
Przeglądasz dokumentację Apigee Edge.
Przejdź do
Dokumentacja Apigee X. informacje.
Krótki opis problemu
Aplikacja kliencka otrzymuje kod stanu HTTP 502 z komunikatem
Bad Gateway jako odpowiedź na wywołania interfejsu API.
Kod stanu HTTP 502 oznacza, że klient nie otrzymuje prawidłowej odpowiedzi z protokołu
i serwery backendu, które powinny zrealizować żądanie.
Komunikaty o błędach
Aplikacja kliencka otrzymuje ten kod odpowiedzi:
HTTP/1.1 502 Bad Gateway
Możesz też zobaczyć następujący komunikat o błędzie:
{
"fault": {
"faultstring": "Unexpected EOF at target",
"detail": {
"errorcode": "messaging.adaptors.http.UnexpectedEOFAtTarget"
}
}
}Możliwe przyczyny
Jedną z typowych przyczyn stanu 502 Bad Gateway Error jest Unexpected EOF
. Oto możliwe przyczyny:
| Przyczyna | Szczegóły | Kroki podane dla |
|---|---|---|
| Nieprawidłowo skonfigurowany serwer docelowy | Serwer docelowy nie jest prawidłowo skonfigurowany do obsługi połączeń TLS/SSL. | Użytkownicy chmury publicznej i prywatnej Edge |
| Wyjątek EOFWyjątek z serwera backendu | Serwer backendu może nagle wysłać EOF. | Tylko użytkownicy Edge Private Cloud |
| Nieprawidłowo skonfigurowany limit czasu utrzymywania aktywności | Utrzymuj nieprawidłowo skonfigurowane limity czasu aktywności w Apigee i serwerze backendu. | Użytkownicy chmury publicznej i prywatnej Edge |
Typowe kroki diagnostyki
Aby zdiagnozować błąd, możesz skorzystać z dowolnej z tych metod:
Monitorowanie interfejsów API
Aby zdiagnozować błąd za pomocą monitorowania interfejsów API:
Monitorowanie interfejsów API umożliwia
błędów 502, wykonując czynności opisane na
Zbadaj problemy. Czyli:
- Otwórz panel Zbadaj.
- W menu wybierz Kod stanu i sprawdź, czy jest właściwy
okres jest wybierany, gdy wystąpiły błędy
502. - Kliknij pole w tabeli, gdy widzisz dużą liczbę błędów typu
502. - Po prawej stronie kliknij Wyświetl dzienniki dla
502błędów, które spowodowały wygląda mniej więcej tak: - Źródło błędu:
target - Kod błędu:
messaging.adaptors.http.UnexpectedEOFAtTarget
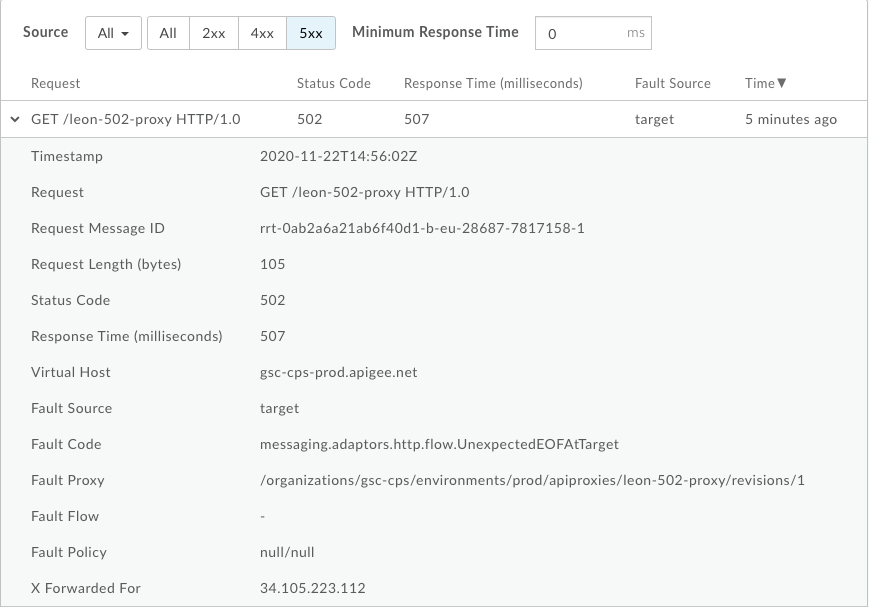
Są to następujące informacje:
Oznacza to, że błąd 502 jest spowodowany przez element docelowy z powodu nieoczekiwanego czasu oczekiwania.
Zanotuj też błąd Request Message ID dotyczący błędu 502, aby dowiedzieć się więcej
i analizy zagrożeń.
Narzędzie śledzenia
Aby zdiagnozować błąd za pomocą narzędzia śledzenia:
- Włącz
śledzenia sesji i wykonaj wywołanie interfejsu API, aby odtworzyć problem
502 Bad Gateway. - Wybierz jedno z nieudanych żądań i sprawdź log czasu.
- Przejdź przez różne fazy śledzenia i znajdź miejsca, w których wystąpił błąd.
-
Błąd powinien pojawić się po wysłaniu żądania do serwera docelowego, jak pokazano poniżej:


-
Określ wartość X-Apigee.fault-source i X-Apigee.fault-code w pliku AX (zarejestrowane dane Analytics) faza w śledzeniu.
Jeśli wartości w polach X-Apigee.fault-source i X-Apigee.fault-code są zgodne z parametrem wartości widocznych w poniższej tabeli, możesz potwierdzić, że błąd
502to pochodzący z serwera docelowego:Nagłówki odpowiedzi Wartość X-Apigee.fault-source targetKod błędu X-Apigee. messaging.adaptors.http.flow.UnexpectedEOFAtTargetZanotuj też błąd
X-Apigee.Message-IDdotyczący błędu502w celu przeprowadzenia dalszych analiz.
Logi dostępu NGINX
Aby zdiagnozować błąd przy użyciu NGINX:
Aby ustalić przyczynę stanu 502, możesz też skorzystać z logów dostępu NGINX
w kodzie. Jest to szczególnie przydatne, jeśli problem wystąpił w przeszłości lub jest
przerywa i nie można zarejestrować logu czasu w interfejsie. Wykonaj te czynności, aby
określić te informacje w logach dostępu NGINX:
- Sprawdź logi dostępu NGINX.
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - Wyszukaj wszystkie błędy
502dotyczące określonego serwera proxy interfejsu API w wybranym okresie (jeśli problem wystąpił w przeszłości) lub w przypadku żądań z502, które nadal kończą się niepowodzeniem. - Jeśli wystąpiły błędy (
502), sprawdź, czy są one spowodowane przez cel wysyłaUnexpected EOF. Jeśli wartości X-Apigee.fault-source i X- Apigee.fault-code pasuje do wartości w tabeli poniżej, błąd502to spowodowane niespodziewanym zamknięciem połączenia przez element:Nagłówki odpowiedzi Wartość X-Apigee.fault-source targetKod błędu X-Apigee. messaging.adaptors.http.flow.UnexpectedEOFAtTargetOto przykładowy wpis pokazujący błąd
502spowodowany przez serwer docelowy: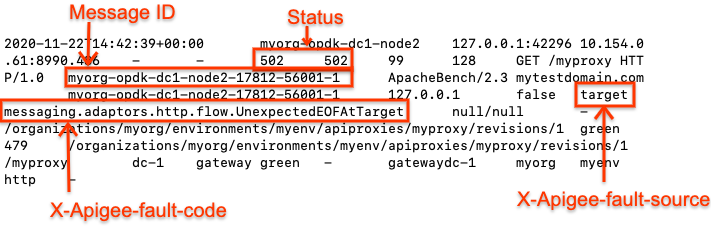
Zanotuj też identyfikatory wiadomości dotyczące błędów 502 w celu dalszej analizy.
Przyczyna: nieprawidłowo skonfigurowany serwer docelowy
Serwer docelowy nie jest prawidłowo skonfigurowany do obsługi połączeń TLS/SSL.
Diagnostyka
- Użyj monitorowania interfejsów API, narzędzia do śledzenia lub
dzienniki dostępu NGINX w celu określenia identyfikatora wiadomości,
kodu i źródła błędu
502. - Włącz śledzenie w interfejsie API, którego dotyczy problem.
- Jeśli log czasu w przypadku nieudanego żądania do interfejsu API wyświetla te informacje:
- Błąd
502 Bad Gatewaypojawia się od razu po rozpoczęciu żądania docelowego przepływu. error.classwyświetlamessaging.adaptors.http.UnexpectedEOF.W takiej sytuacji najprawdopodobniej problem jest spowodowany nieprawidłowym serwerem docelowym. konfiguracji.
- Błąd
- Uzyskaj definicję serwera docelowego za pomocą wywołania interfejsu Edge Management API:
- Jeśli jesteś użytkownikiem Public Cloud, użyj tego interfejsu API:
curl -v https://api.enterprise.apigee.com/v1/organizations/<orgname>/environments/<envname>/targetservers/<targetservername> -u <username>
- Jeśli jesteś użytkownikiem Private Cloud, użyj tego interfejsu API:
curl -v http://<management-server-host>:<port #>/v1/organizations/<orgname>/environments/<envname>/targetservers/<targetservername> -u <username>
Przykładowa nieprawidłowa definicja atrybutu
TargetServer:<TargetServer name="target1"> <Host>mocktarget.apigee.net</Host> <Port>443</Port> <IsEnabled>true</IsEnabled> </TargetServer >
- Jeśli jesteś użytkownikiem Public Cloud, użyj tego interfejsu API:
-
Ilustracja przedstawiająca
TargetServerto przykład jednego z typowych które są opisane w ten sposób:Załóżmy, że serwer docelowy
mocktarget.apigee.netjest skonfigurowany , aby akceptować bezpieczne (HTTPS) połączenia przez port443. Jeśli jednak spojrzymy na definicji serwera docelowego, nie ma żadnych innych atrybutów/flag, które wskazywałyby, że zapewnia bezpieczeństwo połączeń. Sprawia to, że Edge traktuje żądania API wysyłane do określony serwer docelowy jako żądania HTTP (niezabezpieczone). Edge nie będzie zainicjować proces uzgadniania połączenia SSL z tym serwerem docelowym.Serwer docelowy jest skonfigurowany do akceptowania tylko żądań HTTPS (SSL) w
443, dlatego będzie odrzucić żądanie z Edge lub zamknąć połączenie. W rezultacie otrzymujeszUnexpectedEOFAtTargetbłąd w procesorze wiadomości. Procesor wiadomości wyśle502 Bad Gatewayjako odpowiedź dla klienta.
Rozdzielczość
Zawsze sprawdzaj, czy serwer docelowy jest poprawnie skonfigurowany zgodnie z wymaganiami.
Jeśli na przykład w przykładzie powyżej chcesz wysyłać żądania do bezpiecznego miejsca docelowego (HTTPS/SSL),
, musisz dodać atrybuty SSLInfo z ustawioną flagą enabled
do: true. Można jednak dodawać atrybuty SSLInfo w przypadku serwera docelowego w środowisku docelowym
definicji punktu końcowego, zalecamy dodanie atrybutów SSLInfo jako części elementu docelowego
definicji serwera, aby uniknąć nieporozumień.
- Jeśli usługa backendu wymaga jednokierunkowej komunikacji SSL:
- Musisz włączyć TLS/SSL w definicji
TargetServer, dodającSSLInfow których flagaenabledma wartość Prawda, jak pokazano poniżej:<TargetServer name="mocktarget"> <Host>mocktarget.apigee.net</Host> <Port>443</Port> <IsEnabled>true</IsEnabled> <SSLInfo> <Enabled>true</Enabled> </SSLInfo> </TargetServer> - Jeśli chcesz zweryfikować certyfikat serwera docelowego w Edge, musimy też
dołącz magazyn zaufania (zawierający certyfikat serwera docelowego), jak pokazano poniżej:
<TargetServer name="mocktarget"> <Host>mocktarget.apigee.net</Host> <Port>443</Port> <IsEnabled>true</IsEnabled> <SSLInfo> <Ciphers/> <ClientAuthEnabled>false</ClientAuthEnabled> <Enabled>true</Enabled> <IgnoreValidationErrors>false</IgnoreValidationErrors> <Protocols/> <TrustStore>mocktarget-truststore</TrustStore> </SSLInfo> </TargetServer>
- Musisz włączyć TLS/SSL w definicji
- Jeśli usługa backendu wymaga dwukierunkowej komunikacji SSL:
- Musisz mieć atrybuty
SSLInfozClientAuthEnabled,Keystore,KeyAliasi FlagiTruststorezostały ustawione prawidłowo, tak jak poniżej:<TargetServer name="mocktarget"> <IsEnabled>true</IsEnabled> <Host>www.example.com</Host> <Port>443</Port> <SSLInfo> <Ciphers/> <ClientAuthEnabled>true</ClientAuthEnabled> <Enabled>true</Enabled> <IgnoreValidationErrors>false</IgnoreValidationErrors> <KeyAlias>keystore-alias</KeyAlias> <KeyStore>keystore-name</KeyStore> <Protocols/> <TrustStore>truststore-name</TrustStore> </SSLInfo> </TargetServer >
- Musisz mieć atrybuty
Pliki referencyjne
Równoważenie obciążenia między serwerami backendu
Przyczyna: EOFWyjątek z serwera backendu
Serwer backendu może nagle wysłać EOF (koniec pliku).
Diagnostyka
- Użyj monitorowania interfejsów API, narzędzia do śledzenia lub
dzienniki dostępu NGINX w celu określenia identyfikatora wiadomości,
kodu i źródła błędu
502. - Sprawdzanie logów procesora wiadomości
(
/opt/apigee/var/log/edge-message-processor/logs/system.log) i wyszukaj hasło, wartośćeof unexpecteddla konkretnego interfejsu API lub jeśli masz unikalny identyfikatormessageiddla tego interfejsu API. możesz wyszukać to hasło.Przykładowy zrzut stosu wyjątków z dziennika procesora wiadomości
"message": "org:myorg env:test api:api-v1 rev:10 messageid:rrt-1-14707-63403485-19 NIOThread@0 ERROR HTTP.CLIENT - HTTPClient$Context$3.onException() : SSLClientChannel[C:193.35.250.192:8443 Remote host:0.0.0.0:50100]@459069 useCount=6 bytesRead=0 bytesWritten=755 age=40107ms lastIO=12832ms .onExceptionRead exception: {} java.io.EOFException: eof unexpected at com.apigee.nio.channels.PatternInputChannel.doRead(PatternInputChannel.java:45) ~[nio-1.0.0.jar:na] at com.apigee.nio.channels.InputChannel.read(InputChannel.java:103) ~[nio-1.0.0.jar:na] at com.apigee.protocol.http.io.MessageReader.onRead(MessageReader.java:79) ~[http-1.0.0.jar:na] at com.apigee.nio.channels.DefaultNIOSupport$DefaultIOChannelHandler.onIO(NIOSupport.java:51) [nio-1.0.0.jar:na] at com.apigee.nio.handlers.NIOThread.run(NIOThread.java:123) [nio-1.0.0.jar:na]"
W powyższym przykładzie widać, że błąd
java.io.EOFException: eof unexpectedwystąpił, gdy procesor wiadomości próbuje odczytać odpowiedź z do serwera backendu. Ten wyjątek oznacza, że na końcu pliku (EOF) znajduje się koniec pliku lub na koniec strumienia nieoczekiwanie miało miejsce.Oznacza to, że procesor wiadomości wysłał żądanie do interfejsu API do serwera backendu, który czekał lub przeczytanie odpowiedzi. Serwer backendu nagle zakończył jednak połączenie zanim procesor wiadomości odebrał odpowiedź lub zdołał odczytać pełną odpowiedź.
- Sprawdź w dziennikach serwera backendu, czy są w nim błędy lub informacje, które mogą skłoniły serwer backendu do nagłego zakończenia połączenia. Jeśli znajdziesz błędy/informacje, a następnie kliknij Rozwiązanie. i odpowiednio rozwiąż problem na serwerze backendu.
- Jeśli na serwerze backendu nie ma żadnych błędów ani informacji, zbierz dane wyjściowe
tcpdumpw systemach przetwarzania wiadomości:- .
- Jeśli host serwera backendu ma jeden adres IP, użyj tego polecenia:
tcpdump -i any -s 0 host IP_ADDRESS -w FILE_NAME
- Jeśli host serwera backendu ma kilka adresów IP, użyj tego polecenia:
tcpdump -i any -s 0 host HOSTNAME -w FILE_NAME
Zwykle ten błąd jest spowodowany tym, że serwer backendu odpowiada komunikatem
[FIN,ACK], gdy tylko procesor wiadomości wyśle żądanie do serwera backendu.
- Jeśli host serwera backendu ma jeden adres IP, użyj tego polecenia:
-
Zobacz ten
tcpdumpprzykład.Przykładowe
tcpdumpzostało zrobione, gdy502 Bad Gateway Error(UnexpectedEOFAtTarget) wystąpił
- W danych wyjściowych TCPDump możesz zauważyć następującą sekwencję zdarzeń:
- W pakiecie
985procesor wiadomości wysyła żądanie interfejsu API do serwera backendu. - W pakiecie
986serwer backendu natychmiast odpowiada, wysyłając[FIN,ACK]. - W pakiecie
987procesor wiadomości odpowiada do backendu kodem[FIN,ACK]serwera. - W końcu połączenia zostaną zamknięte za pomocą
[ACK]i[RST]po obu stronach. - Serwer backendu wysyła żądanie
[FIN,ACK], więc otrzymasz wyjątek Wyjątek:java.io.EOFException: eof unexpectedw wiadomości Procesor.
- W pakiecie
- Może się tak zdarzyć, jeśli na serwerze backendu wystąpił problem z siecią. Angażowanie sieci zespołu operacyjnego Google, aby dokładniej zbadać ten problem.
Rozdzielczość
Napraw problem na serwerze backendu.
Jeśli problem będzie się powtarzał i potrzebujesz pomocy w rozwiązaniu problemu, 502 Bad Gateway Error lub
Podejrzewasz, że problem jest związany z Edge, skontaktuj się z zespołem pomocy Apigee Edge.
Przyczyna: nieprawidłowo skonfigurowany limit czasu utrzymywania aktywności
Zanim sprawdzisz, czy to jest przyczyną błędów 502, przeczytaj
następujące koncepcje.
Stałe połączenia w Apigee
Apigee domyślnie (a potem zgodnie ze standardem HTTP/1.1) używa trwałych połączeń
podczas komunikacji z docelowym serwerem backendu. Trwałe połączenia mogą zwiększyć wydajność
przez umożliwienie ponownego użycia istniejącego połączenia TCP oraz (jeśli dotyczy) połączenia TLS/SSL,
zmniejsza to obciążenie związane z opóźnieniami. Czas, przez jaki połączenie musi być utrzymywane, jest kontrolowany
za pomocą właściwości Limit czasu aktywności (keepalive.timeout.millis).
Zarówno serwer backendu, jak i procesor wiadomości Apigee używają limitów czasu utrzymywania aktywności, aby że są one nawiązywane. Gdy nie otrzymasz danych po upływie limitu czasu utrzymywania aktywności serwer backendu lub procesor wiadomości mogą zakończyć połączenie z tym drugim.
Domyślnie serwery proxy interfejsów API wdrożone w procesorze wiadomości w Apigee mają limit czasu utrzymywania aktywności ustawiony na
60s, chyba że zostanie zastąpione. Gdy 60s nie otrzyma żadnych danych, Apigee
zamknij połączenie z serwerem backendu. Serwer backendu będzie też ustalać limit czasu utrzymywania aktywności,
Po tym czasie serwer backendu zakończy połączenie z procesorem wiadomości.
Konsekwencje nieprawidłowej konfiguracji limitu czasu utrzymywania aktywności
Jeśli Apigee lub serwer backendu są skonfigurowane z nieprawidłowymi limitami czasu utrzymywania aktywności,
prowadzi do sytuacji wyścigu, która powoduje, że serwer backendu wysyła nieoczekiwany End Of File
(FIN) na żądanie zasobu.
Jeśli na przykład limit czasu utrzymywania aktywności został skonfigurowany na serwerze proxy API lub w wiadomości
Procesor o wartości równej lub większej niż limit czasu oczekiwania serwera backendu nadrzędnego, a następnie
może wystąpić następujący warunek wyścigu. Oznacza to, że jeśli procesor wiadomości nie otrzyma
dane aż do osiągnięcia progu czasu utrzymywania aktywności serwera backendu, a następnie żądanie
przychodzi i jest wysyłana do serwera backendu przy użyciu istniejącego połączenia. Może to prowadzić do:
502 Bad Gateway z powodu nieoczekiwanego błędu EOF, zgodnie z opisem poniżej:
- Załóżmy, że limit czasu utrzymywania aktywności jest ustawiony zarówno na procesorze wiadomości, jak i na serwerze backendu wynosi 60 sekund upłynęło 59 sekund od momentu przesłania poprzedniego żądania przez Procesor komunikatów.
- Procesor wiadomości przechodzi dalej i przetwarza żądanie przesłane w 59 sekundzie. przy użyciu istniejącego połączenia (ponieważ limit czasu utrzymywania aktywności jeszcze nie minął) i wysyła do serwera backendu.
- Jednak zanim żądanie dotrze do serwera backendu, limit czasu utrzymywania aktywności od tego czasu na serwerze backendu został przekroczony limit.
- Żądanie procesora wiadomości dotyczące zasobu jest przetwarzane, ale serwer backendu
próbuje zamknąć połączenie, wysyłając pakiet
FINdo wiadomości. Procesor. - Gdy procesor wiadomości czeka na odebranie danych, zamiast tego
nieoczekiwany
FINi połączenie zostaje zakończone. - Wynikiem jest
Unexpected EOF, a następnie502zwracany klientowi przez procesor wiadomości.
W tym przypadku zaobserwowaliśmy błąd 502, ponieważ ten sam czas utrzymywania aktywności
Wartość 60 sekund została skonfigurowana zarówno na procesorze komunikatów, jak i na serwerze backendu. Podobnie
ten problem może również wystąpić, jeśli ustawiona jest większa wartość limitu czasu utrzymywania aktywności w wiadomości
procesor niż na serwerze backendu.
Diagnostyka
- Jeśli jesteś użytkownikiem Public Cloud:
- Użyj narzędzia do monitorowania lub śledzenia interfejsów API (jak wyjaśniono w artykule
Typowe kroki diagnostyki) i sprawdź, czy zostały spełnione oba poniższe warunki
ustawienia:
- Kod błędu:
messaging.adaptors.http.flow.UnexpectedEOFAtTarget - Źródło błędu:
target
- Kod błędu:
- Więcej informacji znajdziesz w artykule Korzystanie z tcpdump.
- Użyj narzędzia do monitorowania lub śledzenia interfejsów API (jak wyjaśniono w artykule
Typowe kroki diagnostyki) i sprawdź, czy zostały spełnione oba poniższe warunki
ustawienia:
- Jeśli jesteś użytkownikiem Private Cloud:
- Użyj narzędzia Trace lub
dzienniki dostępu NGINX w celu określenia identyfikatora wiadomości,
kod i źródło błędu
502. - Wyszukaj identyfikator wiadomości w dzienniku procesora wiadomości
(/opt/apigee/var/log/edge-message-processor/logs/system.log). java.io.EOFEXception: eof unexpectedbędzie wyglądać tak:2020-11-22 14:42:39,917 org:myorg env:prod api:myproxy rev:1 messageid:myorg-opdk-dc1-node2-17812-56001-1 NIOThread@1 ERROR HTTP.CLIENT - HTTPClient$Context$3.onException() : ClientChannel[Connected: Remote:51.254.225.9:80 Local:10.154.0.61:35326]@12972 useCount=7 bytesRead=0 bytesWritten=159 age=7872ms lastIO=479ms isOpen=true.onExceptionRead exception: {} java.io.EOFException: eof unexpected at com.apigee.nio.channels.PatternInputChannel.doRead(PatternInputChannel.java:45) at com.apigee.nio.channels.InputChannel.read(InputChannel.java:103) at com.apigee.protocol.http.io.MessageReader.onRead(MessageReader.java:80) at com.apigee.nio.channels.DefaultNIOSupport$DefaultIOChannelHandler.onIO(NIOSupport.java:51) at com.apigee.nio.handlers.NIOThread.run(NIOThread.java:220)
- Błąd
java.io.EOFException: eof unexpectedwskazuje, że Procesor wiadomości otrzymałEOF, gdy wciąż czekał na odczyt z serwera backendu. - Atrybut
useCount=7w powyższym komunikacie o błędzie wskazuje, że Procesor wiadomości ponownie użył tego połączenia około 7 razy i atrybutbytesWritten=159oznacza, że żądanie zostało wysłane przez procesor wiadomości.159B do serwera backendu. Nie odebrano jednak żadnych bajtów w przypadku nieoczekiwanego zdarzeniaEOF. -
To pokazuje, że procesor wiadomości wielokrotnie używał tego samego połączenia i tego dnia wysłał dane, ale niedługo potem otrzymał
EOFprzed odebraniem jakichkolwiek danych. Oznacza to, że z dużym prawdopodobieństwem limit czasu utrzymywania aktywności serwera jest krótszy niż limit czasu oczekiwania serwera API lub równy limitowi czasu aktywności serwera.Więcej informacji znajdziesz poniżej, korzystając z pomocy firmy
tcpdump.
- Użyj narzędzia Trace lub
dzienniki dostępu NGINX w celu określenia identyfikatora wiadomości,
kod i źródło błędu
Korzystanie z tcpdump
- Przechwyć zdarzenie
tcpdumpna serwerze backendu za pomocą tego polecenia:tcpdump -i any -s 0 host MP_IP_Address -w File_Name
- Przeanalizuj przechwycone dane (
tcpdump):Oto przykładowe dane wyjściowe narzędzia tcpdump:

W powyższym przykładzie
tcpdumpmożesz zobaczyć:- W pakiecie
5992,serwer backendu odebrał żądanieGET. - W pakiecie
6064odpowiada parametrem200 OK. - W pakiecie
6084serwer backendu odebrał kolejne żądanieGET. - W pakiecie
6154odpowiada parametrem200 OK. - W pakiecie
6228serwer backendu odebrał trzecie żądanieGET. - Tym razem serwer backendu zwraca kod
FIN, ACKdo procesora komunikatów. (pakiet6285) inicjujący zamknięcie połączenia.
W tym przykładzie to samo połączenie zostało użyte ponownie 2 razy, ale w trzecim żądaniu serwer backendu inicjuje zamykanie połączenia, a procesor komunikatów oczekiwanie na dane z serwera backendu. To sugeruje, że na serwerze backendu limit czasu aktywności będzie najprawdopodobniej krótszy lub równy wartości ustawionej w serwerze proxy interfejsu API. Do weryfikacji Więcej informacji znajdziesz w sekcji Porównanie limitu czasu utrzymywania aktywności na serwerze Apigee i serwerze backendu.
- W pakiecie
Porównanie limitu czasu utrzymywania aktywności na serwerze Apigee i serwerze backendu
- Domyślnie Apigee używa wartości 60 sekund dla właściwości limitu czasu utrzymywania aktywności.
-
Istnieje jednak możliwość, że na serwerze proxy interfejsu API zastąpiono wartość domyślną. Możesz to zweryfikować, sprawdzając konkretną definicję
TargetEndpointw z niesprawnym serwerem proxy interfejsu API, który zwraca błędy502.Przykładowa konfiguracja docelowego punktu końcowego:
<TargetEndpoint name="default"> <HTTPTargetConnection> <URL>https://mocktarget.apigee.net/json</URL> <Properties> <Property name="keepalive.timeout.millis">30000</Property> </Properties> </HTTPTargetConnection> </TargetEndpoint>W powyższym przykładzie właściwość limitu czasu utrzymywania aktywności zostaje zastąpiona wartością 30 sekund (
30000milisekund). - Następnie sprawdź właściwość limitu czasu utrzymywania aktywności skonfigurowaną na serwerze backendu. Powiedzmy,
Twój serwer backendu jest skonfigurowany z wartością
25 seconds. - Jeśli stwierdzisz, że wartość właściwości limitu czasu utrzymywania aktywności w Apigee jest wyższa
niż wartość właściwości limitu czasu utrzymywania aktywności na serwerze backendu, jak powyżej
to jest przyczyną błędów
502.
Rozdzielczość
Sprawdź, czy właściwość limitu czasu utrzymywania aktywności jest zawsze niższa w Apigee (na serwerze proxy API i komponentem procesora wiadomości) w porównaniu z komponentem na serwerze backendu.
- Określ wartość limitu czasu utrzymywania aktywności na serwerze backendu.
- Skonfiguruj odpowiednią wartość właściwości limitu czasu utrzymywania aktywności na serwerze proxy API lub procesora wiadomości tak, aby właściwość utrzymywania limitu czasu aktywności była krótsza niż wartość ustawiona w serwera backendu, wykonując czynności opisane w Konfiguruję limit czasu utrzymywania aktywności w procesorach wiadomości.
Jeśli problem będzie nadal występował, wejdź na Konieczne jest zbieranie informacji diagnostycznych.
Sprawdzona metoda
Zdecydowanie zalecamy, aby komponenty podrzędne miały zawsze krótszy limit czasu utrzymywania aktywności
niż określony na serwerach nadrzędnych, aby uniknąć tego rodzaju wyścigów
502 błędu. Każdy przeskok w dół powinien być mniejszy niż każdy przeskok w górę. W Apigee
Edge, warto stosować się do tych wskazówek:
- Limit czasu utrzymywania aktywności klienta powinien być krótszy niż limit czasu utrzymywania aktywności routera brzegowego.
- Limit czasu utrzymywania aktywności routera brzegowego powinien być krótszy niż limit czasu utrzymywania aktywności procesora wiadomości.
- Limit czasu utrzymywania aktywności procesora wiadomości powinien być krótszy niż limit czasu utrzymywania aktywności serwera docelowego.
- Jeśli przed lub za Apigee są inne przeskoki, zastosuj tę samą regułę. Odpowiedzialność za zamknięcie połączenia z nadrzędnym ruchem.
Musi zbierać informacje diagnostyczne
Jeśli po wykonaniu powyższych czynności problem nie ustąpi, zwróć uwagę na informacje diagnostyczne, a następnie skontaktuj się z zespołem pomocy Apigee Edge.
Jeśli jesteś użytkownikiem Public Cloud, podaj te informacje:
- Nazwa organizacji
- Nazwa środowiska
- Nazwa serwera proxy interfejsu API
- Wykonaj polecenie
curl, aby odtworzyć błąd502 - Plik śledzenia zawierający żądania z błędem
502 Bad Gateway - Unexpected EOF - Jeśli błędy typu
502nie występują obecnie, podaj przedział czasu za pomocą funkcji informacje o strefie czasowej, gdy w przeszłości wystąpiły błędy502.
Jeśli jesteś użytkownikiem Private Cloud, podaj te informacje:
- Pełny komunikat o błędzie zaobserwowany dla nieudanych żądań
- Organizacja, nazwa środowiska i nazwa serwera proxy interfejsu API, które obserwujesz
502błędu - Pakiet serwera proxy interfejsu API
- Plik śledzenia zawierający żądania z błędem
502 Bad Gateway - Unexpected EOF - Logi dostępu NGINX
/opt/apigee/var/log/edge-router/nginx/ORG~ENV.PORT#_access_log - Logi procesora wiadomości
/opt/apigee/var/log/edge-message-processor/logs/system.log - Przedział czasu z informacjami o strefie czasowej, w którym wystąpiły błędy
502. - Dane
Tcpdumpszebrane przez procesory wiadomości lub serwer backendu albo w obu przypadkach w przypadku błędu wystąpiło