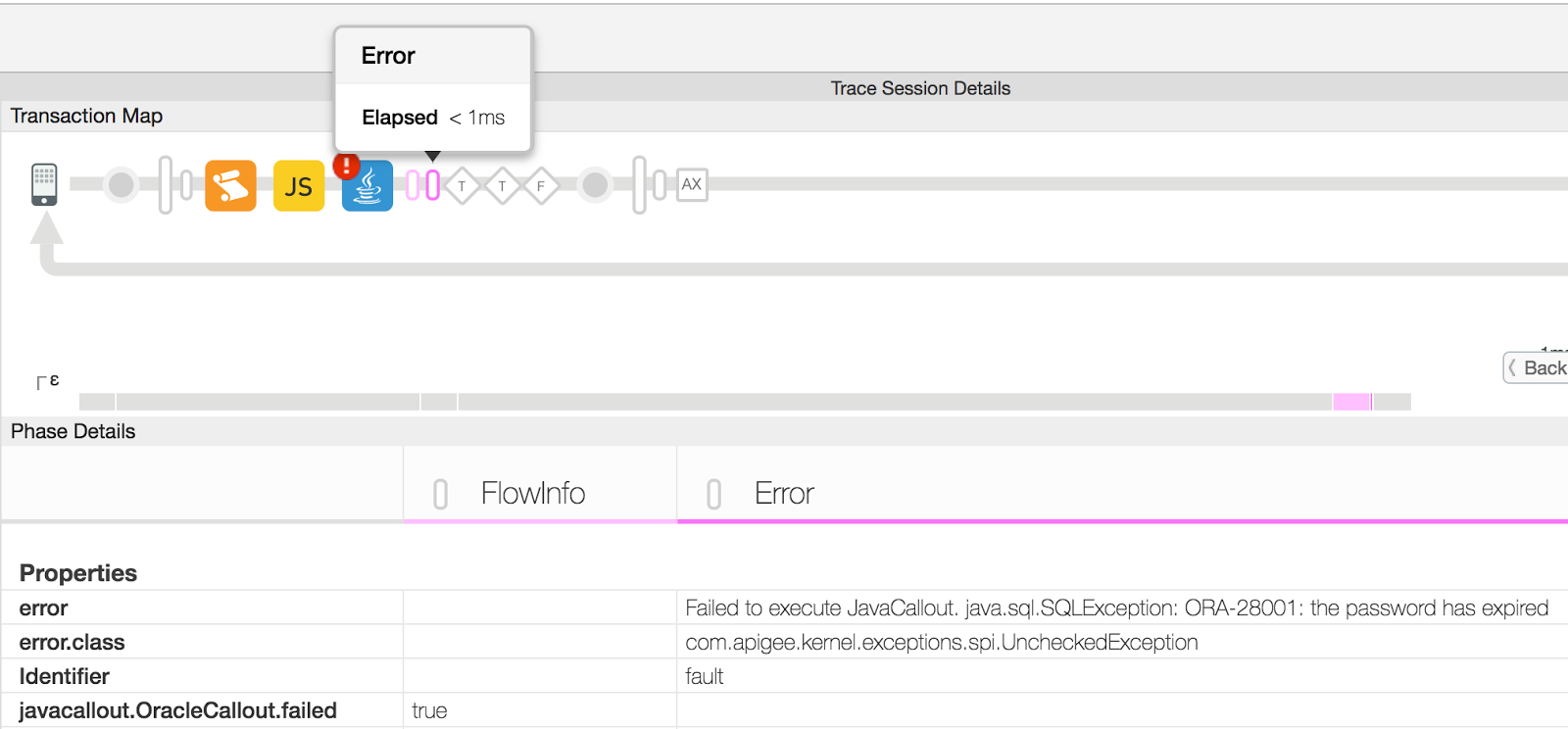
- Dans cet exemple, la propriété "error" de la section "Propriétés" indique que l'échec est dû à l'expiration du mot de passe utilisé lors de la connexion à la base de données Oracle. à partir de la règle JavaAccroche. Votre propre accroche Java se comportera différemment et remplissez un message différent dans la propriété error.
- Vérifiez le code de la règle JavaAccroche et confirmez la configuration qui doit être utilisé.
Résolution de l'exemple 3
Corrigez le code d'accroche ou la configuration Java de manière appropriée pour éviter l'exception d'exécution. Dans l'exemple d'échec de l'appel Java ci-dessus, il faudrait utiliser le bon mot de passe pour vous connecter à la base de données Oracle afin de résoudre le problème.
Erreur sur le serveur backend
Une erreur interne 500 du serveur peut également provenir du serveur backend. Cette section explique comment résoudre le problème si l'erreur provient du serveur backend.
Diagnostic
Étapes de diagnostic pour tous les utilisateurs
La cause d'autres erreurs de backend peut varier considérablement. Vous devrez diagnostiquer chaque situation indépendamment les unes des autres.
- Vérifiez que l'erreur provient bien du serveur backend. Pour en savoir plus, consultez l'article Déterminer la source du problème.
- Si l'erreur provient du serveur backend, continuez. Si l'erreur s'est produite pendant exécution de la stratégie, accédez à Erreur d'exécution en périphérie Règlement.
- Suivez les étapes ci-dessous selon que vous avez ou non accès à une session Trace pour l'API défaillante ou si le backend est un serveur Node.js:
Si aucune session Trace n'est associée à l'appel d'API ayant échoué:
- Si la trace de l'interface utilisateur n'est pas disponible pour la requête ayant échoué, vérifiez le serveur backend. les journaux pour obtenir des détails sur l'erreur.
- Si possible, activez le mode débogage sur le serveur backend pour obtenir plus d'informations et sa cause.
Si vous avez une session Trace pour l'appel d'API ayant échoué:
Si vous avez une session Trace, les étapes suivantes vous aideront à diagnostiquer le problème.
- Dans l'outil Trace, sélectionnez la requête API qui a échoué avec l'erreur "500 Internal Server" Erreur.
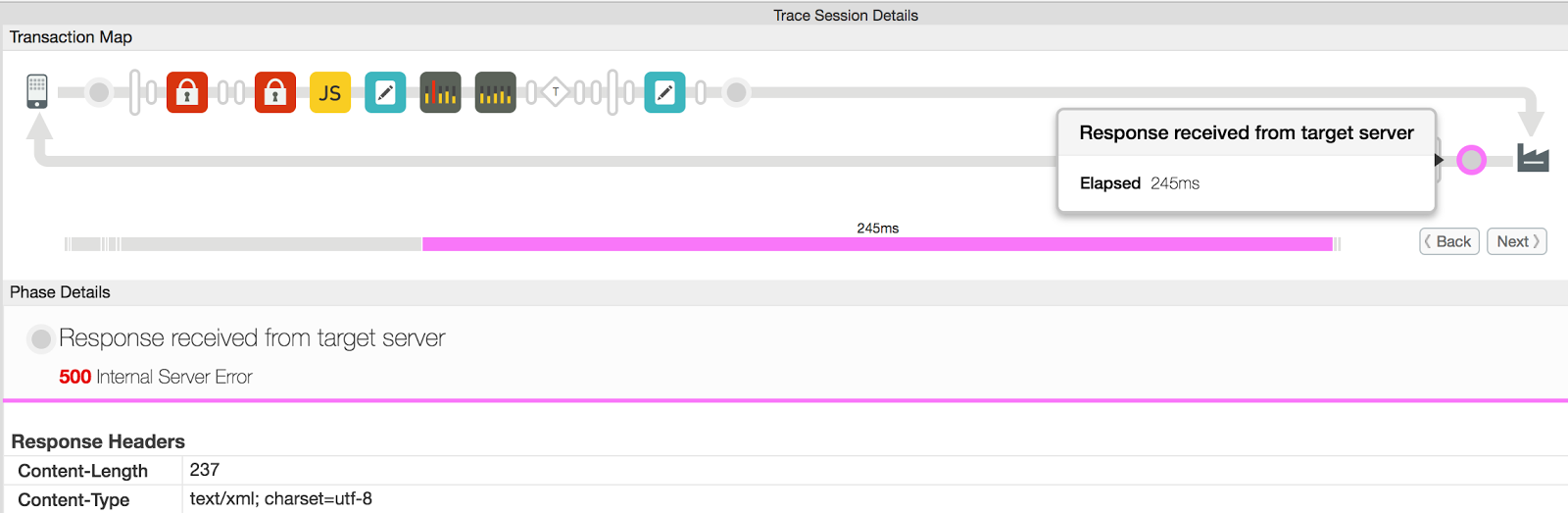
- Sélectionnez la phase Response received from target server (Réponse reçue du serveur cible) pour l'instance défaillante
API, comme illustré dans la figure ci-dessous:
- Consultez la section Response Content (Contenu de la réponse) pour obtenir des informations sur l'erreur.
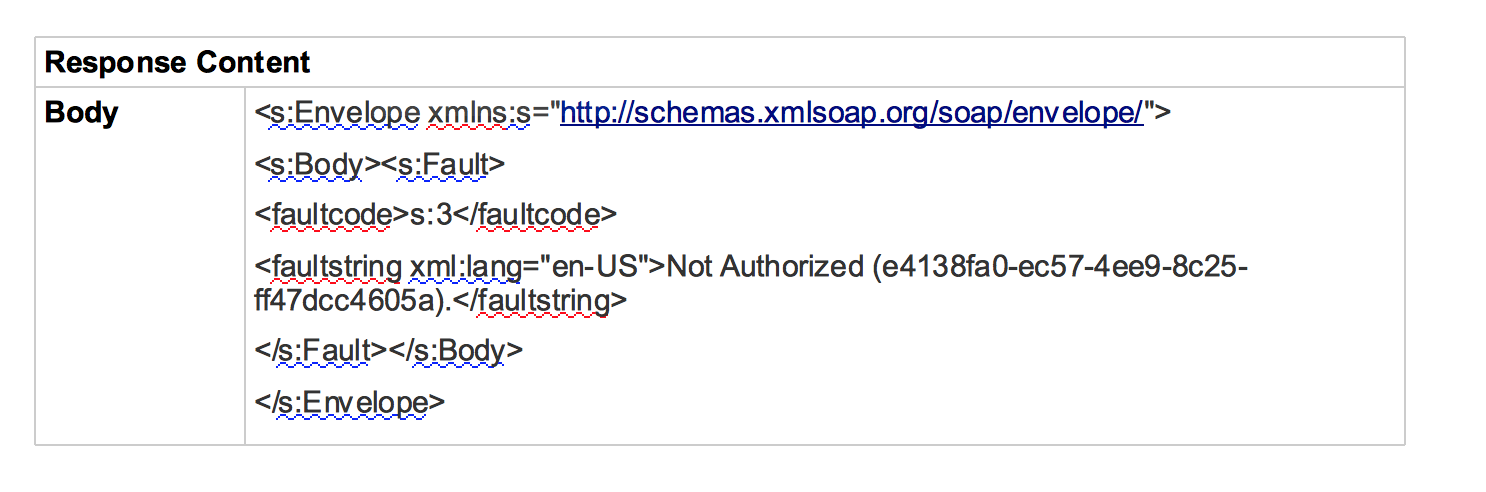
- Dans cet exemple, le contenu de la réponse qui est une enveloppe SOAP affiche la chaîne d'erreur comme suit : "Non autorisé". Quelle est la cause la plus probable les identifiants appropriés (nom d'utilisateur/mot de passe, jeton d'accès, etc.) ne sont pas transmis à vers le serveur backend par l'utilisateur. Vous pouvez résoudre ce problème en transmettant les bons identifiants à le serveur backend.
Si le backend est un serveur Node.js:
- Si le backend est un serveur backend Node.js, vérifiez les journaux Node.js.
pour le proxy d'API spécifique dans l'interface utilisateur Edge (les utilisateurs de cloud public et privé peuvent
consultez les journaux Node.js). Si vous êtes un utilisateur du cloud privé Edge, vous
peut également consulter les journaux de votre processeur de messages
(
/opt/apigee/var/log/edge-message-processor/logs/system.log) pour en savoir plus concernant l'erreur.
Option "Journaux NodeJS" dans l'interface utilisateur Edge : onglet "Aperçu" du proxy d'API

Solution
- Une fois la cause de l'erreur identifiée, corrigez-la sur votre serveur backend.
- S'il s'agit d'un serveur backend Node.js:
<ph type="x-smartling-placeholder">
- </ph>
- Vérifiez si l'erreur est générée par votre code personnalisé et corrigez le problème, si possible.
- Si l'erreur n'est pas générée par votre code personnalisé ou si vous avez besoin d'aide, contactez Assistance Apigee
Si vous avez besoin d'une aide supplémentaire pour résoudre une erreur 500 (Erreur interne du serveur) ou qu'il s'agit d'un problème dans Edge, contactez Apigee Assistance.
Déterminer la source du problème
Utilisez l'une des procédures suivantes pour déterminer si l'erreur interne du serveur 500 a été générée lors de l'exécution d'une stratégie dans le proxy d'API ou par le serveur backend.
Utiliser Trace dans l'UI
Remarque:Les étapes de cette section peuvent être effectuées par des administrateurs les utilisateurs de cloud privé.
- Si le problème est toujours actif, activez la trace dans l'UI pour l'API concernée.
- Une fois la trace capturée, sélectionnez la requête API qui affiche le code de réponse sous la forme 500.
- Parcourez toutes les phases de la requête API en échec et vérifiez quelle phase renvoie
l'erreur interne 500 du serveur:
<ph type="x-smartling-placeholder">
- </ph>
- Si l'erreur est générée lors de l'exécution d'une stratégie, passez à la section Erreur d'exécution dans une stratégie périphérique.
- Si le serveur backend a répondu "500 serveur interne", passez à la section Erreur sur le serveur backend.
Utiliser la surveillance des API
Remarque:Les étapes de cette section ne peuvent être effectuées que par des utilisateurs de cloud public.
La surveillance des API vous permet d'isoler rapidement les zones problématiques pour diagnostiquer les problèmes d'erreur, de performances, de latence et leur source, telles que les applications de développement, les mandataires d'API, les cibles de backend ou la plate-forme d'API.
Passez en revue un exemple de scénario qui montre comment résoudre les problèmes 5xx avec vos API à l'aide de l'API Monitoring.
Par exemple, vous pouvez configurer une alerte pour être averti lorsque le nombre de codes d'état 500 ou d'erreurs steps.servicecallout.ExecutionFailed dépasse un seuil particulier.
Utiliser l'accès NGINX Journaux
Remarque:Les étapes de cette section s'appliquent aux utilisateurs de cloud privé Edge uniquement.
Vous pouvez également consulter les journaux d'accès NGINX pour déterminer si le code d'état 500 a été généré. lors de l'exécution d'une stratégie dans le proxy d'API ou par le serveur backend. C'est particulièrement utile si le problème s'est produit par le passé ou s'il se produit par intermittence et que vous ne peuvent pas capturer la trace dans l'UI. Procédez comme suit pour déterminer ces informations Journaux d'accès NGINX:
- Vérifiez les journaux d'accès NGINX (
/opt/apigee/var/log/edge-router/nginx/ <org>~ <env>.<port#>_access_log). - Recherchez s'il existe des erreurs 500 pour le proxy d'API spécifique au niveau de la vidéo.
- S'il existe des erreurs 500, vérifiez s'il s'agit d'une erreur liée aux règles ou au serveur cible.
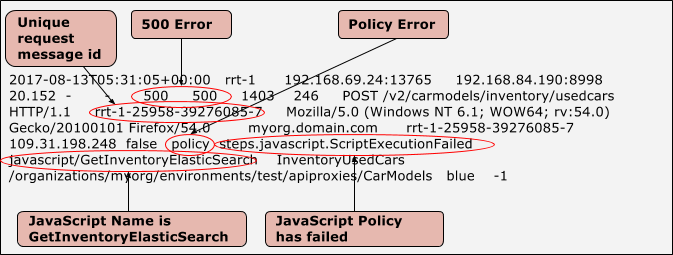
comme indiqué ci-dessous:
Exemple d'entrée montrant une erreur de stratégie
Exemple d'entrée montrant une erreur du serveur cible
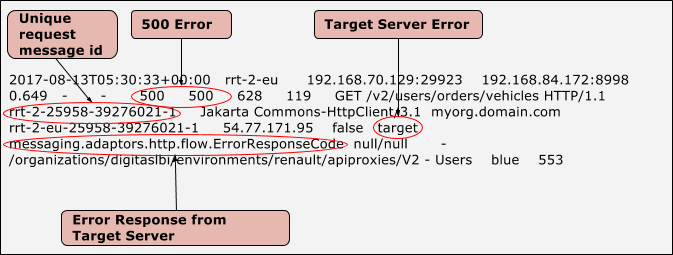
- Une fois que vous avez déterminé s'il s'agit d'une erreur liée aux règles ou au serveur cible:
<ph type="x-smartling-placeholder">
- </ph>
- Passez à la section Erreur d'exécution dans une stratégie périphérique si il s'agit d'une erreur de stratégie.
- Passez à la section Erreur sur le serveur backend s'il s'agit d'une cible. erreur du serveur.