
מוצג המסמך של Apigee Edge.
עוברים אל
מסמכי תיעוד של Apigee X. מידע
תיאור הבעיה
אפליקציית הלקוח מקבלת שגיאה של זמן קצוב לתפוגה עבור בקשות API או שהבקשה מסתיימת בפתאומיות בזמן שבקשת ה-API עדיין מתבצעת ב-Apigee.
קוד הסטטוס 499 יופיע עבור בקשות API כאלה ב-API Monitoring, וגם
יומני NGINX Access. לפעמים תראו קודי סטטוס שונים ב-API Analytics, מאחר
מציגה את קוד הסטטוס שהוחזר על ידי מעבד ההודעות.
הודעת שגיאה
אפליקציות לקוח עשויות לראות שגיאות כמו:
curl: (28) Operation timed out after 6001 milliseconds with 0 out of -1 bytes received
מה גורם לתפוגת זמן קצוב של לקוח?
הנתיב הטיפוסי לבקשת API בפלטפורמת Edge הוא לקוח > נתב > מעבד הודעות > שרת עורפי כפי שמוצג באיור הבא:
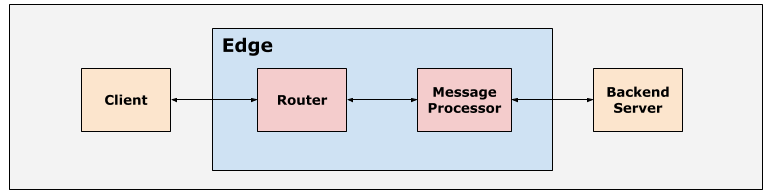
הנתבים ומעבדי ההודעות בפלטפורמת Apigee Edge מוגדרים עם בערכי ברירת המחדל של הזמן הקצוב לתפוגה, כדי להבטיח שההשלמה של בקשות ה-API לא תימשך יותר מדי זמן.
זמן קצוב לתפוגה אצל לקוח
אפשר להגדיר לאפליקציות לקוח ערך מתאים של זמן קצוב לתפוגה בהתאם לצרכים שלכם.
למערכת ההפעלה יש לקוחות כמו דפדפני אינטרנט ואפליקציות לנייד עם זמנים קצובים לתפוגה.
הזמן הקצוב לתפוגה בנתב
הזמן הקצוב לתפוגה שמוגדר כברירת מחדל בנתבים הוא 57 שניות. זהו משך הזמן המקסימלי שרת ה-proxy ל-API יכול לפעול מהרגע שבו בקשת ה-API התקבלה ב-Edge ועד שהתגובה נשלח בחזרה, כולל התגובה לקצה העורפי וכל כללי המדיניות שמופעלים. ברירת המחדל ניתן לבטל את הזמן הקצוב לתפוגה בנתבים ובמארחים הווירטואליים, כפי שמוסבר ב הגדרת זמן קצוב לתפוגה של קלט/פלט בנתבים.
זמן קצוב לתפוגה של מעבדי הודעות
הזמן הקצוב לתפוגה שמוגדר כברירת מחדל במעבדי הודעות הוא 55 שניות. זהו הסכום המקסימלי הזמן שנדרש לשרת הקצה העורפי לעבד את הבקשה ולהגיב להודעה מעבד. אפשר לבטל את הזמן הקצוב לתפוגה שהוגדר כברירת מחדל במעבדי ההודעות או בתוך ה-API. שרת proxy, כפי שמוסבר ב הגדרת זמן קצוב לתפוגה של קלט/פלט במעבדי הודעות.
אם הלקוח סוגר את החיבור לנתב לפני שפג הזמן הקצוב של שרת ה-proxy ל-API,
יבחינו בשגיאת הזמן הקצוב לתפוגה של בקשת ה-API הספציפית. קוד הסטטוס 499 Client
Closed Connection נרשם בנתב עבור בקשות כאלה, שניתן לראות ב-API.
יומני Monitoring ו-NGINX Access.
סיבות אפשריות
ב-Edge, הסיבות הטיפוסיות לשגיאה 499 Client Closed Connection הן:
| סיבה | תיאור | הוראות לפתרון בעיות עבור |
|---|---|---|
| הלקוח סגר בפתאומיות את החיבור | הדבר קורה כאשר הלקוח סוגר את החיבור עקב משתמש הקצה ביטול לפני שתשלימו את התהליך. | משתמשים בענן פרטי וציבורי |
| הזמן הקצוב לתפוגה של אפליקציית לקוח | זה קורה כשפג הזמן הקצוב לאפליקציית הלקוח לפני של-Proxy ל-API יש זמן לעבד ולשלוח את התשובה. בדרך כלל זה קורה כשהזמן הקצוב לתפוגה של הלקוח קצר יותר מהזמן הקצוב לתפוגה של הנתב. | משתמשים בענן פרטי וציבורי |
שלבי אבחון נפוצים
יש להשתמש באחד מהכלים או השיטות הבאים כדי לאבחן את השגיאה:
- מעקב API
- יומני גישה ל-NGINX
מעקב API
כדי לאבחן את השגיאה באמצעות API Monitoring:
- מנווטים אל ניתוח > מעקב API > לחקור את הדף.
- מסננים לאיתור
4xxשגיאות ובוחרים את מסגרת הזמן. - הציגו קוד סטטוס לצד זמן.
- יש לבחור תא שמכיל
499שגיאות כפי שמוצג בהמשך: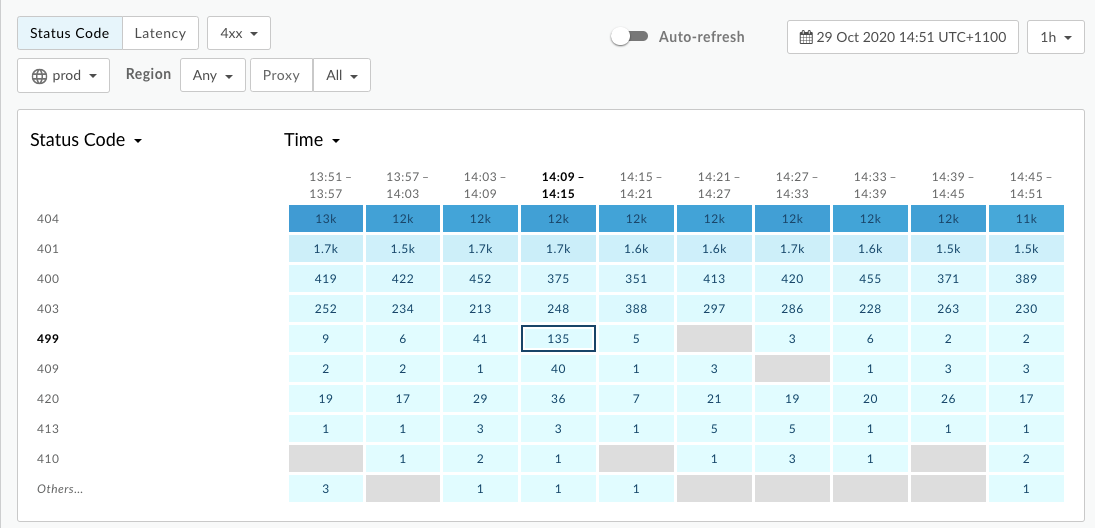
- המידע על השגיאה
499יופיע בחלונית השמאלית כך: מוצגת למטה: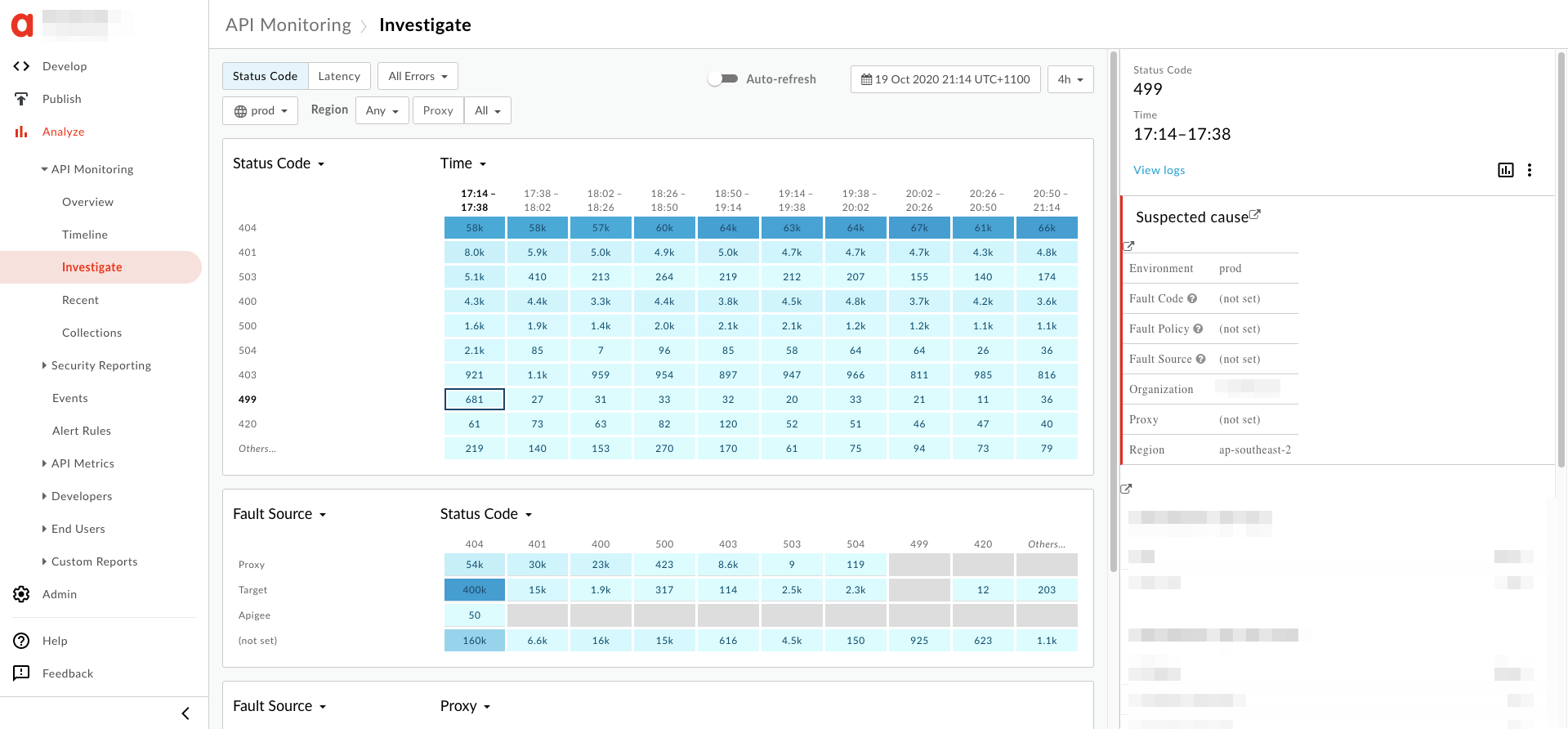
- בחלונית שמשמאל, לוחצים על View Logs.
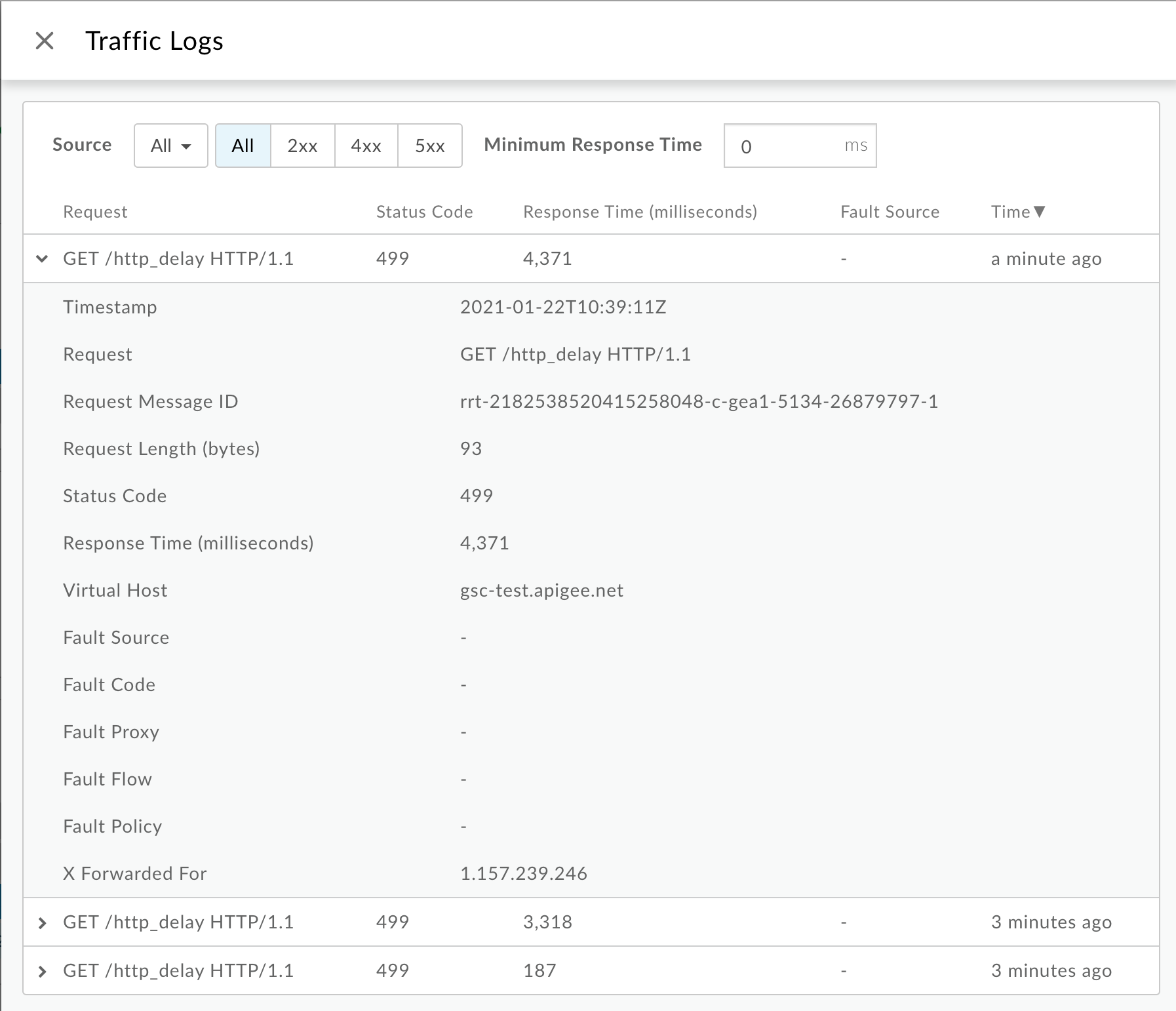
בחלון יומני התנועה, שימו לב לפרטים הבאים לגבי חלק מה
499שגיאות:- בקשה:זו מספקת את שיטת הבקשה וה-URI ששימשו לביצוע הקריאות
- זמן תגובה:המדד הזה מציג את משך הזמן הכולל שחלף לבקשה.
אפשר גם לקבל את כל היומנים באמצעות API Monitoring API של GET Logs. עבור לדוגמה, באמצעות שליחת שאילתה על היומנים עבור
org,env,timeRangeו-status, תהיה לך אפשרות להוריד את כל יומנים עבור טרנזקציות שבהן הלקוח תם הזמן הקצוב.מכיוון ש-API Monitoring מגדיר את שרת ה-proxy ל-
-עבור HTTP499אפשר להשתמש ב-API (Logs API) כדי לקבל את שרת ה-proxy המשויך למארח ולנתיב הווירטואלי.לדוגמה :
curl "https://apimonitoring.enterprise.apigee.com/logs/apiproxies?org=ORG&env=ENV&select=https://VIRTUAL_HOST/BASEBATH" -H "Authorization: Bearer $TOKEN"
- כדאי לבדוק אם יש
499שגיאות נוספות בזמן התגובה ולבדוק אם זמן התגובה עקבי (נניח 30 שניות) בכל499שגיאות.
יומני גישה ל-NGINX
כדי לאבחן את השגיאה באמצעות יומני הגישה של NGINX:
- אם אתם משתמשים בענן פרטי, אתם יכולים להשתמש ביומני הגישה ל-NGINX כדי להבין
את המידע העיקרי על שגיאות HTTP
499. - בודקים את יומני הגישה ל-NGINX:
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - אפשר לבצע חיפוש כדי לראות אם יש שגיאות
499במהלך פרק זמן ספציפי (אם הבעיה אירעה בעבר) או אם יש בקשות שעדיין לא נענו499 - שימו לב לפרטים הבאים לגבי חלק מהשגיאות ב-
499:- זמן תגובה כולל
- כתובת אתר מבוקשת
- סוכן משתמש
שגיאה 499 לדוגמה מיומן הגישה ל-NGINX:
2019-08-23T06:50:07+00:00 rrt-03f69eb1091c4a886-c-sy 50.112.119.65:47756 10.10.53.154:8443 10.001 - - 499 - 422 0 GET /v1/products HTTP/1.1 - okhttp/3.9.1 api.acme.org rrt-03f69eb1091c4a886-c-sy-13001-6496714-1 50.112.119.65 - - - - - - - -1 - - dc-1 router-pod-1 rt-214-190301-0020137-latest-7d 36 TLSv1.2 gateway-1 dc-1 acme prod https -
לצורך הדוגמה הזו מופיעים הפרטים הבאים:
- זמן תגובה כולל:
10.001שניות. המשמעות היא תם הזמן הקצוב של הלקוח אחרי 10.001 שניות - בקשה:
GET /v1/products - מארח:
api.acme.org - סוכן משתמש:
okhttp/3.9.1
- בודקים אם זמן התגובה הכולל וסוכן המשתמש עקביים.
בכל
499השגיאות.
הסיבה: הלקוח סגר בפתאומיות את החיבור
אבחון
- כשנשלחת קריאה ל-API מאפליקציה של דף יחיד שפועלת בדפדפן או באפליקציה לנייד, הדפדפן יבטל את הבקשה אם משתמש הקצה יסגור פתאום את הדפדפן, לדף אינטרנט אחר באותה כרטיסייה, או עוצר את טעינת הדף על ידי לחיצה או הקשה הפסקת הטעינה.
- במקרה כזה, הטרנזקציות עם סטטוס HTTP
499בדרך כלל משתנות בזמן עיבוד הבקשות (זמן תגובה) לכל אחת מהבקשות. -
כדי לבדוק אם זו הסיבה, אפשר להשוות בין זמן התגובה ולבדוק אם
הוא שונה בכל אחת מהשגיאות
499באמצעות API Monitoring או NGINX Access יומנים, כפי שמוסבר בשלבי האבחון הנפוצים.
רזולוציה
- זה מצב תקין, ולרוב אין סיבה לדאגה אם שגיאות HTTP מסוג
499מתרחשים בכמויות קטנות. -
אם זה קורה לעיתים קרובות באותו נתיב של כתובת URL, ייתכן שהסיבה לכך היא ששרת ה-proxy הספציפי המשויך לנתיב הזה הוא איטי מאוד והמשתמשים לא מוכנים להמתין.
אחרי שמזהים איזה שרת proxy עלול להיות מושפע, משתמשים זמן אחזור מרכז הבקרה לניתוח נתונים כדי לחקור לעומק מה גורם לזמן האחזור של שרת ה-proxy.
- במקרה כזה, חשוב לקבוע את שרת ה-Proxy שמושפע לפי השלבים שמפורטים שלבי האבחון הנפוצים
- אפשר להשתמש ב מרכז הבקרה לניתוח זמן האחזור כדי לבדוק מה גורם לזמן האחזור של שרת ה-proxy לפתור את הבעיה.
- אם גיליתם שזמן האחזור צפוי עבור שרת ה-proxy הספציפי, ייתכן כדי ליידע את המשתמשים שייקח זמן מה עד ששרת ה-Proxy יוכל להגיב.
הסיבה: זמן קצוב לתפוגה של אפליקציית לקוח
מצב כזה יכול להתרחש בכמה תרחישים.
-
צפוי שייקח זמן מסוים (למשל 10 שניות) להשלים את הבקשה
בתנאי הפעלה רגילים. עם זאת, אפליקציית הלקוח מוגדרת עם שגיאה
של זמן קצוב לתפוגה (נניח 5 שניות) שגורם לאפליקציית הלקוח לפוג לפני
בקשת ה-API הושלמה, וכתוצאה מכך
499. במקרה הזה, אנחנו צריכים להגדיר הזמן הקצוב לתפוגה של הלקוח לערך מתאים. - נדרש יותר זמן מהצפוי כדי לשרת יעד או יתרונות מרכזיים. במקרה כזה, צריך לתקן את את הרכיב המתאים וגם להתאים את ערכי הזמן הקצוב בהתאם.
- הלקוח לא היה צריך יותר את התגובה ולכן הוא בוטל. זה יכול לקרות במקרים ממשקי API של תדירות כמו השלמה אוטומטית או סקרים קצרים.
אבחון
יומני API Monitoring או NGINX
מאבחן את השגיאה באמצעות יומני API Monitoring או NGINX:
- בודקים את יומני API Monitoring או ביומני הגישה ל-NGINX לטרנזקציות HTTP
499, כמו שמוסבר ב שלבי האבחון הנפוצים. - קובעים אם זמן התגובה עקבי לכל השגיאות מסוג
499. - אם כן, ייתכן שאפליקציית לקוח מסוימת הגדירה זמן קצוב לתפוגה קבוע
שמופיע בה. אם שרת proxy של API או שרת יעד מגיבים באיטיות, הזמן הקצוב לתפוגה של הלקוח יפוג
לפני תום הזמן הקצוב של שרת ה-proxy, וכמויות גדולות של HTTP
499sאותו נתיב URI. במקרה כזה, צריך לקבוע מהו סוכן המשתמש מתוך יומני הגישה ל-NGINX. יכולים לעזור לכם לקבוע את אפליקציית הלקוח הספציפית. - יכול להיות גם שיש מאזן עומסים לפני Apigee כמו Akamai, F5, AWS ELB וכן הלאה. אם ב-Apigee פועלת מאזן עומסים בהתאמה אישית, הבקשה הזמן הקצוב לתפוגה של מאזן העומסים צריך להיות ארוך יותר מהזמן הקצוב לתפוגה של Apigee API. על ידי כברירת מחדל, הזמן הקצוב של הנתב של Apigee מסתיים אחרי 57 שניות, כך שהוא מתאים להגדרת בקשה זמן קצוב לתפוגה של 60 שניות במאזן העומסים.
Trace
אבחון השגיאה באמצעות Trace
אם הבעיה עדיין פעילה (עדיין מתרחשות 499 שגיאות), צריך לבצע את הפקודה
את השלבים הבאים:
- מפעילים את סשן מעקב ל-API הרלוונטי בממשק המשתמש של Edge.
- ממתינים עד שהשגיאה מתרחשת, או אם מקבלים את הקריאה ל-API, ואז מבצעים כמה קריאות ל-API ומשחזרים את השגיאה.
- בדקו את הזמן שחלף בכל שלב ורשמו לעצמכם את השלב שבו רוב הזמן הוא ההוצאה.
- אם תבחינו בשגיאה עם הזמן הארוך ביותר שחלף מיד לאחר אחד
בשלבים הבאים, הוא מצביע על כך ששרת הקצה העורפי איטי או נמשך זמן רב
כדי לעבד את הבקשה:
- הבקשה נשלחה לשרת היעד
- המדיניות בנושא ServiceCallout
הנה דוגמה למעקב אחר ממשק המשתמש שמציג זמן קצוב לתפוגה של שערים אחרי שהבקשה הייתה נשלח לשרת היעד:
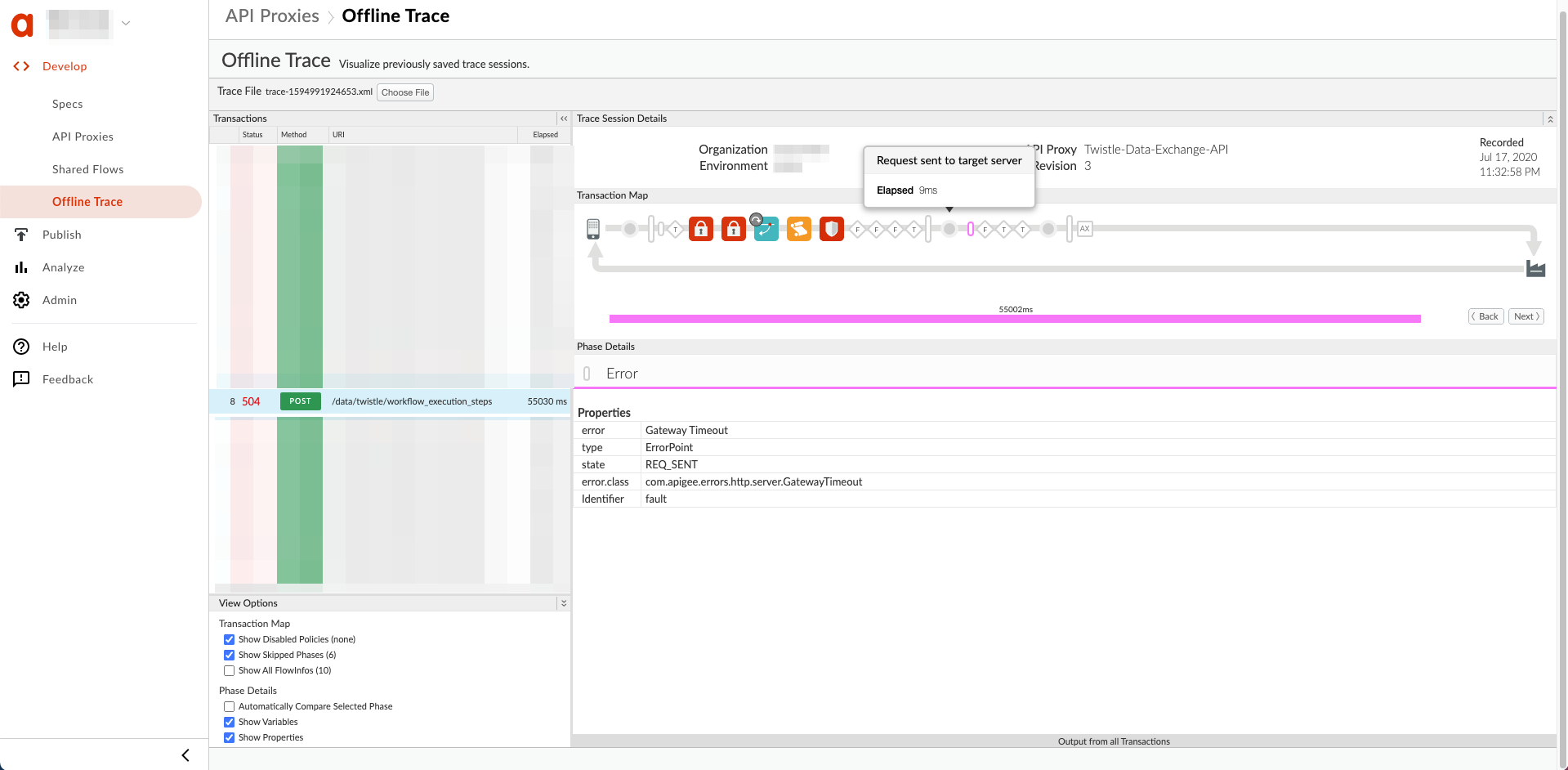
רזולוציה
- ראה שיטות מומלצות להגדרת זמן קצוב לתפוגה של קלט/פלט (I/O) כדי להבין אילו ערכים של זמן קצוב לתפוגה צריך להגדיר ברכיבים שונים שמעורבים בתהליך בקשת ה-API דרך Apigee Edge.
- חשוב לוודא שהגדרתם ערך מתאים של זמן קצוב לתפוגה באפליקציית הלקוח בהתאם שיטות מומלצות.
אם הבעיה עדיין נמשכת, עוברים למאמר נדרש איסוף של פרטי אבחון .
חובה לאסוף פרטי אבחון
אם הבעיה נמשכת, צריך לאסוף את פרטי האבחון הבאים ולפנות לתמיכה של Apigee Edge.
אם אתם משתמשים ב-Public Cloud, עליכם לספק את הפרטים הבאים:
- שם הארגון
- שם הסביבה
- שם ה-API של ה-Proxy
- צריך להשלים את הפקודה
curlששימשה לשחזור השגיאה של הזמן הקצוב לתפוגה - קובץ מעקב של בקשות ה-API שבהן מופיעות שגיאות של הזמן הקצוב לתפוגה של לקוח
אם אתם משתמשים בענן פרטי, עליכם לספק את הפרטים הבאים:
- הודעת שגיאה מלאה שנצפתה בבקשות שנכשלו
- שם הסביבה
- חבילת API Proxy
- קובץ מעקב של בקשות ה-API שבהן מופיעות שגיאות של הזמן הקצוב לתפוגה של לקוח
- יומני גישה ל-NGINX (
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log) - יומני המערכת של מעבד ההודעות (
/opt/apigee/var/log/edge-message-processor/logs/system.log)