
شما در حال مشاهده اسناد Apigee Edge هستید.
به مستندات Apigee X بروید . اطلاعات
این خط مشی RaiseFault به توسعه دهندگان API اجازه می دهد یک جریان خطا را شروع کنند، متغیرهای خطا را در پیام بدنه پاسخ تنظیم کنند و کدهای وضعیت پاسخ مناسب را تنظیم کنند. همچنین می توانید از خط مشی RaiseFault برای تنظیم متغیرهای جریان مربوط به خطا استفاده کنید، مانند fault.name ، fault.type و fault.category . از آنجایی که این متغیرها در دادههای تحلیلی و گزارشهای دسترسی روتر مورد استفاده برای اشکالزدایی قابل مشاهده هستند، شناسایی دقیق عیب بسیار مهم است.
میتوانید از خطمشی RaiseFault برای برخورد با شرایط خاص بهعنوان خطا استفاده کنید، حتی اگر خطای واقعی در خطمشی دیگری یا در سرور backend پراکسی API رخ نداده باشد. به عنوان مثال، اگر میخواهید هر زمان که بدنه پاسخ پشتیبان شامل رشته unavailable ، پروکسی یک پیام خطای سفارشی را به برنامه مشتری ارسال کند، میتوانید سیاست RaiseFault را همانطور که در قطعه کد زیر نشان داده شده است فراخوانی کنید:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
نام خطمشی RaiseFault بهعنوان fault.name در API Monitoring و x_apigee_fault_policy در گزارشهای دسترسی Analytics و روتر قابل مشاهده است. این به تشخیص آسان علت خطا کمک می کند.
ضد الگو
استفاده از خط مشی RaiseFault در FaultRules پس از اینکه خط مشی دیگری قبلاً خطا ایجاد کرده است
مثال زیر را در نظر بگیرید، جایی که یک خط مشی OAuthV2 در جریان پروکسی API با خطای InvalidAccessToken شکست خورده است. در صورت شکست، Edge fault.name را به عنوان InvalidAccessToken تنظیم می کند، وارد جریان خطا می شود و هر FaultRule تعریف شده را اجرا می کند. در FaultRule، یک خط مشی RaiseFault به نام RaiseFault وجود دارد که هر زمان که خطای InvalidAccessToken رخ دهد، یک پاسخ خطای سفارشی ارسال می کند. با این حال، استفاده از خط مشی RaiseFault در یک FaultRule به این معنی است که متغیر fault.name رونویسی شده و علت واقعی شکست را پنهان می کند.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
استفاده از خط مشی RaiseFault در FaultRule تحت هر شرایطی
در مثال زیر، اگر fault.name RaiseFault نباشد، یک خط مشی RaiseFault به نام RaiseFault اجرا می شود:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
مانند سناریوی اول، متغیرهای خطای کلیدی fault.name ، fault.code و fault.policy با نام خط مشی RaiseFault رونویسی می شوند. این رفتار تقریباً غیرممکن میکند که بدون دسترسی به فایل ردیابی که خطا را نشان میدهد یا مشکل را بازتولید کند، تعیین خطمشی واقعاً باعث خرابی شده است.
استفاده از خط مشی RaiseFault برای برگرداندن پاسخ HTTP 2xx خارج از جریان خطا.
در مثال زیر، یک خط مشی RaiseFault با نام HandleOptionsRequest زمانی اجرا می شود که فعل درخواست OPTIONS باشد:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
هدف این است که بلافاصله پاسخ را بدون پردازش سایر خط مشی ها به مشتری API برگردانیم. با این حال، این منجر به دادههای تحلیلی گمراهکننده میشود، زیرا متغیرهای خطا حاوی نام خطمشی RaiseFault هستند و اشکالزدایی پراکسی را دشوارتر میکند. روش صحیح برای اجرای رفتار مورد نظر، استفاده از Flow با شرایط خاص است، همانطور که در افزودن پشتیبانی CORS توضیح داده شده است.
تاثیر
استفاده از خط مشی RaiseFault همانطور که در بالا توضیح داده شد منجر به بازنویسی متغیرهای خطای کلیدی با نام خط مشی RaiseFault به جای نام خط مشی خراب می شود. در گزارشهای Analytics و NGINX Access، x_apigee_fault_code و x_apigee_fault_policy متغیرها بازنویسی می شوند. در مانیتورینگ API ، Fault Code و Fault Policy رونویسی میشوند. این رفتار عیب یابی و تعیین اینکه کدام خط مشی علت واقعی شکست است را دشوار می کند.
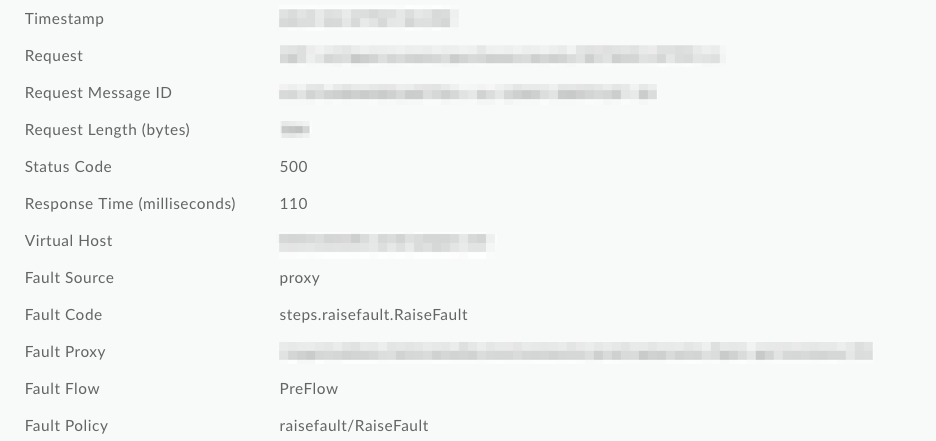
در تصویر زیر از API Monitoring ، میتوانید ببینید که کد خطا و خطمشی خطا روی مقادیر عمومی RaiseFault بازنویسی شدهاند، که تعیین علت اصلی خرابی را از لاگها غیرممکن میکند:
بهترین تمرین
هنگامی که خط مشی Edge یک خطا را ایجاد می کند و می خواهید پیام پاسخ خطا را سفارشی کنید، به جای خط مشی RaiseFault از خط مشی های AssignMessage یا JavaScript استفاده کنید.
خط مشی RaiseFault باید در یک جریان بدون خطا استفاده شود. یعنی فقط از RaiseFault استفاده کنید تا یک وضعیت خاص را به عنوان یک خطا در نظر بگیرید، حتی اگر یک خطای واقعی در یک خط مشی یا در سرور باطن پروکسی API رخ نداده باشد. برای مثال، میتوانید از خطمشی RaiseFault برای نشان دادن اینکه پارامترهای ورودی اجباری گم شدهاند یا نحو نادرستی دارند استفاده کنید.
همچنین میتوانید از RaiseFault در قانون خطا استفاده کنید، اگر میخواهید خطا را در طول پردازش یک خطا تشخیص دهید. به عنوان مثال، کنترل کننده خطا خود می تواند خطایی ایجاد کند که می خواهید با استفاده از RaiseFault آن را علامت بزنید.