
<ph type="x-smartling-placeholder"></ph>
Vous consultez la documentation Apigee Edge.
Accédez à la page
Documentation sur Apigee X. En savoir plus
Symptôme
L'application cliente reçoit l'état de réponse HTTP 503 avec le message
Service Unavailable après un appel de proxy d'API.
Message d'erreur
L'application cliente reçoit le code de réponse suivant:
HTTP/1.1 503 Service Unavailable
Le message d'erreur suivant peut également s'afficher:
{
"fault": {
"faultstring": "The Service is temporarily unavailable",
"detail": {
"errorcode": "messaging.adaptors.http.flow.ServiceUnavailable"
}
}
}Causes possibles :
| Cause | Description | Instructions de dépannage applicables |
|---|---|---|
| Le serveur cible ferme prématurément la connexion | Le serveur cible met fin prématurément à la connexion pendant que le processeur de messages est toujours l'envoi de la charge utile de la requête. | Utilisateurs Edge de cloud public et privé |
Étapes de diagnostic courantes
Déterminer l'ID de message de la requête en échec
Outil Trace
Pour déterminer l'ID du message de la requête ayant échoué à l'aide de l'outil Trace:
- Si le problème persiste, activez le session Trace pour l'API concernée.
- Effectuez l'appel d'API et reproduisez le problème :
503 Service Unavailableavec le code d'erreurmessaging.adaptors.http.flow.ServiceUnavailable. - Sélectionnez l'une des requêtes ayant échoué.
- Accédez à la phase AX et déterminez l'ID du message.
(
X-Apigee.Message-ID) de la requête en faisant défiler l'écran vers le bas dans Phase Details (Détails de la phase) comme illustré dans la figure suivante.
Journaux d'accès NGINX
Pour déterminer l'ID du message de la requête ayant échoué à l'aide des journaux d'accès NGINX:
Vous pouvez également consulter les journaux d'accès NGINX pour déterminer l'ID de message pour les erreurs 503.
Cela est particulièrement utile si le problème s'est produit par le passé ou s'il se produit par intermittence.
et vous ne parvenez pas à capturer la trace dans l'UI. Procédez comme suit pour obtenir ces informations à partir des journaux d'accès NGINX:
- Vérifiez les journaux d'accès NGINX: (
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - Recherchez s'il existe des erreurs
503pour le proxy d'API spécifique pendant une durée spécifique (si le problème s'est produit auparavant) ou si des requêtes échouent toujours avec503. - En cas d'erreurs
503avec X-Apigee-fault-code messages.adaptors.http.flow.ServiceUnavailable, notez l'ID du message pour une ou plusieurs de ces requêtes, comme illustré dans l'exemple suivant:Exemple d'entrée affichant l'erreur
503
Cause: le serveur cible ferme prématurément la connexion
Diagnostic
- Si vous êtes un utilisateur de cloud public ou de cloud privé:
<ph type="x-smartling-placeholder">
- </ph>
- Utilisez l'outil Trace (comme expliqué dans la section Étapes de diagnostic courantes).
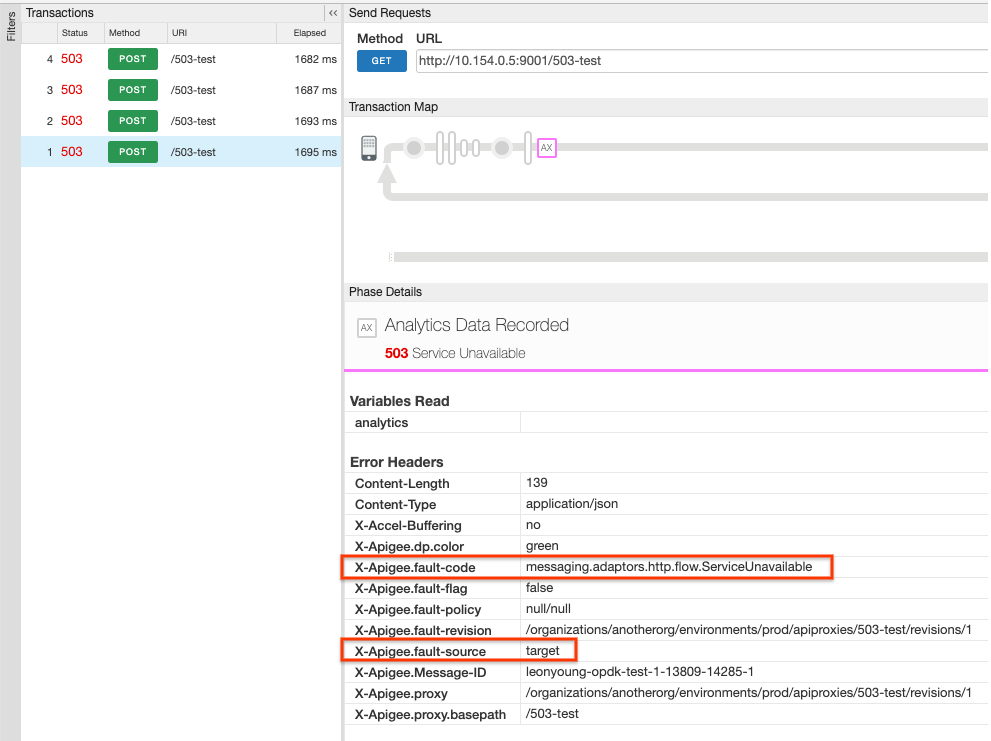
et vérifiez que les deux éléments suivants sont définis dans le volet Données analytiques enregistrées:
<ph type="x-smartling-placeholder">
- </ph>
- X-Apigee.fault-code:
messaging.adaptors.http.flow.ServiceUnavailable - X-Apigee.fault-source:
target
- X-Apigee.fault-code:
- Utilisez l'outil Trace (comme expliqué dans la section Étapes de diagnostic courantes).
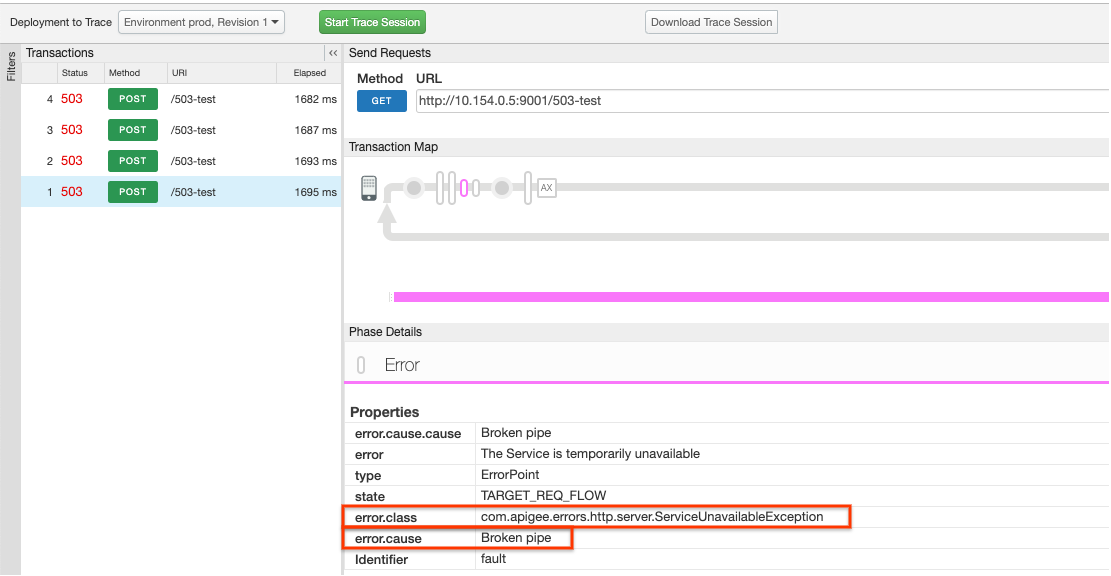
et vérifiez que les deux éléments suivants sont définis dans le volet Error (Erreur) juste après
la propriété state
TARGET_REQ_FLOW:- error.class::
com.apigee.errors.http.server.ServiceUnavailableException - error.cause::
Broken pipe
- error.class::
- Pour en savoir plus, consultez la page Utiliser tcpdump.
- Utilisez l'outil Trace (comme expliqué dans la section Étapes de diagnostic courantes).
et vérifiez que les deux éléments suivants sont définis dans le volet Données analytiques enregistrées:
<ph type="x-smartling-placeholder">
- Si vous êtes un utilisateur de Private Cloud:
<ph type="x-smartling-placeholder">
- </ph>
- <ph type="x-smartling-placeholder"></ph> Déterminez l'ID de message de la requête ayant échoué.
- Recherchez l'ID du message dans le journal du processeur de messages.
(
/opt/apigee/var/log/edge-message-processor/logs/system.log). - L'une des exceptions suivantes s'affiche:
Exception n° 1: java.io.IOException: pipe endommagée s'est produite lors de l'écriture dans le canal ClientOutputChannel
2021-01-30 15:31:14,693 org:anotherorg env:prod api:myproxy rev:1 messageid:myorg-opdk-test-1-30312-13747-1 NIOThread@1 INFO HTTP.SERVICE - ExceptionHandler.handleException() : Exception java.io.IOException: Broken pipe occurred while writing to channel ClientOutputChannel(ClientChannel[Connected: Remote:IP:PORT Local:0.0.0.0:42828]@8380 useCount=1 bytesRead=0 bytesWritten=76295 age=2012ms lastIO=2ms isOpen=false)
ou
Exception n° 2: exception onExceptionWrite: {}
java.io.IOException: Pipeline rompu2021-01-31 15:29:37,438 org:anotherorg env:prod api:503-test rev:1 messageid:leonyoung-opdk-test-1-18604-13978-1 NIOThread@0 ERROR HTTP.CLIENT - HTTPClient$Context$2.onException() : ClientChannel[Connected: Remote:IP:PORT Local:0.0.0.0:57880]@8569 useCount=1 bytesRead=0 bytesWritten=76295 age=3180ms lastIO=2 ms isOpen=false.onExceptionWrite exception: {} java.io.IOException: Broken pipe
- Ces deux exceptions indiquent que pendant que le processeur de messages écrivait encore le
vers le serveur backend, la connexion a été fermée prématurément par
à un serveur backend. Par conséquent, le processeur de messages génère l'exception
java.io.IOException: Broken pipe. Remote:IP:PORTindique le serveur backend résolu. Adresse IP et numéro de port.- L'attribut
bytesWritten=76295dans le message d'erreur ci-dessus indique que le processeur de messages avait envoyé une charge utile de76295octets au backend lorsque la connexion a été fermée prématurément. - L'attribut
bytesRead=0indique que le processeur de messages n'a pas reçu des données (réponse) du serveur backend. - Pour examiner le problème plus en détail, rassemblez un
tcpdumpsur le backend ou le processeur de messages et les analyser comme expliqué ci-dessous.
Utiliser tcpdump
-
Capturez un
tcpdumpsur le serveur backend ou le processeur de messages avec les commandes suivantes:Exécutez cette commande pour rassembler
tcpdumpsur le serveur backend:tcpdump -i any -s 0 host MP_IP_ADDRESS -w FILE_NAME
Commande permettant de rassembler
tcpdumpsur le processeur de messages:tcpdump -i any -s 0 host BACKEND_HOSTNAME -w FILE_NAME
- Analysez les
tcpdumpcapturées:Exemple de résultat de tcpdump (recueilli sur le processeur de messages):

Dans le fichier
tcpdumpci-dessus, vous pouvez voir les éléments suivants:- Dans le paquet
4, le processeur de messages a envoyé une requêtePOSTau le serveur backend. - Dans le paquet
5,8,9,10,11, le processeur de messages a continué à envoyer la charge utile de la requête au à un serveur backend. - Dans les paquets
6et7,le serveur backend a répondu avec le code suivant :ACKpour une partie de la charge utile de requête reçue du processeur de messages. - Cependant, dans le paquet
12, au lieu de répondre avec unACKpour les paquets de données d'application reçus, puis en répondant avec la réponse la charge utile, le serveur backend répond à la place par unFIN ACKinitiant le la fermeture de la connexion. - Cela montre clairement que le serveur backend ferme la connexion prématurément. alors que le processeur de messages envoyait encore la charge utile de la requête.
- Le processeur de messages enregistre alors un
IOException: Broken Pipeet renvoie une503au client
- Dans le paquet
Solution
- Collaborez avec l'une de vos équipes chargées de l'application et de la mise en réseau, ou avec les deux, pour analyser et corriger le problème les déconnexions prématurées côté serveur backend.
- Assurez-vous que l'application du serveur backend n'expire pas et ne réinitialise pas la connexion avant de recevoir l’intégralité de la charge utile de la requête.
- Si vous avez un périphérique réseau intermédiaire ou une couche entre Apigee et le serveur backend, puis assurez-vous qu'ils n'expirent pas avant que l'ensemble de la charge utile de la demande ait été reçue.
Si le problème persiste, consultez la page Vous devez collecter des informations de diagnostic.
Vous devez collecter des informations de diagnostic
Si le problème persiste alors que vous avez suivi les instructions ci-dessus, rassemblez les informations suivantes : de diagnostic, puis contactez l'assistance Apigee Edge:
Si vous êtes un utilisateur de cloud public, fournissez les informations suivantes:
- Nom de l'organisation
- Nom de l'environnement
- Nom du proxy d'API
- Exécutez la commande
curlpour reproduire l'erreur503. - Fichier de suivi contenant la requête avec l'erreur
503 Service Unavailable - Si les erreurs
503ne se produisent pas actuellement, indiquez la période avec les informations de fuseau horaire lorsque des erreurs503se sont produites dans le passé.
Si vous êtes un utilisateur du Private Cloud, fournissez les informations suivantes:
- Message d'erreur complet observé pour les requêtes en échec
- Nom de l'organisation, de l'environnement et du proxy d'API que vous observez
503erreur - Groupe de proxys d'API
- Fichier de suivi contenant les requêtes avec l'erreur
503 Service Unavailable - Journaux d'accès NGINX
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - Journaux du processeur de messages
/opt/apigee/var/log/edge-message-processor/logs/system.log - Période avec les informations de fuseau horaire au cours de laquelle les erreurs
503se sont produites Tcpdumpsse sont rassemblés sur les processeurs de messages et le serveur backend lorsque erreur