The following sections describe the known issues with Apigee. In most cases, the issues listed will be fixed in a future release.
Miscellaneous Edge known issues
The following sections describe miscellaneous known issues with Edge.
Area/Summary
Known issues
Cache expire results in incorrect cachehit value
When the cachehit flow variable is used after the
LookupCache policy, due to the way debug points are dispatched for
asynchronous behavior, the LookupPolicy populates the DebugInfo object
before the call back has executed, resulting in an error.
Workaround: Repeat the process (make second call) again right
after the first call.
Setting InvalidateCache Policy
PurgeChildEntries to true does not work correctly
Setting PurgeChildEntries in the
InvalidateCache policy should purge the KeyFragment element values only but
clears the entire cache.
Workaround: Use the
KeyValueMapOperations policy
to iterate cache versioning and bypass the need for cache invalidation.
Concurrent deployment requests for a SharedFlow or API proxy
can result in an inconsistent state in the Management Server
where multiple revisions are shown as deployed.
This can happen,
for example, when concurrent runs of a CI/CD deployment pipeline
occur using different revisions. To avoid this problem, avoid
deploying API proxies or SharedFlows before the current
deployment is complete.
Workaround: Avoid concurrent API proxy or SharedFlow deployments.
API call counts shown in
Edge API Analytics might contain
duplicate data.
Edge API Analytics can sometimes contain duplicate data for API calls. In that case the counts shown for
API calls in Edge API Analytics are higher than the comparable values shown in third-party analytics tools.
The following sections describe the known issues with the Edge UI.
Area
Known issues
Can't access Edge SSO Zone Administration page from navigation bar after organization is mapped to an identity zone
When you connect an organization to an identity zone,
you can no longer access the Edge SSO Zone Administration page from
the left navigation bar by selecting Admin > SSO. As a workaround, navigate to the page directly using the following URL:
https://apigee.com/sso
Known issues with the integrated portal
The following sections describe the known issues with the integrated portal.
For example, the following features from the OpenAPI Specification 3.0 are not yet supported:
allOf properties for combining and extending schemas
Remote references
If an unsupported feature is referenced in your OpenAPI Specification, in some cases the tools will ignore the feature but still
render the API reference documentation. In other cases, an unsupported feature will cause errors that prevent the successful rendering
of the API reference documentation. In either case, you will need to modify your OpenAPI Specification to avoid use of the unsupported
feature until it is supported in a future release.
Note: Because the spec editor is less restrictive than SmartDocs when rendering API reference documentation,
you may experience different results between the tools.
When using Try this API in the portal, the Accept header is set to application/json regardless of the value set for consumes in the OpenAPI Specification.
Single logout (SLO) with the SAML identity provider is not supported for custom domains. To enable a custom domain with a SAML identity provider, leave
the Sign-out URL field blank
when you configure SAML settings.
Portal admin
Simultaneous portal updates (such as page, theme, CSS, or script edits) by multiple users is not supported at this time.
If you delete an API reference documentation page from the portal, there is no way to recreate it; you'll need to delete and re-add
the API product, and regenerate the API reference documentation.
Search will be integrated into the integrated portal in a future release.
Known issues with Edge for Private Cloud
The following sections describe the known issues with Edge for Private Cloud.
Area
Known issues
Edge for Private Cloud 4.53.00
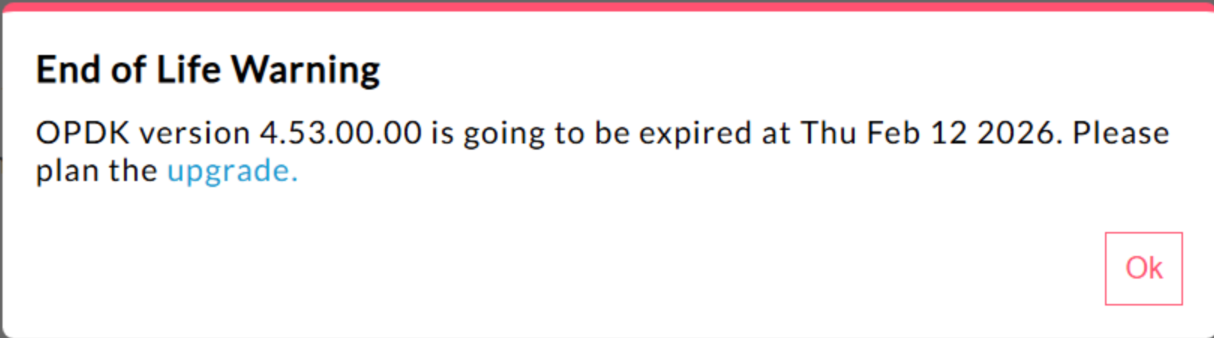
440148595: End of Life Popup Warning Displayed Excessively
In Edge for Private Cloud 4.53.00 and later, the UI displays an
"End of Life" (EOL) warning pop-up. This warning
appears
repeatedly and cannot be prevented or reduced in frequency.
There is currently no method available for users to disable or reduce the frequency
of this EOL warning.
Edge for Private Cloud 4.53.01
443272053: Datastore errors in edge components
In Edge for Private Cloud 4.53.00 or later, a specific type of interaction between Cassandra and application components (Management server, Message Processor or Router) may cause datastore errors. When such an error occurs, you'll observe logs of the following pattern in the specific application component's system logs:
com.datastax.driver.core.exceptions.ProtocolError: An unexpected protocol error occurred on host WW.XX.YY.ZZ:9042.
These errors occur when the application component is not configured to handle warnings generated by the Cassandra database. You can mitigate this issue by avoiding or suppressing warnings in your Cassandra nodes. In most cases, warnings are generated due to excessive tombstones. You can follow one of the following options or a combination of options listed:
Reduce gc_grace_seconds: For the table displayed in the log message associated with the error, reduce gc_grace_seconds by running the following command like the following, using cqlsh:
Below command sets gc_grace_seconds of kms.oauth_20_access_tokens to 1 day from default 10 days
ALTER TABLE kms.oauth_20_access_tokens WITH gc_grace_seconds = '86400';
Increase tombstone thresholds in Cassandra for generating warnings. For this, use the following instructions:
On a Cassandra node, create or edit file $APIGEE_ROOT/customer/application/cassandra.properties.
Increase Tombstone warn threshold to 100k from the default 10k or set larger values as appropriate by adding the following line:
conf_cassandra_tombstone_warn_threshold=100000
Ensure the file above is owned and readable by apigee user:
Repeat the above steps on each Cassandra node, one by one.
42733857: Latency in updating encrypted key value maps (KVMs)
When working with Encrypted Key Value Maps that contain a large number of entries, users may experience latencies when adding or updating entries, whether through management APIs or the PUT element within the KeyValueMapOperations policy . The extent of the performance impact is generally proportional to the total number of entries stored in the encrypted KVM.
To mitigate this issue, it is recommended that users avoid creating encrypted KVMs with an excessive number of entries. A viable solution is to divide a large KVM into multiple, smaller KVMs. Additionally, if the use case permits, migrating to a non-encrypted KVM can also serve as an effective mitigation strategy. Please note that Apigee is aware of this issue and plans to release a fix in a future patch.
Java Callouts
Customer Java callouts that attempt to load the Bouncy Castle cryptography provider using the name "BC" might fail because the default provider has been changed to Bouncy Castle FIPS to support FIPS. The new provider name to use is "BCFIPS".
Edge for Private Cloud 4.53.00
Java Callouts
Customer Java callouts that attempt to load the Bouncy Castle cryptography provider using the name "BC" might fail because the default provider has been changed to Bouncy Castle FIPS to support FIPS. The new provider name to use is "BCFIPS".
Edge for Private Cloud 4.52.01 Mint update
This issue affects only those who are using MINT or have MINT enabled in Edge for Private Cloud installations.
Component affected: edge-message-processor
Issue: If you have monetization enabled and are installing 4.52.01 as a fresh install or upgrading from previous Private Cloud versions, you will encounter an issue with message processors. There will be a gradual increase in open thread count leading to resource exhaustion. The following exception is seen in edge-message-processor system.log:
A Denial-of-Service (DoS) vulnerability was recently discovered in multiple
implementations of the HTTP/2 protocol (CVE-2023-44487), including in Apigee Edge for
Private Cloud. The vulnerability could lead to a DoS of Apigee API management functionality.
For more details, see Apigee Security Bulletin GCP-2023-032.
The Edge for Private Cloud router and management server components are exposed to the
internet and can potentially be vulnerable. Although HTTP/2 is enabled on the management
port of other Edge-specific components of Edge for Private Cloud, none of those components are
exposed to the internet. On non-Edge components, like Cassandra, Zookeeper and others,
HTTP/2 is not enabled. We recommend that you take the
following steps to address the Edge for Private Cloud vulnerability:
Apigee-postgresql is having issues with upgrading from Edge for Private Cloud
version 4.50 or 4.51 to version 4.52. The issues mainly
occur when the number of tables is greater than 500.
You can check the total number of tables in Postgres by running the SQL query below:
149245401: LDAP connection pool settings for JNDI configured through the
LDAP resource
are not reflected, and JNDI defaults cause single-use connections each time.
As a result, connections are being opened
and closed each time for single use, creating a large number of
connections per hour to the LDAP server.
Workaround:
In order to change the LDAP connection pool properties, do
the following steps to set a global change across all LDAP policies.
Create a configuration properties file if it does not already exist:
Add the following to the file (replace values of
Java Naming and Directory Interface (JNDI) properties
based on your LDAP resource configuration requirement).
Make sure the file
/opt/apigee/customer/application/message-processor.properties is
owned by apigee:apigee.
Restart each message processor.
To verify that your connection pool JNDI
properties are taking effect, you can
perform a tcpdump to observe the behavior of the LDAP connection pool
over time.
High Request Processing Latency
139051927: High proxy processing latencies found in the Message Processor
are affecting
all API Proxies. Symptoms include 200-300ms delays in processing times over normal
API response
times and can occur randomly even with low TPS. This can occur when than more than 50 target
servers in which a message processor makes connections.
Root cause:
Message processors keep a cache that maps target server URL to HTTPClient object for
outgoing connections to target servers. By default this setting is set to 50 which may be
too low for most deployments. When a deployment has multiple org/env combinations in a setup,
and have a large number of target servers that exceed 50 altogether, the target server URLs
keep getting evicted from cache, causing latencies.
Validation:
To determine if target server URL eviction is causing the latency problem, search the
Message Processor system.logs
for keyword "onEvict" or "Eviction". Their presence in the logs indicate that target server URLs
are getting evicted from the HTTPClient cache because the cache size is too small.
Workaround:
For Edge for Private Cloud versions 19.01 and 19.06, you can edit and configure the HTTPClient
cache, /opt/apigee/customer/application/message-processor.properties:
Then restart the message processor. Make the same changes for all message processors.
The value 500 is an example. The optimal value for your setup should be greater than
the number of target servers that the message processor would connect to. There are no side
effects from
setting this property higher, and the only affect would be an improved message processor
proxy request processing times.
Note: Edge for Private Cloud version 50.00 has the default setting of 500.
Multiple entries for key value maps
157933959: Concurrent inserts and updates to the same key value map (KVM) scoped to the
organization or environment level causes inconsistent data and lost updates.
Note: This limitation only applies to Edge for Private Cloud. Edge for Public Cloud
and Hybrid do not have this limitation.
For a workaround in Edge for Private Cloud, create the KVM at the
apiproxy scope.
[[["Easy to understand","easyToUnderstand","thumb-up"],["Solved my problem","solvedMyProblem","thumb-up"],["Other","otherUp","thumb-up"]],[["Missing the information I need","missingTheInformationINeed","thumb-down"],["Too complicated / too many steps","tooComplicatedTooManySteps","thumb-down"],["Out of date","outOfDate","thumb-down"],["Samples / code issue","samplesCodeIssue","thumb-down"],["Other","otherDown","thumb-down"]],["Last updated 2026-02-02 UTC."],[],[]]

{kind=link}